File:Dahl et al 2012 Fig1.png
Jump to navigation
Jump to search
No higher resolution available.
Dahl_et_al_2012_Fig1.png (459 × 402 pixels, file size: 140 KB, MIME type: image/png)
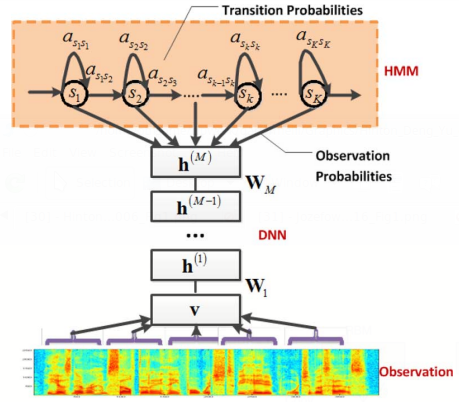
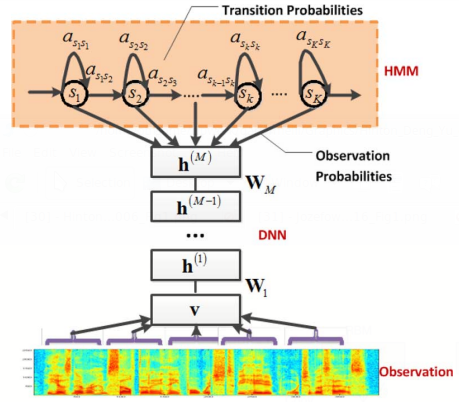
Fig. 1. Diagram of our hybrid architecture employing a deep neural network. The HMM models the sequential property of the speech signal, and the DNN models the scaled observation likelihood of all the senones (tied tri-phone states). The same DNN is replicated over different points in time. In: George E. Dahl, Dong Yu, Li Deng, and Alex Acero (2012). "Context-dependent pre-trained deep neural networks for large-vocabulary speech recognition." IEEE Transactions on audio, speech, and language processing 20.1 (2012): 30-42.
File history
Click on a date/time to view the file as it appeared at that time.
| Date/Time | Thumbnail | Dimensions | User | Comment | |
|---|---|---|---|---|---|
| current | 01:55, 13 August 2018 | | 459 × 402 (140 KB) | Omoreira (talk | contribs) | Fig. 1. Diagram of our hybrid architecture employing a deep neural network. The HMM models the sequential property of the speech signal, and the DNN models the scaled observation likelihood of all the senones (tied tri-phone sta... |
You cannot overwrite this file.
File usage
The following page uses this file:
{kind=link}