word2vec-like System
A word2vec-like System is a distributional word embedding training system that applies a word2vec algorithm (based on work by Tomáš Mikolov, Kai Chen, Greg Corrado, Jeffrey Dean, et al[1]).
- Context:
- It can train a word2vec Model Instance (that defines a word2vec model space).
- It can can require billions of words to train a good Word Embedding.
- It can have source code available at https://code.google.com/p/word2vec/source/checkout
- Example(s):
- the original release http://code.google.com/p/word2vec/
- Gensim's https://radimrehurek.com/gensim/models/word2vec.html
- Counter-Example(s):
- See: Bag-of-Words Representation, Word Context Vectors, Code2Vec, Code2Seq.
References
2021
- (TensorFlow, 2021) ⇒ https://www.tensorflow.org/tutorials/text/word2vec Retrieved:2021-05-09.
- QUOTE: Word2Vec is not a singular algorithm, rather, it is a family of model architectures and optimizations that can be used to learn word embeddings from large datasets. Embeddings learned through Word2Vec have proven to be successful on a variety of downstream natural language processing tasks.
2016
- (Colyer, 2016) ⇒ Adrian Colyer (2016). “The Amazing Power of Word Vectors". In: The Morning Paper.
- QUOTE: At one level, it’s simply a vector of weights. In a simple 1-of-N (or ‘one-hot’) encoding every element in the vector is associated with a word in the vocabulary. The encoding of a given word is simply the vector in which the corresponding element is set to one, and all other elements are zero.
Suppose our vocabulary has only five words:
King,Queen,Man,Woman, andChild. We could encode the word ‘Queen’ as:
- QUOTE: At one level, it’s simply a vector of weights. In a simple 1-of-N (or ‘one-hot’) encoding every element in the vector is associated with a word in the vocabulary. The encoding of a given word is simply the vector in which the corresponding element is set to one, and all other elements are zero.
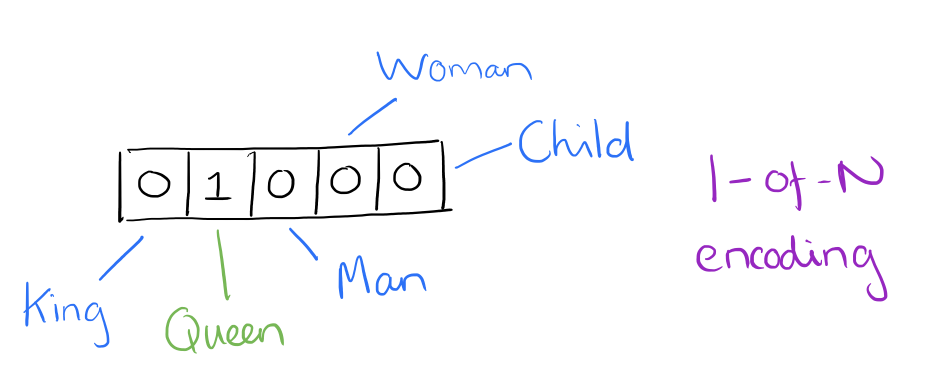
- Using such an encoding, there’s no meaningful comparison we can make between word vectors other than equality testing.
In word2vec, a distributed representation of a word is used. Take a vector with several hundred dimensions (say 1000). Each word is representated by a distribution of weights across those elements. So instead of a one-to-one mapping between an element in the vector and a word, the representation of a word is spread across all of the elements in the vector, and each element in the vector contributes to the definition of many words.
If I label the dimensions in a hypothetical word vector (there are no such pre-assigned labels in the algorithm of course), it might look a bit like this:
- Using such an encoding, there’s no meaningful comparison we can make between word vectors other than equality testing.
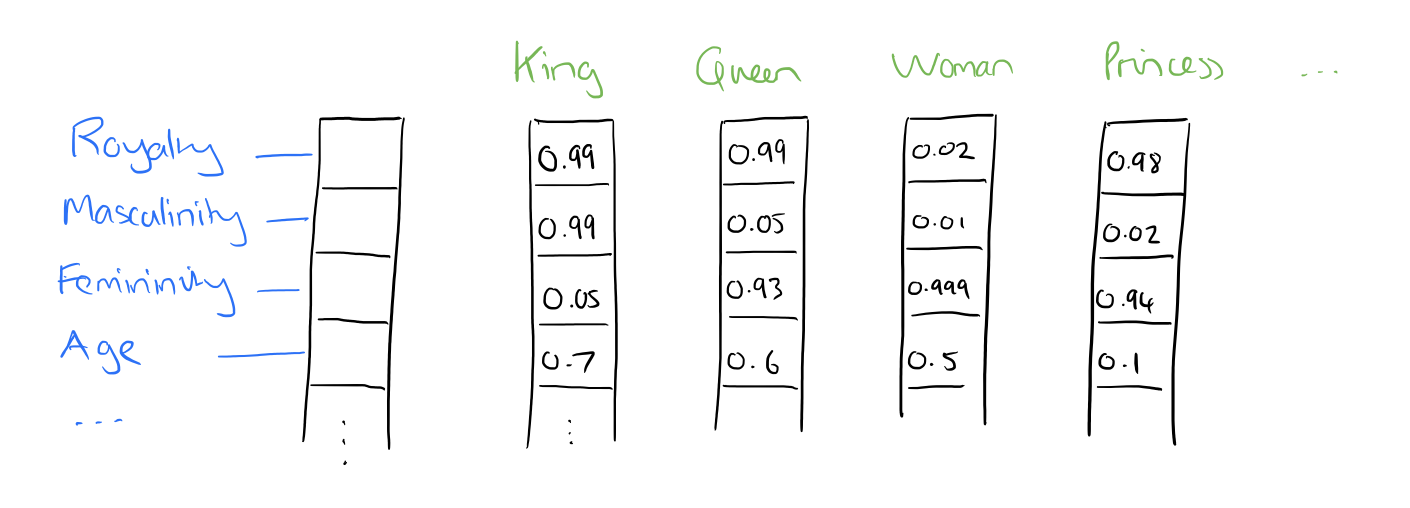
:: Such a vector comes to represent in some abstract way the ‘meaning’ of a word. And as we’ll see next, simply by examining a large corpus it’s possible to learn word vectors that are able to capture the relationships between words in a surprisingly expressive way. We can also use the vectors as inputs to a neural network.
2015
- (Rothe & Schütze, 2015) ⇒ Sascha Rothe, and Hinrich Schütze. (2015). “AutoExtend: Extending Word Embeddings to Embeddings for Synsets and Lexemes.” In: arXiv preprint arXiv:1507.01127.
- QUOTE: ... Unsupervised methods for word embeddings (also called “distributed word representations”) have become popular in natural language processing (NLP). These methods only need very large corpora as input to create sparse representations (e.g., based on local collocations) and project them into a lower dimensional dense vector space. Examples for word embeddings are SENNA (Collobert and Weston, 2008), the hierarchical log-bilinear model (Mnih and Hinton, 2009), word2vec (Mikolov et al., 2013c) and GloVe (Pennington et al., 2014).
2014
- Dec-23-2014 http://radimrehurek.com/2014/12/making-sense-of-word2vec/
- QUOTE: Tomáš Mikolov (together with his colleagues at Google) ... releasing word2vec, an unsupervised algorithm for learning the meaning behind words. ...
... Using large amounts of unannotated plain text, word2vec learns relationships between words automatically. The output are vectors, one vector per word, with remarkable linear relationships that allow us to do things like vec(“king”) – vec(“man”) + vec(“woman”) =~ vec(“queen”), or vec(“Montreal Canadiens”) – vec(“Montreal”) + vec(“Toronto”) resembles the vector for “Toronto Maple Leafs”. ...
... Basically, where GloVe precomputes the large word x word co-occurrence matrix in memory and then quickly factorizes it, word2vec sweeps through the sentences in an online fashion, handling each co-occurrence separately. So, there is a tradeoff between taking more memory (GloVe) vs. taking longer to train (word2vec). Also, once computed, GloVe can re-use the co-occurrence matrix to quickly factorize with any dimensionality, whereas word2vec has to be trained from scratch after changing its embedding dimensionality.
- QUOTE: Tomáš Mikolov (together with his colleagues at Google) ... releasing word2vec, an unsupervised algorithm for learning the meaning behind words. ...
2014
- (Rei & Briscoe, 2014) ⇒ Marek Rei, and Ted Briscoe. (2014). “Looking for Hyponyms in Vector Space.” In: Proceedings of CoNLL-2014.
- QUOTE: Word2vec: We created word representations using the word2vec toolkit[1]. The tool is based on a feedforward neural network language model, with modifications to make representation learning more efficient (Mikolov et al., 2013a). We make use of the skip-gram model, which takes each word in a sequence as an input to a log-linear classifier with a continuous projection layer, and predicts words within a certain range before and after the input word. The window size was set to 5 and vectors were trained with both 100 and 500 dimensions.
2013
- https://code.google.com/p/word2vec/
- This tool provides an efficient implementation of the continuous bag-of-words and skip-gram architectures for computing vector representations of words. These representations can be subsequently used in many natural language processing applications and for further research.
...
The word2vec tool takes a text corpus as input and produces the word vectors as output. It first constructs a vocabulary from the training text data and then learns vector representation of words. The resulting word vector file can be used as features in many natural language processing and machine learning applications.
A simple way to investigate the learned representations is to find the closest words for a user-specified word. The distance tool serves that purpose. For example, if you enter 'france', distance will display the most similar words and their distances to 'france', which should look like ...
- This tool provides an efficient implementation of the continuous bag-of-words and skip-gram architectures for computing vector representations of words. These representations can be subsequently used in many natural language processing applications and for further research.
2013b
- (Mikolov et al., 2013a) ⇒ Tomáš Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. (2013). “Efficient Estimation of Word Representations in Vector Space.” In: Proceedings of International Conference of Learning Representations Workshop.
2013a
- (Mikolov et al., 2013b) ⇒ Tomáš Mikolov, Wen-tau Yih, and Geoffrey Zweig. (2013). “Linguistic Regularities in Continuous Space Word Representations..” In: HLT-NAACL.