Convolutional-Pooling Neural Network (CNN/ConvNet) Model
A Convolutional-Pooling Neural Network (CNN/ConvNet) Model is a multi-layer feed-forward neural network that includes convolutional layers and pooling layers.
- AKA: Shift Invariant NNet, Space Invariant Artificial NNet (SIANN).
- Context:
- It can (typically) include Convolutional Layers and Pooling Layers.
- It can be represented by a CNN Architecture.
- It can be trained by a CNN Training System (that implements a CNN training algorithm to solve a CNN training task).
- It can (often) include Normalization Layers and Fully-Connected Layers;
- It can range from being a Shallow CNN to being a Deep CNN.
- …
- Example(s):
- a Temporal Convolutional Network,
- a Convolutional Deep Belief Network (CDBN),
- a Convolutional Neural Network with Attention Mechanism,
- a Deep Convolutional Neural Network (DCN),
- a Convolutional Network for Reinforcement Learning,
- a CNN Encoder-Decoder Neural Network,
- a Deep Convolutional Neural Netowrk such as: VGG Net, AlexNet, and GooLeNet,
- an Inception Architecture.
- …
- Counter-Example(s):
- See: Visual Field, Image Recognition, Vanishing Gradient Problem, Bidirectional LSTM-CNN.
References
2022
- (Liu, Mao et al., 2022) ⇒ Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, and Saining Xie. (2022). “A ConvNet for the 2020s.”
- QUOTE: ... The "Roaring 20s" of visual recognition began with the introduction of Vision Transformers (ViTs), which quickly superseded ConvNets as the state-of-the-art image classification model. A vanilla ViT, on the other hand, faces difficulties when applied to general computer vision tasks such as object detection and semantic segmentation. ...
... In this work, we reexamine the design spaces and test the limits of what a pure ConvNet can achieve. We gradually "modernize" a standard ResNet toward the design of a vision Transformer, and discover several key components that contribute to the performance difference along the way. The outcome of this exploration is a family of pure ConvNet models dubbed ConvNeXt. Constructed entirely from standard ConvNet modules, ConvNeXts compete favorably with Transformers in terms of accuracy and scalability, achieving 87.8% ImageNet top-1 accuracy and outperforming Swin Transformers on COCO detection and ADE20K segmentation, while maintaining the simplicity and efficiency of standard ConvNets.
- QUOTE: ... The "Roaring 20s" of visual recognition began with the introduction of Vision Transformers (ViTs), which quickly superseded ConvNets as the state-of-the-art image classification model. A vanilla ViT, on the other hand, faces difficulties when applied to general computer vision tasks such as object detection and semantic segmentation. ...
2018a
- (Wikipedia, 2018) ⇒ https://en.wikipedia.org/wiki/Convolutional_neural_network Retrieved:2018-2-25.
- In machine learning, a convolutional neural network (CNN, or ConvNet) is a class of deep, feed-forward artificial neural networks that has successfully been applied to analyzing visual imagery.
CNNs use a variation of multilayer perceptrons designed to require minimal preprocessing.[1] They are also known as shift invariant or space invariant artificial neural networks (SIANN), based on their shared-weights architecture and translation invariance characteristics. Zhang, Wei (1988). "Shift-invariant pattern recognition neural network and its optical architecture". Proceedings of annual conference of the Japan Society of Applied Physics.</ref> Zhang, Wei (1990). "Parallel distributed processing model with local space-invariant interconnections and its optical architecture". Applied Optics. 29 (32): 4790–7. Bibcode:1990ApOpt..29.4790Z. doi:10.1364/AO.29.004790. PMID 20577468.</ref>
Convolutional networks were inspired by biological processes[2] in which the connectivity pattern between neurons is inspired by the organization of the animal visual cortex. Individual cortical neurons respond to stimuli only in a restricted region of the visual field known as the receptive field. The receptive fields of different neurons partially overlap such that they cover the entire visual field.
CNNs use relatively little pre-processing compared to other image classification algorithms. This means that the network learns the filters that in traditional algorithms were hand-engineered. This independence from prior knowledge and human effort in feature design is a major advantage.
They have applications in image and video recognition, recommender systems and natural language processing.
- In machine learning, a convolutional neural network (CNN, or ConvNet) is a class of deep, feed-forward artificial neural networks that has successfully been applied to analyzing visual imagery.
2018b
- (Wikipedia, 2018) ⇒ https://en.wikipedia.org/wiki/Deep_learning#Deep_neural_networks Retrieved:2018-8-12.
- … Convolutional deep neural networks (CNNs) are used in computer vision (LeCun et al., 1998). CNNs also have been applied to acoustic modeling for automatic speech recognition (ASR; Sainath et al., 2013).
2017a
- (Gibson & Patterson, 2017) ⇒ Adam Gibson, Josh Patterson (2017). "Chapter 4. Major Architectures of Deep Networks". In: "Deep Learning" ISBN: 9781491924570.
- QUOTE: CNNs transform the input data from the input layer through all connected layers into a set of class scores given by the output layer. There are many variations of the CNN architecture, but they are based on the pattern of layers, as demonstrated in Figure 4-9.
Figure 4-9 depicts three major groups:
- QUOTE: CNNs transform the input data from the input layer through all connected layers into a set of class scores given by the output layer. There are many variations of the CNN architecture, but they are based on the pattern of layers, as demonstrated in Figure 4-9.
- The input layer accepts three-dimensional input generally in the form spatially of the size (width × height) of the image and has a depth representing the color channels (generally three for RGB color channels).
The feature-extraction layers have a general repeating pattern of the sequence:
- Convolution layer
We express the Rectified Linear Unit (ReLU) activation function as a layer in the diagram here to match up to other literature.
- Pooling layer
- Convolution layer
- These layers find a number of features in the images and progressively construct higher-order features. This corresponds directly to the ongoing theme in deep learning by which features are automatically learned as opposed to traditionally hand engineered.
Finally we have the classification layers in which we have one or more fully connected layers to take the higher-order features and produce class probabilities or scores. These layers are fully connected to all of the neurons in the previous layer, as their name implies. The output of these layers produces typically a two-dimensional output of the dimensions [b × N], where b is the number of examples in the mini-batch and N is the number of classes we’re interested in scoring.
Figure 4-9. High-level general CNN architecture
2017
- (Parashar et al., 2017) ⇒ Angshuman Parashar, Minsoo Rhu, Anurag Mukkara, Antonio Puglielli, Rangharajan Venkatesan, Brucek Khailany, Joel Emer, Stephen W Keckler, and William J Dally. (2017). “SCNN: An Accelerator for Compressed-sparse Convolutional Neural Networks.” In: ACM SIGARCH Computer Architecture News, 45(2).
- QUOTE: ... Convolutional neural networks (CNNs) have become the most popular algorithmic approach for deep learning for many of these domains. Employing CNNs can be decomposed into two tasks: (1) training — in which the parameters of a neural network are learned by observing massive numbers of training examples, and (2) inference — in which a trained neural network is deployed in the field and classifies the observed data. Today, training is often done on GPUs [24] or farms of GPUs, while inference depends on the application and can employ CPUs, GPUs, FPGA, or specially-built ASICs. …
2016
- (Shelhamer, Long & Darrell, 2016) ⇒ Evan Shelhamer, Jonathan Long, and Trevor Darrell (2016). "Fully convolutional networks for semantic segmentation". arXiv preprint arXiv:1605.06211.
- ABSTRACT: Convolutional networks are powerful visual models that yield hierarchies of features. We show that convolutional networks by themselves, trained end-to-end, pixels-to-pixels, improve on the previous best result in semantic segmentation. Our key insight is to build "fully convolutional" networks that take input of arbitrary size and produce correspondingly-sized output with efficient inference and learning. We define and detail the space of fully convolutional networks, explain their application to spatially dense prediction tasks, and draw connections to prior models. We adapt contemporary classification networks (AlexNet, the VGG net, and GoogLeNet) into fully convolutional networks and transfer their learned representations by fine-tuning to the segmentation task. We then define a skip architecture that combines semantic information from a deep, coarse layer with appearance information from a shallow, fine layer to produce accurate and detailed segmentations. Our fully convolutional network achieves improved segmentation of PASCAL VOC (30% relative improvement to 67.2% mean IU on 2012), NYUDv2, SIFT Flow, and PASCAL-Context, while inference takes one tenth of a second for a typical image.
2015
- (Liang & Hu, 2015) ⇒ Ming Liang, and Xiaolin Hu. (2015). “Recurrent Convolutional Neural Network for Object Recognition.” In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 3367-3375.
- QUOTE: ... CNN is a type of artificial neural network, which originates from neuroscience dating back to the proposal of the first artificial neuron in 1943 [34]. In fact, CNN, as well as other hierarchical models including Neocognitron [13] and HMAX [38], is closely related to Hubel and Wiesel’s findings about simple cells and complex cells in the primary visual cortex (V1)[23, 22]. All of these models have purely feed-forward architectures, which can be viewed as crude approximations of the biological neural network in the brain. Anatomical evidences have shown that recurrent connections ubiquitously exist in the neocortex, and recurrent synapses typically outnumber feed-forward and top-down (or feedback) synapses [6]. …
2013a
- (VistaLab, 2013) ⇒ (2013) An Introduction to Convolutional Neural Networks. In: VISTA LabTeaching WIKI
- QUOTE: The solution to FFNNs' problems with image processing took inspiration from neurobiology, Yann LeCun and Toshua Bengio tried to capture the organization of neurons in the visual cortex of the cat, which at that time was known to consist of maps of local receptive fields that decreased in granularity as the cortex moved anteriorly. There are several different theory about how to precisely define such a model, but all of the various implementations can be loosely described as involving the following process:
- Convolve several small filters on the input image
- Subsample this space of filter activations
- Repeat steps 1 and 2 until your left with sufficiently high level features.
- Use a standard a standard FFNN to solve a particular task, using the results features as input.
- QUOTE: The solution to FFNNs' problems with image processing took inspiration from neurobiology, Yann LeCun and Toshua Bengio tried to capture the organization of neurons in the visual cortex of the cat, which at that time was known to consist of maps of local receptive fields that decreased in granularity as the cortex moved anteriorly. There are several different theory about how to precisely define such a model, but all of the various implementations can be loosely described as involving the following process:
- The LeCun Formulation
There are several different ways one might formalize the high level process described above, but the most common is LeCun's implementation, the LeNet (...)

The complete implementation of the LeNet.
- The LeCun Formulation
2013b
- (DeepLearning Tutorial, 2013) ⇒ Theano Development Team (2008–2013). Convolutional Neural Networks (LeNet) In: DeepLearning 0.1 documentation
- QUOTE: Convolutional Neural Networks (CNN) are variants of MLPs which are inspired from biology. From Hubel and Wiesel’s early work on the cat’s visual cortex [Hubel68], we know there exists a complex arrangement of cells within the visual cortex. These cells are sensitive to small sub-regions of the input space, called a receptive field, and are tiled in such a way as to cover the entire visual field. These filters are local in input space and are thus better suited to exploit the strong spatially local correlation present in natural images.
Additionally, two basic cell types have been identified: simple cells (S) and complex cells (C). Simple cells (S) respond maximally to specific edge-like stimulus patterns within their receptive field. Complex cells (C) have larger receptive fields and are locally invariant to the exact position of the stimulus.
The visual cortex being the most powerful “vision” system in existence, it seems natural to emulate its behavior. Many such neurally inspired models can be found in the literature. To name a few: the NeoCognitron Fukushima, HMAX Serre07 and LeNet-5 LeCun98, which will be the focus of this tutorial.
- QUOTE: Convolutional Neural Networks (CNN) are variants of MLPs which are inspired from biology. From Hubel and Wiesel’s early work on the cat’s visual cortex [Hubel68], we know there exists a complex arrangement of cells within the visual cortex. These cells are sensitive to small sub-regions of the input space, called a receptive field, and are tiled in such a way as to cover the entire visual field. These filters are local in input space and are thus better suited to exploit the strong spatially local correlation present in natural images.
2009
- (Lee et al., 2009) ⇒ Honglak Lee, Roger Grosse, Rajesh Ranganath, and Andrew Y. Ng. (2009). “Convolutional Deep Belief Networks for Scalable Unsupervised Learning of Hierarchical Representations.” In: Proceedings of the 26th Annual International Conference on Machine Learning (ICML 2009). ISBN:978-1-60558-516-1 doi:10.1145/1553374.1553453
- QUOTE: Finally, we are ready to define the convolutional deep belief network (CDBN), our hierarchical generative model for full-sized images. Analogously to DBNs, this architecture consists of several max-pooling-CRBMs stacked on top of one another. The network defines an energy function by summing together the energy functions for all of the individual pairs of layers. Training is accomplished with the same greedy, layer-wise procedure described in Section 2.2: once a given layer is trained, its weights are frozen, and its activations are used as input to the next layer.
2007
- (Serre et al.,2007) ⇒ Serre, T., Wolf, L., Bileschi, S., Riesenhuber, M., & Poggio, T. (2007). "Robust object recognition with cortex-like mechanisms". IEEE transactions on pattern analysis and machine intelligence, 29(3), 411-426. DOI: 10.1109/TPAMI.2007.56
- ABSTRACT: We introduce a new general framework for the recognition of complex visual scenes, which is motivated by biology: We describe a hierarchical system that closely follows the organization of visual cortex and builds an increasingly complex and invariant feature representation by alternating between a template matching and a maximum pooling operation. We demonstrate the strength of the approach on a range of recognition tasks: From invariant single object recognition in clutter to multiclass categorization problems and complex scene understanding tasks that rely on the recognition of both shape-based as well as texture-based objects. Given the biological constraints that the system had to satisfy, the approach performs surprisingly well: It has the capability of learning from only a few training examples and competes with state-of-the-art systems. We also discuss the existence of a universal, redundant dictionary of features that could handle the recognition of most object categories. In addition to its relevance for computer vision, the success of this approach suggests a plausibility proof for a class of feedforward models of object recognition in cortex
2006
- (Simard et al., 2006) ⇒ Patrice Y. Simard, Dave Steinkraus, and John C. Platt. (2003). "Best Practices for Convolutional Neural Networks Applied to Visual Document Analysis." (PDF) In: 12th International Conference on Document Analysis and Recognition.
- QUOTE: The general strategy of a convolutional network is to extract simple features at a higher resolution, and then convert them into more complex features at a coarser resolution. The simplest was to generate coarser resolution is to sub-sample a layer by a factor of 2. This, in turn, is a clue to the convolutions kernel's size.
1998
- (LeCun et al., 1998) ⇒ Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. (1998). “Gradient-based Learning Applied to Document Recognition.” (PDF) Proceedings of the IEEE 86, no. 11
- ABSTRACT: Multilayer neural networks trained with the back-propagation algorithm constitute the best example of a successful gradient based learning technique. Given an appropriate network architecture, gradient-based learning algorithms can be used to synthesize a complex decision surface that can classify high-dimensional patterns, such as handwritten characters, with minimal preprocessing. This paper reviews various methods applied to handwritten character recognition and compares them on a standard handwritten digit recognition task. Convolutional neural networks, which are specifically designed to deal with the variability of 2D shapes, are shown to outperform all other techniques. Real-life document recognition systems are composed of multiple modules including field extraction, segmentation recognition, and language modeling. A new learning paradigm, called graph transformer networks (GTN), allows such multimodule systems to be trained globally using gradient-based methods so as to minimize an overall performance measure. Two systems for online handwriting recognition are described. Experiments demonstrate the advantage of global training, and the flexibility of graph transformer networks. A graph transformer network for reading a bank cheque is also described. It uses convolutional neural network character recognizers combined with global training techniques to provide record accuracy on business and personal cheques. It is deployed commercially and reads several million cheques per day.
1997
- (Lawrence et al., 1997) ⇒ Steve Lawrence, C. Lee Giles, Ah Chung Tsoi, and Andrew D. Back. (1997). "Face Recognition: A convolutional neural-network approach." (PDF) Neural Networks, IEEE Transactions, 8(1).
- QUOTE: A typical convolutional network is shown in Fig. 5 [3]. The network consists of a set of layers each of which contains one or more planes. Approximately centered and normalized images enter at the input layer. Each unit in a plane receives input from a small neighborhood in the planes of the previous layer. The idea of connecting units to local receptive fields dates back to the 1960’s with the perceptron and Hubel and Wiesel’s [4] discovery of locally sensitive orientation selective neurons in the cat’s visual system [5]. The weights forming the receptive field for a plane are forced to be equal at all points in the plane. Each plane can be considered as a feature map which has a fixed feature detector that is convolved with a local window which is scanned over the planes in the previous layer. Multiple planes are usually used in each layer so that multiple features can be detected. These layers are called convolutional layers. Once a feature has been detected, its exact location is less important. Hence, the convolutional layers are typically followed by another layer which does a local averaging and subsampling operation (...)
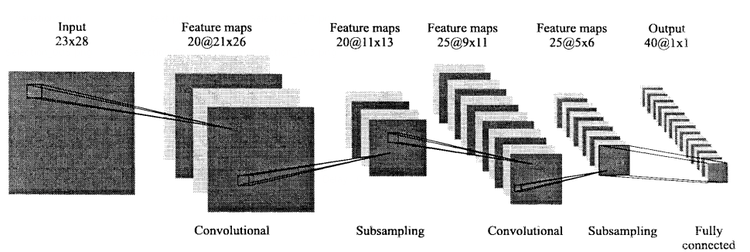
Fig. 5. A typical convolutional network
- QUOTE: A typical convolutional network is shown in Fig. 5 [3]. The network consists of a set of layers each of which contains one or more planes. Approximately centered and normalized images enter at the input layer. Each unit in a plane receives input from a small neighborhood in the planes of the previous layer. The idea of connecting units to local receptive fields dates back to the 1960’s with the perceptron and Hubel and Wiesel’s [4] discovery of locally sensitive orientation selective neurons in the cat’s visual system [5]. The weights forming the receptive field for a plane are forced to be equal at all points in the plane. Each plane can be considered as a feature map which has a fixed feature detector that is convolved with a local window which is scanned over the planes in the previous layer. Multiple planes are usually used in each layer so that multiple features can be detected. These layers are called convolutional layers. Once a feature has been detected, its exact location is less important. Hence, the convolutional layers are typically followed by another layer which does a local averaging and subsampling operation (...)

1980
- (Fukushima, 1980) ⇒ Fukushima, K. Biol. "Neocognitron: A self-organizing neural network model for a mechanism of visual pattern recognition". Cybernetics (1980) 36: 193. Spring DOI: 10.1007/BF00344251.
- ABSTRACT: A neural network model for a mechanism of visual pattern recognition is proposed in this paper. The network is self-organized by “learning without a teacher”, and acquires an ability to recognize stimulus patterns based on the geometrical similarity (Gestalt) of their shapes without affected by their positions. This network is given a nickname “neocognitron”. After completion of self-organization, the network has a structure similar to the hierarchy model of the visual nervous system proposed by Hubel and Wiesel. The network consists of an input layer (photoreceptor array) followed by a cascade connection of a number of modular structures, each of which is composed of two layers of cells connected in a cascade. The first layer of each module consists of “S-cells”, which show characteristics similar to simple cells or lower order hypercomplex cells, and the second layer consists of “C-cells” similar to complex cells or higher order hypercomplex cells. The afferent synapses to each S-cell have plasticity and are modifiable. The network has an ability of unsupervised learning: We do not need any “teacher” during the process of self-organization, and it is only needed to present a set of stimulus patterns repeatedly to the input layer of the network. The network has been simulated on a digital computer. After repetitive presentation of a set of stimulus patterns, each stimulus pattern has become to elicit an output only from one of the C-cell of the last layer, and conversely, this C-cell has become selectively responsive only to that stimulus pattern. That is, none of the C-cells of the last layer responds to more than one stimulus pattern. The response of the C-cells of the last layer is not affected by the pattern's position at all. Neither is it affected by a small change in shape nor in size of the stimulus pattern.
- ↑ LeCun, Yann. "LeNet-5, convolutional neural networks". Retrieved 16 November 2013.
- ↑ Matusugu, Masakazu; Katsuhiko Mori; Yusuke Mitari; Yuji Kaneda (2003). "Subject independent facial expression recognition with robust face detection using a convolutional neural network" (PDF). Neural Networks. 16 (5): 555–559. doi:10.1016/S0893-6080(03)00115-1. Retrieved 17 November 2013.
- ↑ Y. Le Cun, B. Boser, J. S. Denker, D. Henderson, R. Howard, W. Hubbard, and L. Jackel, “Handwritten digit recognition with a backpropagation neural network.” in Advances in Neural Information Processing Systems 2, D. S. Touretzky, Ed. San Mateo, CA: Morgan Kaufmann, 1990, pp. 396–404.
- ↑ D. H. Hubel and T. N. Wiesel, “Receptive fields, binocular interaction, and functional architecture in the cat’s visual cortex.” J. Physiol., vol. 160, pp. 106–154, 1962.
- ↑ Y. Le Cun and Y. Bengio, “Convolutional networks for images, speech, and time series.” in The Handbook of Brain Theory and Neural Networks, M. A. Arbib, Ed. Cambridge, MA: MIT Press, 1995, pp. 255–258.