sklearn.neural network Module
An sklearn.neural network Module is a neural network framework that is an sklearn module (which contains a collection of neural network algorithm implementations).
- Context:
- It can (often) reference a sklearn.neural network system, such as by:
sklearn.neural network.Model_Name(self, arguments)or simplysklearn.neural network.Model_Name()(whereModel_Nameis a neural network algorithm).
- It can (often) reference a sklearn.neural network system, such as by:
- Example(s)
- Counter-Example(s):
- PyTorch.
- Keras.
- TensorFlow.
- MXNet.
sklearn.tree, a collection of Decision Tree Learning Systems.sklearn.svm, a collection of Support Vector Machine algorithms.
- See: Multilayer Perceptron (MLP) Training,
sklearn.metrics,sklearn.covariance,sklearn.cluster.bicluster,sklearn.linear_model,sklearn.manifold.
References
2017a
- (Scikit Learn, 2017) ⇒ http://scikit-learn.org/stable/modules/classes.html#module-sklearn.neural_network Retrieved: 2017-12-17
- QUOTE: The sklearn.neural_network module includes models based on neural networks.
User guide: See the Neural network models (supervised) and Neural network models (unsupervised) sections for further details.
neural_network.BernoulliRBM([n_components, …])Bernoulli Restricted Boltzmann Machine (RBM).neural_network.MLPClassifier([…])Multi-layer Perceptron classifier.neural_network.MLPRegressor([…])Multi-layer Perceptron regressor.
- QUOTE: The sklearn.neural_network module includes models based on neural networks.
2017b
- (sklearn,2017) ⇒ http://scikit-learn.org/stable/modules/neural_networks_supervised.html#multi-layer-perceptron Retrieved:2017-12-3.
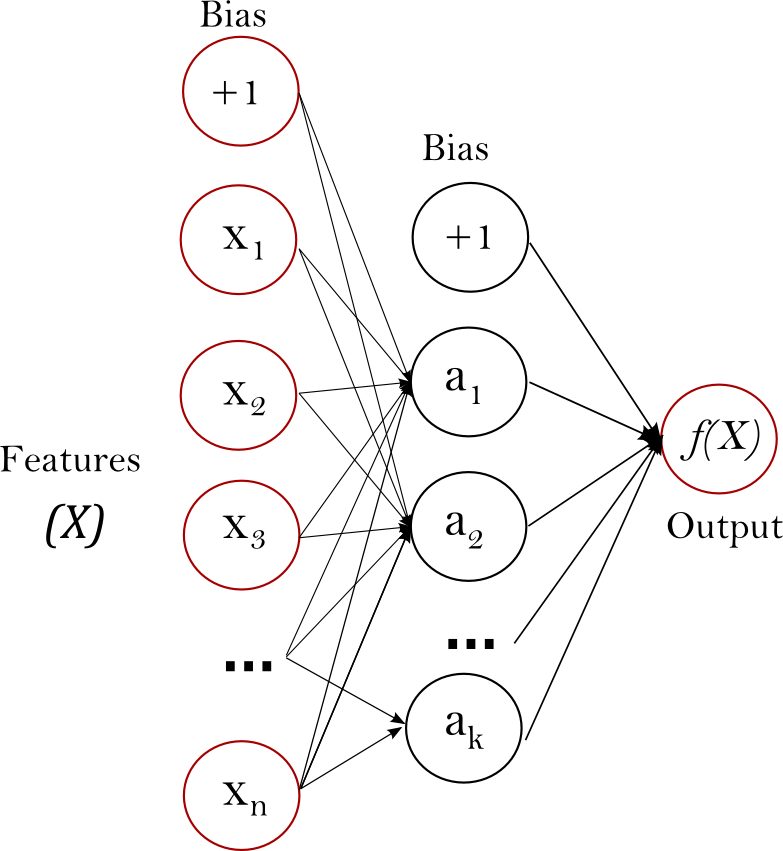
- QUOTE: Multi-layer Perceptron (MLP) is a supervised learning algorithm that learns a function [math]\displaystyle{ f(\cdot): R^m \rightarrow R^o }[/math] by training on a dataset, where [math]\displaystyle{ m }[/math] is the number of dimensions for input and [math]\displaystyle{ o }[/math] is the number of dimensions for output. Given a set of features [math]\displaystyle{ X = {x_1, x_2, \cdots, x_m} }[/math] and a target [math]\displaystyle{ y }[/math], it can learn a non-linear function approximator for either classification or regression. It is different from logistic regression, in that between the input and the output layer, there can be one or more non-linear layers, called hidden layers. Figure 1 shows a one hidden layer MLP with scalar output.
The leftmost layer, known as the input layer, consists of a set of neurons [math]\displaystyle{ \{x_i | x_1, x_2, \cdots, x_m\} }[/math] representing the input features. Each neuron in the hidden layer transforms the values from the previous layer with a weighted linear summation [math]\displaystyle{ w_1x_1 + w_2x_2 + \cdots + w_mx_m }[/math], followed by a non-linear activation function [math]\displaystyle{ g(\cdot):R \rightarrow R - }[/math] like the hyperbolic tan function. The output layer receives the values from the last hidden layer and transforms them into output values.
The module contains the public attributes
coefs_andintercepts_.coefs_is a list of weight matrices, where weight matrix at index [math]\displaystyle{ i }[/math] represents the weights between layer [math]\displaystyle{ i }[/math] and layer [math]\displaystyle{ i+1 }[/math].intercepts_is a list of bias vectors, where the vector at index [math]\displaystyle{ i }[/math] represents the bias values added to layer [math]\displaystyle{ i+1 }[/math].The advantages of Multi-layer Perceptron are:
- Capability to learn non-linear models.
- Capability to learn models in real-time (on-line learning) using
partial_fit.
- QUOTE: Multi-layer Perceptron (MLP) is a supervised learning algorithm that learns a function [math]\displaystyle{ f(\cdot): R^m \rightarrow R^o }[/math] by training on a dataset, where [math]\displaystyle{ m }[/math] is the number of dimensions for input and [math]\displaystyle{ o }[/math] is the number of dimensions for output. Given a set of features [math]\displaystyle{ X = {x_1, x_2, \cdots, x_m} }[/math] and a target [math]\displaystyle{ y }[/math], it can learn a non-linear function approximator for either classification or regression. It is different from logistic regression, in that between the input and the output layer, there can be one or more non-linear layers, called hidden layers. Figure 1 shows a one hidden layer MLP with scalar output.
{kind=link}
- The disadvantages of Multi-layer Perceptron (MLP) include:
- MLP with hidden layers have a non-convex loss function where there exists more than one local minimum. Therefore different random weight initializations can lead to different validation accuracy.
- MLP requires tuning a number of hyperparameters such as the number of hidden neurons, layers, and iterations.
- MLP is sensitive to feature scaling.
- The disadvantages of Multi-layer Perceptron (MLP) include:
2017c
- (sklearn,2017) ⇒ http://scikit-learn.org/stable/modules/neural_networks_unsupervised.html#neural-networks-unsupervised Retrieved:2017-12-17
- QUOTE: Restricted Boltzmann machines (RBM) are unsupervised nonlinear feature learners based on a probabilistic model. The features extracted by an RBM or a hierarchy of RBMs often give good results when fed into a linear classifier such as a linear SVM or a perceptron.
The model makes assumptions regarding the distribution of inputs. At the moment, scikit-learn only provides BernoulliRBM, which assumes the inputs are either binary values or values between 0 and 1, each encoding the probability that the specific feature would be turned on.
The RBM tries to maximize the likelihood of the data using a particular graphical model. The parameter learning algorithm used (Stochastic Maximum Likelihood) prevents the representations from straying far from the input data, which makes them capture interesting regularities, but makes the model less useful for small datasets, and usually not useful for density estimation.
The method gained popularity for initializing deep neural networks with the weights of independent RBMs. This method is known as unsupervised pre-training.
- QUOTE: Restricted Boltzmann machines (RBM) are unsupervised nonlinear feature learners based on a probabilistic model. The features extracted by an RBM or a hierarchy of RBMs often give good results when fed into a linear classifier such as a linear SVM or a perceptron.