File:2018 AMultilayerConvolutionalEncoder Fig2.png
Jump to navigation
Jump to search
Size of this preview: 800 × 395 pixels. Other resolution: 971 × 479 pixels.
{kind=link}
Original file (971 × 479 pixels, file size: 72 KB, MIME type: image/png)
Summary
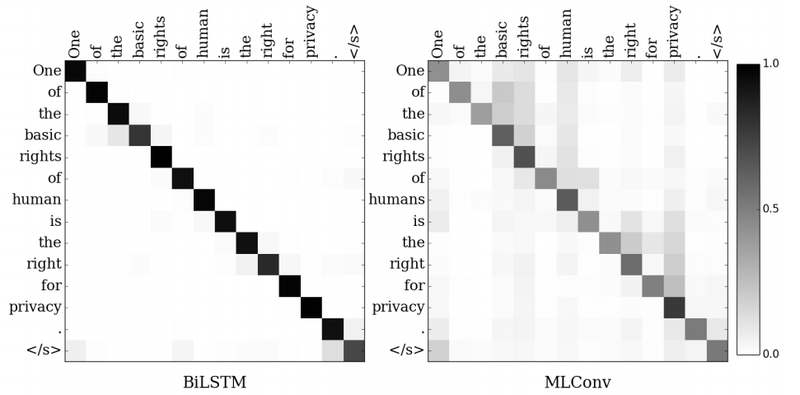
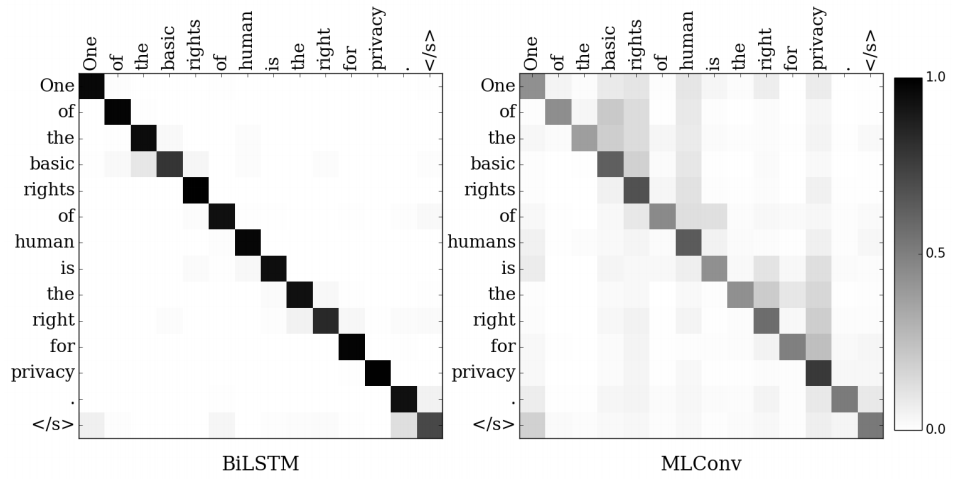
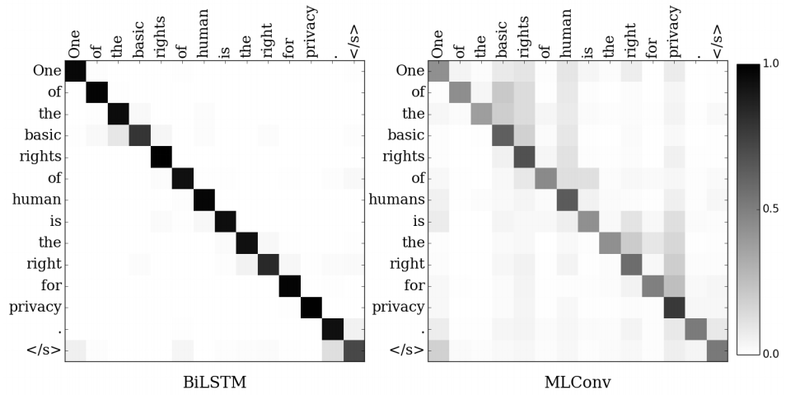
Figure 2: Visualization of attention weights of BiLSTM and MLConv models. y-axis shows the target words and x-axis shows the source words. In: Chollampatt & Ng (2018).
File history
Click on a date/time to view the file as it appeared at that time.
| Date/Time | Thumbnail | Dimensions | User | Comment | |
|---|---|---|---|---|---|
| current | 08:48, 17 July 2019 | | 971 × 479 (72 KB) | Omoreira (talk | contribs) | '''Figure 2:''' Visualization of attention weights of BiLSTM and MLConv models. y-axis shows the target words and x-axis shows the source words. In: Chollampatt & Ng (2018). |
You cannot overwrite this file.
File usage
The following page uses this file:
{kind=link}