File:Hinton Deng Yu et al 2012 Fig1.png
{kind=link}
Original file (955 × 465 pixels, file size: 34 KB, MIME type: image/png)
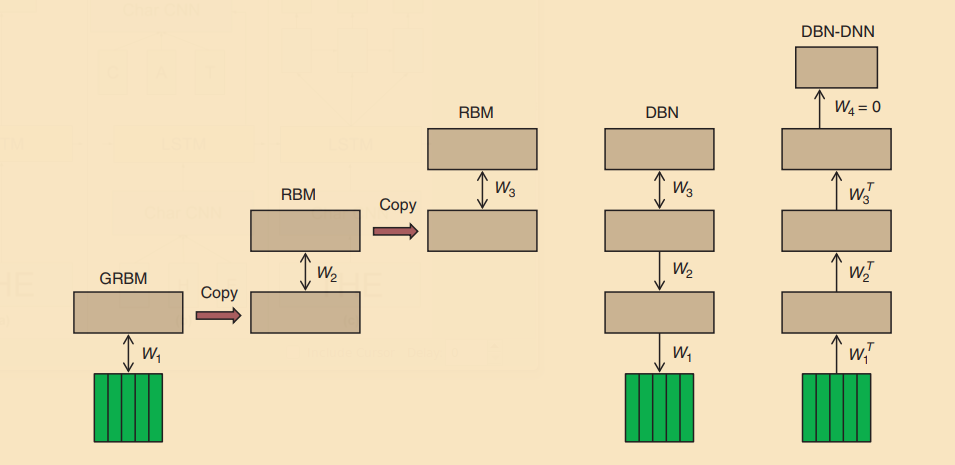
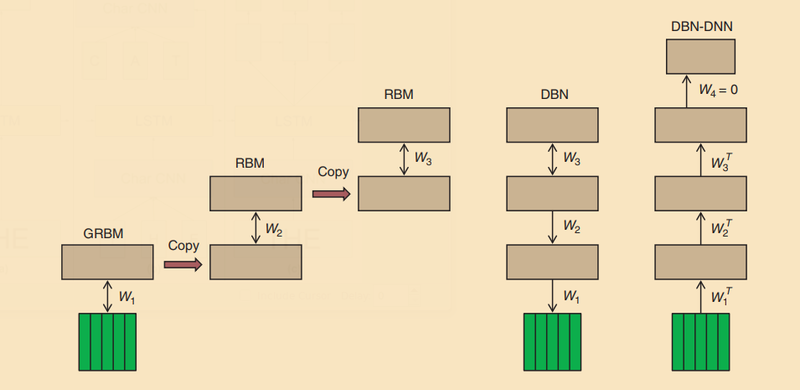
[FIG1] The sequence of operations used to create a DBN with three hidden layers and to convert it to a pretrained DBN-DNN. First, a GRBM is trained to model a window of frames of real-valued acoustic coefficients. Then the states of the binary hidden units of the GRBM are used as data for training an RBM. This is repeated to create as many hidden layers as desired. Then the stack of RBMs is converted to a single generative model, a DBN, by replacing the undirected connections of the lower level RBMs by top-down, directed connections. Finally, a pretrained DBN-DNN is created by adding a “softmax” output layer that contains one unit for each possible state of each HMM. The DBN-DNN is then discriminatively trained to predict the HMM state corresponding to the central frame of the input window in a forced alignment.
In: Geoffrey Hinton, Li Deng, Dong Yu, George E. Dahl, Abdel-rahman Mohamed, Navdeep Jaitly, Andrew Senior et al. (2012). "Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups". IEEE Signal processing magazine, 29(6), 82-97.
File history
Click on a date/time to view the file as it appeared at that time.
| Date/Time | Thumbnail | Dimensions | User | Comment | |
|---|---|---|---|---|---|
| current | 01:24, 13 August 2018 | | 955 × 465 (34 KB) | Omoreira (talk | contribs) | [FIG1] The sequence of operations used to create a DBN with three hidden layers and to convert it to a pretrained DBN-DNN. First, a GRBM is trained to model a window of frames of [[real-valued acoustic co... |
You cannot overwrite this file.
File usage
The following page uses this file:
{kind=link}