Parquet File Format
A Parquet File Format is a columnar file format that supports nested data.
- Context:
- It is a self-describing, open-source, and language independent file format.
- It is managed by an Apache Parquet-Format Project (that defines Parquet files).
- It can (typically) be written by a Parquet File Writer.
- It can (typically) be read by a Parquet File Reader.
- It can (typically) use dict and runlength encoding optimizations
- It can (typically) be optimized for a Record Shredding and Assembly Algorithm (e.g. as described in the Dremel paper).
- It can (typically) be used for Write Once Read Many (WORM) Tasks.
- It can by a Parquet Supporting System, such as: Apache Hadoop, Apache Drill, Apache Hive, Apache Impala, Apache Spark, ...
- It can be a Compressed Parquet File Format (for a compressed Parquet file).
- Example(s):
- parquet-1.9.0[1] (2016-10-18).
- parquet-1.8.2[2] (2017-01-18).
- parquet-1.5.0[3] (2014-05-21).
- parquet-1.2.0 …
- https://github.com/apache/parquet-mr/releases
- Counter-Example(s):
- See: HDFS File, Apache Thrift, Column-Oriented DBMS.
References
2021a
- (Apache Software Foundation 2021) ⇒ https://parquet.apache.org/ Retrieved:2021-04-04.
- QUOTE: Apache Parquet is a columnar storage format available to any project in the Hadoop ecosystem, regardless of the choice of data processing framework, data model or programming language.
2021b
- (GitHub, 2021) ⇒ https://github.com/apache/parquet-format Retrieved:2021-04-04.
- QUOTE: Parquet is a columnar storage format that supports nested data.
Parquet metadata is encoded using Apache Thrift.
The Parquet-format project contains all Thrift definitions that are necessary to create readers and writers for Parquet files.
- QUOTE: Parquet is a columnar storage format that supports nested data.
2021c
- (Confluence, 2021) ⇒ https://cwiki.apache.org/confluence/display/Hive/Parquet Retrieved:2021-04-04.
- QUOTE: Parquet (http://parquet.io/) is an ecosystem wide columnar format for Hadoop. Read Dremel made simple with Parquet for a good introduction to the format while the Parquet project has an in-depth description of the format including motivations and diagrams. At the time of this writing Parquet supports the follow engines and data description languages:(...)
2019
- https://stackoverflow.com/a/56481636
- QUOTE: ... Parquet is a columnar file format for data serialization. Reading a Parquet file requires decompressing and decoding its contents into some kind of in-memory data structure. It is designed to be space/IO-efficient at the expense of CPU utilization for decoding. It does not provide any data structures for in-memory computing. Parquet is a streaming format which must be decoded from start-to-end, while some "index page" facilities have been added to the storage format recently, in general random access operations are costly. ...
2017a
- https://parquet.apache.org/
- QUOTE: Apache Parquet is a columnar storage format available to any project in the Hadoop ecosystem, regardless of the choice of data processing framework, data model or programming language.
2017b
- https://arrow.apache.org/docs/python/parquet.html
- QUOTE: The Apache Parquet project provides a standardized open-source columnar storage format for use in data analysis systems. It was created originally for use in Apache Hadoop with systems like Apache Drill, Apache Hive, Apache Impala (incubating), and Apache Spark adopting it as a shared standard for high performance data IO.
Apache Arrow is an ideal in-memory transport layer for data that is being read or written with Parquet files. We have been concurrently developing the C++ implementation of Apache Parquet, which includes a native, multithreaded C++ adapter to and from in-memory Arrow data. PyArrow includes Python bindings to this code, which thus enables reading and writing Parquet files with pandas as well.
- QUOTE: The Apache Parquet project provides a standardized open-source columnar storage format for use in data analysis systems. It was created originally for use in Apache Hadoop with systems like Apache Drill, Apache Hive, Apache Impala (incubating), and Apache Spark adopting it as a shared standard for high performance data IO.
2017c
- https://parquet.apache.org/documentation/latest/
- QUOTE: We created Parquet to make the advantages of compressed, efficient columnar data representation available to any project in the Hadoop ecosystem.
Parquet is built from the ground up with complex nested data structures in mind, and uses the record shredding and assembly algorithm described in the Dremel paper. We believe this approach is superior to simple flattening of nested name spaces.
Parquet is built to support very efficient compression and encoding schemes. Multiple projects have demonstrated the performance impact of applying the right compression and encoding scheme to the data. Parquet allows compression schemes to be specified on a per-column level, and is future-proofed to allow adding more encodings as they are invented and implemented.
Parquet is built to be used by anyone. The Hadoop ecosystem is rich with data processing frameworks, and we are not interested in playing favorites. We believe that an efficient, well-implemented columnar storage substrate should be useful to all frameworks without the cost of extensive and difficult to set up dependencies.
- QUOTE: We created Parquet to make the advantages of compressed, efficient columnar data representation available to any project in the Hadoop ecosystem.
2017d
- https://github.com/Parquet/parquet-format#File%20format
- QUOTE: This file and the thrift definition should be read together to understand the format.
4-byte magic number "PAR1" <Column 1 Chunk 1 + Column Metadata> <Column 2 Chunk 1 + Column Metadata> ... <Column N Chunk 1 + Column Metadata> <Column 1 Chunk 2 + Column Metadata> <Column 2 Chunk 2 + Column Metadata> ... <Column N Chunk 2 + Column Metadata> ... <Column 1 Chunk M + Column Metadata> <Column 2 Chunk M + Column Metadata> ... <Column N Chunk M + Column Metadata> File Metadata 4-byte length in bytes of file metadata 4-byte magic number "PAR1"
2017 e.
- http://garrens.com/blog/2017/10/09/spark-file-format-showdown-csv-vs-json-vs-parquet/
- QUOTE: Apache Spark supports many different data sources, such as the ubiquitous Comma Separated Value (CSV) format and web API friendly JavaScript Object Notation (JSON) format. A common format used primarily for big data analytical purposes is Apache Parquet. ...
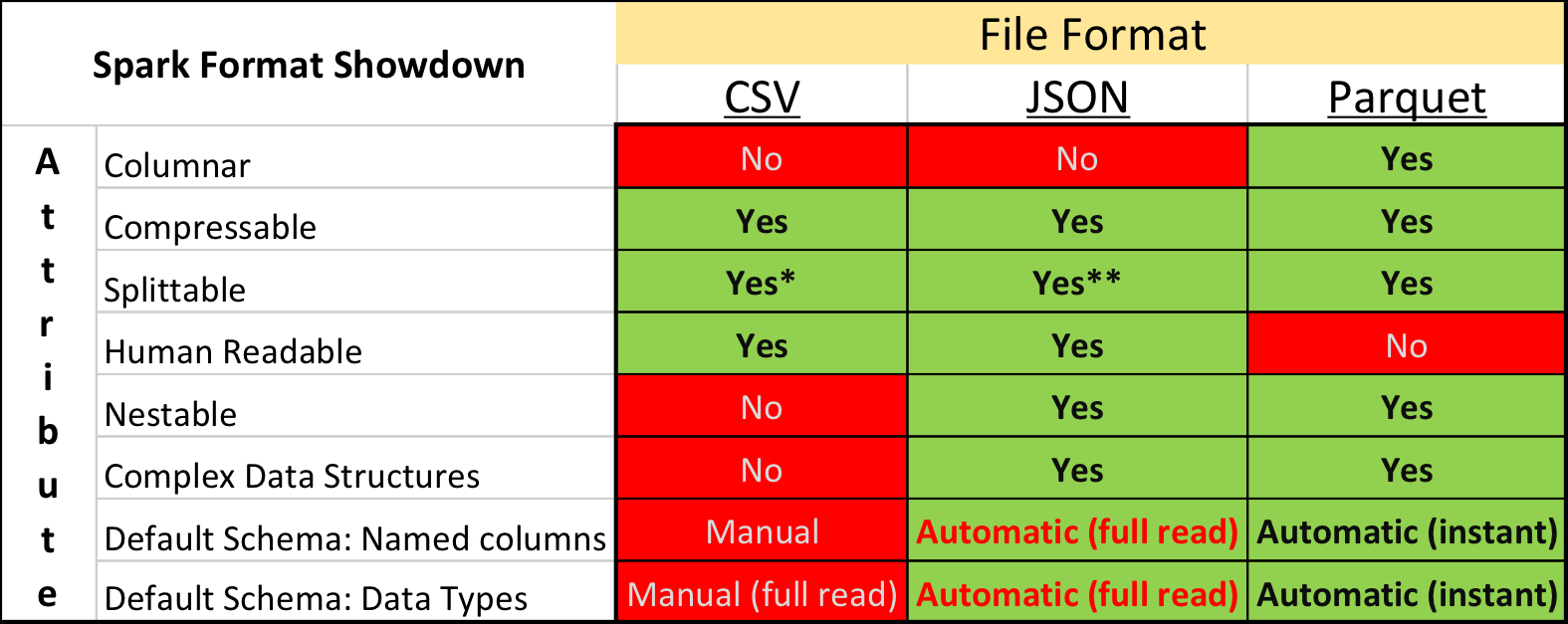
- QUOTE: Apache Spark supports many different data sources, such as the ubiquitous Comma Separated Value (CSV) format and web API friendly JavaScript Object Notation (JSON) format. A common format used primarily for big data analytical purposes is Apache Parquet. ...
2016b
- https://github.com/Parquet/parquet-format
- QUOTE: Parquet is a columnar storage format that supports nested data.
Parquet metadata is encoded using Apache Thrift. The Parquet-format project contains all Thrift definitions that are necessary to create readers and writers for Parquet files.
- We created Parquet to make the advantages of compressed, efficient columnar data representation available to any project in the Hadoop ecosystem.
Parquet is built from the ground up with complex nested data structures in mind, and uses the record shredding and assembly algorithm described in the Dremel paper. We believe this approach is superior to simple flattening of nested name spaces.
Parquet is built to support very efficient compression and encoding schemes. Multiple projects have demonstrated the performance impact of applying the right compression and encoding scheme to the data. Parquet allows compression schemes to be specified on a per-column level, and is future-proofed to allow adding more encodings as they are invented and implemented.
Parquet is built to be used by anyone. The Hadoop ecosystem is rich with data processing frameworks, and we are not interested in playing favorites. We believe that an efficient, well-implemented columnar storage substrate should be useful to all frameworks without the cost of extensive and difficult to set up dependencies.
- QUOTE: Parquet is a columnar storage format that supports nested data.
2016
- Ryan Blue. (2016). “Parquet performance tuning - the missing guide." Presentation
- QUOTE: Topics include:
- The tools and techniques Netflix uses to analyze Parquet tables
- How to spot common problems
- Recommendations for Parquet configuration settings to get the best performance out of your processing platform
- The impact of this work in speeding up applications like Netflix’s telemetry service and A/B testing platform
- …
- Spark configuration.
- // turn on Parquet push-down, stats filtering, and dictionary filtering
- sqlContext.setConf("parquet.filter.statistics.enabled", "true")
- sqlContext.setConf("parquet.filter.dictionary.enabled", "true")
- sqlContext.setConf("spark.sql.parquet.filterPushdown", "true")
- …
- QUOTE: Topics include:
2010
- (Melnik et al., 2010) ⇒ Sergey Melnik, Andrey Gubarev, Jing Jing Long, Geoffrey Romer, Shiva Shivakumar, Matt Tolton, and Theo Vassilakis. (2010). “Dremel: Interactive Analysis of Web-scale Datasets.” In: Proceedings of the VLDB Endowment Journal, 3(1-2). doi:10.14778/1920841.1920886