Randomized Leaky Rectified Linear Activation (RLReLU) Function
A Randomized Leaky Rectified Linear Activation (RLReLU) Function is a leaky rectified-based activation function that is based on [math]\displaystyle{ f(x)=max(0,x)+\alpha∗min(0,x) }[/math], where [math]\displaystyle{ \alpha }[/math] is a random variable.
- Context:
- It can (typically) be used in the activation of Parametric Rectified Linear Neurons.
- Example(s):
- Counter-Example(s):
- a Clipped Rectifier Unit Activation Function,
- a Concatenated Rectified Linear Activation Function,
- an Exponential Linear Activation Function,
- a Leaky Rectified Linear Activation Function,
- a Noisy Rectified Linear Activation Function,
- a Parametric Rectified Linear Activation Function,
- a Scaled Exponential Linear Activation Function,
- a Softplus Activation Function,
- a S-shaped Rectified Linear Activation Function.
- See: Artificial Neural Network, Artificial Neuron, Neural Network Topology, Neural Network Layer, Neural Network Learning Rate.
References
2017a
- (Mate Labs, 2017) ⇒ Mate Labs Aug 23, 2017. Secret Sauce behind the beauty of Deep Learning: Beginners guide to Activation Functions
- QUOTE: Randomized Leaky Rectified Linear Unit(RReLU)
Range:[math]\displaystyle{ (-\infty, +\infty) }[/math]
[math]\displaystyle{ f(\alpha, x) = \begin{cases} \alpha x, & \mbox{for } x < 0 \\ x, & \mbox{for } x \geq 0 \end{cases} }[/math]

- QUOTE: Randomized Leaky Rectified Linear Unit(RReLU)
2017b
- (Lipman, 2017) ⇒ Lipman (2017) [http://laid.delanover.com/informal-review-on-randomized-leaky-relu-rrelu-in-tensorflow/
- This very informal review of the activation function RReLU compares the performance of the same network (with and without batch normalization) using different activation functions: ReLU, LReLU, PReLU, ELU and an less famous RReLU. The difference between them lies on their behavior from [math]\displaystyle{ [- \infty,0] }[/math]. The goal of this entry is not to explain in detail these activation functions, but to provide a short description.
When a negative value arises, ReLU deactivates the neuron by setting a 0 value whereas LReLU, PReLU and RReLU allow a small negative value. In contrast, ELU has a smooth curve around the zero to make it derivable resulting in a more natural gradient and instead of deactivating the neuron negative values are mapped into a negative one. The authors claim that this pushes the mean unit closer to zero, like batch normalization [1].
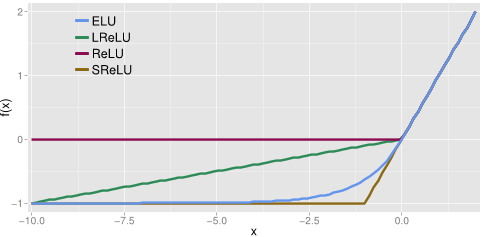
LReLU, PReLU and RReLU provide with negative values in the negative part of the respective functions. LReLU is using a small tilted slope whereas PReLU learns the steepness of this slope. On the other hand, RReLU, the function we will study here, sets this slope to be a random value between an upper and lower bound during the training and an average of these bounds during the testing. The authors of the original paper get their inspiration from Kaggle competition and even use the same values [2]. These are random values between 3 and 8 during the training and a fixed value 5.5 during testing.
- This very informal review of the activation function RReLU compares the performance of the same network (with and without batch normalization) using different activation functions: ReLU, LReLU, PReLU, ELU and an less famous RReLU. The difference between them lies on their behavior from [math]\displaystyle{ [- \infty,0] }[/math]. The goal of this entry is not to explain in detail these activation functions, but to provide a short description.
2017c
- (Goldberg, 2017) ⇒ Yoav Goldberg. (2017). “Neural Network Methods for Natural Language Processing.” In: Synthesis Lectures on Human Language Technologies, 10(1). doi:10.2200/S00762ED1V01Y201703HLT037
- QUOTE: ... Layers with tanh and sigmoid activations can become saturated — resulting in output values for that layer that are all close to one, the upper-limit of the activation function. Saturated neurons have very small gradients, and should be avoided. Layers with the ReLU activation cannot be saturated, but can “die” — most or all values are negative and thus clipped at zero for all inputs, resulting in a gradient of zero for that layer. ...
2015
- (Xu et al., 2015) ⇒ Bing Xu, Naiyan Wang, Tianqi Chen, and Mu Li. (2015). Empirical Evaluation of Rectified Activations in Convolutional Network. arXiv preprint arXiv:1505.00853.
- ABSTRACT: In this paper we investigate the performance of different types of rectified activation functions in convolutional neural network: standard rectified linear unit (ReLU), leaky rectified linear unit (Leaky ReLU), parametric rectified linear unit (PReLU) and a new randomized leaky rectified linear units (RReLU). We evaluate these activation function on standard image classification task. Our experiments suggest that incorporating a non-zero slope for negative part in rectified activation units could consistently improve the results. Thus our findings are negative on the common belief that sparsity is the key of good performance in ReLU. Moreover, on small scale dataset, using deterministic negative slope or learning it are both prone to overfitting. They are not as effective as using their randomized counterpart. By using RReLU, we achieved 75.68\% accuracy on CIFAR-100 test set without multiple test or ensemble.
** QUOTE: ... Randomized Leaky Rectified Linear is the randomized version of leaky ReLU. It is first proposed and used in Kaggle NDSB Competition. The highlight of RReLU is that in training process, aji is a random number sampled from a uniform distribution U (l, u). ...
- ABSTRACT: In this paper we investigate the performance of different types of rectified activation functions in convolutional neural network: standard rectified linear unit (ReLU), leaky rectified linear unit (Leaky ReLU), parametric rectified linear unit (PReLU) and a new randomized leaky rectified linear units (RReLU). We evaluate these activation function on standard image classification task. Our experiments suggest that incorporating a non-zero slope for negative part in rectified activation units could consistently improve the results. Thus our findings are negative on the common belief that sparsity is the key of good performance in ReLU. Moreover, on small scale dataset, using deterministic negative slope or learning it are both prone to overfitting. They are not as effective as using their randomized counterpart. By using RReLU, we achieved 75.68\% accuracy on CIFAR-100 test set without multiple test or ensemble.