2014 OutlierDetectionforTemporalDataA
- (Gupta et al., 2014a) ⇒ Madhu Gupta, Jing Gao, Charu C Aggarwal, and Jiawei Han. (2014). “Outlier Detection for Temporal Data: A Survey.” In: Knowledge and Data Engineering, IEEE Transactions on, 26(9).
Subject Headings: Temporal Outlier Detection.
Notes
- a tutorial related to this paper can be found at https://www.siam.org/meetings/sdm13/gupta.pdf
Cited By
Quotes
Author Keywords
- Temporal outlier detection; applications of temporal outlier detection; data streams; distributed data streams; network outliers; spatio-temporal outliers; temporal networks; time series data
Abstract
In the statistics community, outlier detection for time series data has been studied for decades. Recently, with advances in hardware and software technology, there has been a large body of work on temporal outlier detection from a computational perspective within the computer science community. In particular, advances in hardware technology have enabled the availability of various forms of temporal data collection mechanisms, and advances in software technology have enabled a variety of data management mechanisms. This has fueled the growth of different kinds of data sets such as data streams, spatio-temporal data, distributed streams, temporal networks, and time series data, generated by a multitude of applications. There arises a need for an organized and detailed study of the work done in the area of outlier detection with respect to such temporal datasets. In this survey, we provide a comprehensive and structured overview of a large set of interesting outlier definitions for various forms of temporal data, novel techniques, and application scenarios in which specific definitions and techniques have been widely used.
1. Introduction
Outlier detection is a broad field, which has been studied in the context of a large number of application domains. Aggarwal [1], Chandola et al. [2], Hodge et al. [3] and Zhang et al. [4] provide an extensive overview of outlier detection techniques. Outlier detection has been studied in a variety of data domains including high-dimensional data [5], uncertain data [6], streaming data [7], [8], [9], network data [9], [10], [11], [12], [13] and time series data [14], [15]. Outlier detection is very popular in industrial applications, and therefore many software tools have been built for efficient outlier detection, such as R (packages ‘outliers’1 and ‘outlierD’ [16]), SAS2, RapidMiner3, and Oracle datamine4.
1 http://cran.r-project.org/web/packages/outliers/outliers.pdf 2 http://www.nesug.org/Proceedings/nesug10/ad/ad07.pdf 3 http://www.youtube.com/watch?v=C1KNb1Kw-As 4 http://docs.oracle.com/cd/B28359 01/datamine.111/b28129/anomalies.htm
The different data domains in outlier analysis typically require dedicated techniques of different types. Temporal outlier analysis examines anomalies in the behavior of the data across time. Some motivating examples are as follows.
- Financial Markets: An abrupt change in the stock market, or an unusual pattern within a specific window such as the flash crash of May 6, 2010 is an anomalous event which needs to be detected early in order to avoid and prevent extensive disruption of markets because of possible weaknesses in trading systems.
- System Diagnosis: A significant amount of data generated about the system state is discrete in nature. This could correspond to UNIX system calls, aircraft system states, mechanical systems, or host-based intrusion detection systems. The last case is particularly common, and is an important research area in its own right. Anomalies provide information about potentially threatening and failure events in such systems.
� Biological Data: While biological data is not temporal in nature, the placement of individual amino-acids is analogous to positions in temporal sequences. Therefore, temporal methods can be directly used for biological data.
� User-action Sequences: A variety of sequences abound in daily life, which are created by user actions in different domains. These include web browsing patterns, customer transactions, or RFID sequences. Anomalies provide an idea of user-behavior which is deviant for specific reasons (e.g., an attempt to crack a password will contain a sequence of login and password actions).
This broad diversity in applications is also reflected in the diverse formulations and data types relevant to outlier detection. A common characteristic of all temporal outlier analysis is that temporal continuity plays a key role in all these formulations, and unusual changes, sequences, or temporal patterns in the data are used in order to model outliers. In this sense, time forms the contextual variable with respect to which all analysis is performed. Temporal outlier analysis is closely related to change point detection, and event detection, since these problems represent two instantiations of a much broader field. The problem of forecasting is closely related to many forms of temporal outlier analysis, since outliers are often defined as deviations from expected values (or forecasts). Nevertheless, while forecasting is a useful tool for many forms of outlier analysis, the broader area seems to be much richer and multi-faceted.
- Different Facets of Temporal Outlier Analysis
- Outlier analysis problems in temporal data may be categorized in a wide variety of ways, which represent different facets of the analysis. The area is so rich that no single type of abstract categorization can fully capture the complexity of the problems in the area, since these different facets may be present in an arbitrary combination. Some of these facets are as follows.
- Time-series vs Multidimensional Data Facet: In timeseries data (e.g., sensor readings) the importance of temporal continuity is paramount, and all analysis is performed with careful use of reasonably small windows of time (the contextual variable). On the other hand, in a multi-dimensional data stream such as a text newswire stream, an application such as first-story detection, might not rely heavily on the temporal aspect, and thus the methods are much closer to standard multidimensional outlier analysis.
- The Point vs Window Facet: Are we looking for an unusual data point in a temporal series (e.g., sudden jump in heart rate in ECG reading), or are we looking for an unusual pattern of changes (contiguous ECG pattern indicative of arrythmia)? The latter scenario is usually far more challenging than the former. Even in the context of a multi-dimensional data stream, a single point deviant (e.g., first story in a newswire stream) may be considered a different kind of outlier than an aggregate change point (e.g., sudden change in the aggregate distribution of stories over successive windows).
- The Data Type Facet: Different kinds of data such as continuous series (e.g., sensors), discrete series (e.g., web logs), multi-dimensional streams (e.g., text streams), or network data (e.g., graph and social streams) require different kinds of dedicated methods for analysis.
- The supervision facet: Are previous examples of anomalies available? This facet is of course common to all forms of outlier analysis, and is not specific to the temporal scenario. These different facets are largely independent of one another, and a large number of problem formulations are possible with the use of a combination of these different facets. Therefore, this paper is largely organized by the facet of data type, and examines different kinds of scenarios along this broad organization.
- Specific Challenges for Outlier Detection for Temporal Data
- While temporal outlier detection aims to find rare and interesting instances, as in the case of traditional outlier detection, new challenges arise due to the nature of temporal data. We list them below.
� A wide variety of anomaly models are possible depending upon the specific data type and scenario. This leads to diverse formulations, which need to be designed for the specific problem. For arbitrary applications, it may often not be possible to use off-the-shelf models, because of the wide variations in problem formulations. This is one of the motivating reasons for this survey to provide an overview of the most common combinations of facets explored in temporal outlier analysis.
� Since new data arrives at every time instant, the scale of the data is very large. This often leads to processing and resource-constraint challenges. In the streaming scenario, only a single scan is allowed. Traditional outlier detection is much easier, since it is typically an offline task.
� Outlier detection for temporal data in distributed scenarios poses significant challenges of minimizing communication overhead and computational load in resource-constrained environments.
In this work, we aim to provide a comprehensive and structured overview of outlier detection techniques for temporal data. Figure 1 shows the organization of the survey with respect to the data type facet. For each data type, we discuss specific problem classes in various subsections. We begin with the easiest scenario for temporal data – discrete time series data (Section 2). However a lot of data gets sampled over very short time intervals, and keeps flowing in infinitely leading to data streams. We will study techniques for outlier detection in streams in Section 3. Often times, data is distributed across multiple locations. We study how to extract global outliers in such distributed scenarios in Section 4. For some applications like environmental data analysis, data is available over a continuum of both space and time dimensions. We will study techniques to handle such data in Section 5. Finally, networks can capture very rich semantics for almost every domain. Hence, we will discuss outlier detection mechanisms for network data in Section 6. We will also present a few applications where such temporal outlier detection techniques have been successfully employed in Section 7. The conclusions are presented in Section 8.
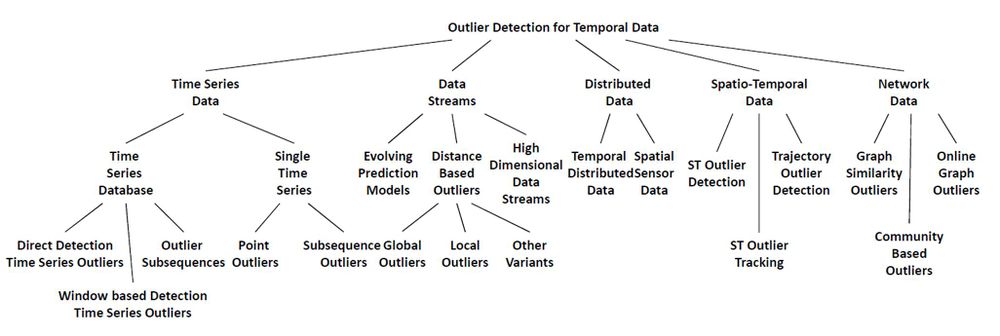 Fig. 1. Organization of the Survey
Fig. 1. Organization of the Survey

2. Time Series Outlier Detection
A significant amount of work has been performed in the area of time series outliers. Parametric models for time series outliers [15] represents the first work on outlier detection for time series data. Several models were subsequently proposed in the statistics literature, including autoregressive moving average (ARMA), autoregressive integrated moving average (ARIMA), vector autoregression (VARMA), CUmulative SUM Statistics (CUSUM), exponentially weighted moving average, etc. While a detailed exposition is beyond the scope of this survey, we will provide an overview of the key ideas in this topic, especially from a computer science perspective. We direct the reader to [ 17], [ 18], [ 19 ] for further reading from the statistics point of view. In this section, we will focus on two main types of outlier detection techniques for time series studied in the data mining community. The first part concerns techniques to detect outliers over a database of time series, whereas the second part deals with outliers within a single time series.
2.1 Outliers in Time Series Databases
Given a time series database, we will discuss methods to identify a few time series sequences as outliers, or to identify a subsequence in a test sequence as an outlier. An outlier score for a time series can be computed directly, or by first computing scores for overlapping fixed size windows and then aggregating them. We discuss these techniques in this subsection.
2.1.1 Direct Detection of Outlier Time Series
Given: A database of time series Find: All anomalous time series
It is assumed that most of the time series in the database are normal while a few are anomalous. Similar to traditional outlier detection, the usual recipe for solving such problems is to first learn a model based on all the time series sequences in the database, and then compute an outlier score for each sequence with respect to the model. The model could be supervised or unsupervised depending on the availability of training data.
- Unsupervised Discriminative Approaches
Discriminative approaches rely on the definition of a similarity function that measures the similarity between two sequences. Once a similarity function is defined, such approaches cluster the sequences, such that within-cluster similarity is maximized, while between-cluster similarity is minimized. The anomaly score of a test time series sequence is defined as the distance to the centroid (or medoid) of the closest cluster. The primary variation across such approaches, are the choice of the similarity measure, and the clustering mechanism.
- Similarity Measures
The most popular sequence similarity measures are the simple match count based sequence similarity [20], and the normalized length of the longest common subsequence (LCS) [21], [22], [23], [24]. The advantage of the former is its greater computational efficiency, whereas the latter can adjust to segments in the sequences containing noise, but is more expensive because of its dynamic programming methodology.
- Clustering Methods
Popular clustering methods include k-Means [25], EM [26], phased k-Means [27], dynamic clustering [24], k-medoids [21], [22], singlelinkage clustering [28], clustering of multi-variate time series in the principal components space [29], oneclass SVM [30], [31], [32], [33] and self-organizing maps [34]. The choice of the clustering method is application-specific, because different clustering methods have different complexity, with varying adaptability to clusters of different numbers, shapes and sizes.
- Unsupervised Parametric Approaches
In unsupervised parametric approaches, anomalous instances are not specified, and a summary model is constructed on the base data. A test sequence is then marked anomalous if the probability of generation of the sequence from the model is very low. The anomaly score for the entire time series is computed in terms of the probability of each element. Popular models include Finite state automata (FSA), Markov models and Hidden Markov Models (HMMs).
FSA can be learned from length l subsequences in normal training data. During testing, all length l subsequences can be extracted from a test time series and fed into the FSA. An anomaly is then detected if the FSA reaches a state from where there is no outgoing edge corresponding to the last symbol of the current subsequence. FSAs have been used for outlier detection in [23], [35], [36], [37]. The methods to generate the state transition rules depend on particular application domains.
Some Markov methods store conditional information for a fixed history size=k, while others use a variable history size to capture richer temporal dependencies. Ye [38] proposes a technique where a Markov model with k=1 is used. In [39], [40], the conditional probability distribution (CPD) are stored in probabilistic suffix trees (PSTs) for efficient computations. Sparse Markovian techniques estimate the conditional probability of an element based on symbols within the previous k symbols, which may not be contiguous or immediately preceding to the element [41], [42]. HMMs can be viewed as temporal dependencyoriented mixture models, where hidden states and transitions are used to model temporal dependencies among mixture components. HMMs do not scale well to real life datasets. The training process may require judicious selection of the model, the parameters, and initialization values of the parameters. On the other hand, HMMs are interpretable and theoretically well motivated. Approaches that use HMMs for outlier detection include [23], [43], [44], [45], [46].
- Unsupervised OLAP based Approach
Besides traditional uni-variate time series data, richer time series are quite popular. For example, a time series database may contain a set of time series, each of which are associated with multi-dimensional attributes. Thus, the database can be represented using an OLAP cube, where the time series could be associated with each cell as a measure. Li et al. [47] define anomalies in such a setting, where given a probe cell c, a descendant cell is considered an anomaly if the trend, magnitude or the phase of its associated time series are significantly different from the expected value, using the time series for the probe cell c.
- Supervised Approaches
In the presence of labeled training data, the following supervised approaches have been proposed in the literature: positional system calls features with the RIPPER classifier [48], subsequences of positive and negative strings of behavior as features with string matching classifier [34], [49], neural networks [50], [51], [52], [53], [54], Elman network [53], motion features with SVMs [55], bag of system calls features with decision tree, Na¨ive Bayes, SVMs [56]. Sliding window subsequences have also been used as features with SVMs [57], [58], rule based classifiers [59], and HMMs [44].
…
References
;
| Author | volume | Date Value | title | type | journal | titleUrl | doi | note | year | |
|---|---|---|---|---|---|---|---|---|---|---|
| 2014 OutlierDetectionforTemporalDataA | Jing Gao Charu C. Aggarwal Madhu Gupta Jiawei Han | Outlier Detection for Temporal Data: A Survey | 2014 |