2017 SegNetADeepConvolutionalEncoder
- (Badrinarayanan et al., 2017) ⇒ Vijay Badrinarayanan, Alex Kendall, and Roberto Cipolla. (2017). “SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation.” In: IEEE Transactions on Pattern Analysis and Machine Intelligence, 39(12). doi:10.1109/TPAMI.2016.2644615
Subject Headings: Neural Encoder-Decoder Network; Convolutional Encoder-Decoder Neural Network, SegNet.
Notes
- Article Versions and URLs:
- First Pre-Print Published in 2015 by ArXiv: 1511.00561.
- DBLP Computer Science Bibliography: BadrinarayananK17. BadrinarayananK15.
- CiteSeer: doi=10.1.1.700.5503.
- University Of Cambridge Repository: 1810/271007.
Cited By
Quotes
Abstract
We present a novel and practical deep fully convolutional neural network architecture for semantic pixel-wise segmentation termed SegNet. This core trainable segmentation engine consists of an encoder network, a corresponding decoder network followed by a pixel-wise classification layer. The architecture of the encoder network is topologically identical to the 13 convolutional layers in the VGG16 network. The role of the decoder network is to map the low resolution encoder feature maps to full input resolution feature maps for pixel-wise classification. The novelty of SegNet lies is in the manner in which the decoder upsamples its lower resolution input feature map(s). Specifically, the decoder uses pooling indices computed in the max-pooling step of the corresponding encoder to perform non-linear upsampling. This eliminates the need for learning to upsample. The ppupsampled map]]s are sparse and are then convolved with trainable filters to produce dense feature maps. We compare our proposed architecture with the widely adopted FCN and also with the well known DeepLab-LargeFOV, DeconvNet architectures. This comparison reveals the memory versus accuracy trade-off involved in achieving good segmentation performance. SegNet was primarily motivated by scene understanding applications. Hence, it is designed to be efficient both in terms of memory and computational time during inference. It is also significantly smaller in the number of trainable parameters than other competing architectures. We also performed a controlled benchmark of SegNet and other architectures on both road scenes and SUN RGB-D indoor scene segmentation tasks. We show that SegNet provides good performance with competitive inference time and more efficient inference memory-wise as compared to other architectures. We also provide a Caffe implementation of SegNet and a web demo at http://mi.eng.cam.ac.uk/projects/segnet/.
1 Introduction
2 Literature Review
3 Architecture
SegNet has an encoder network and a corresponding decoder network, followed by a final pixelwise classification layer. This architecture is illustrated in Fig. 2. The encoder network consists of 13 convolutional layers which correspond to the first 13 convolutional layers in the VGG16 network (Simonyan & Zisserman, 2014) designed for object classification. We can therefore initialize the training process from weights trained for classification on large datasets (Russakovsky, 2015) . We can also discard the fully connected layers in favour of retaining higher resolution feature maps at the deepest encoder output. This also reduces the number of parameters in the SegNet encoder network significantly (from 134 to 14.7 M) as compared to other recent architectures (Long et al., 2015; Noh et al., 2015) (see. Table 6). Each encoder layer has a corresponding decoder layer and hence the decoder network has 13 layers. The final decoder output is fed to a multi-class soft-max classifier to produce class probabilities for each pixel independently.
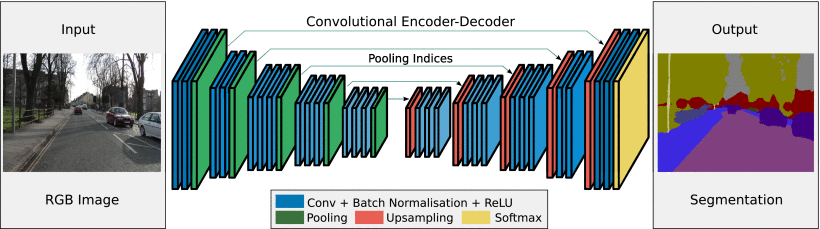
Figure 2. An illustration of the SegNet architecture. There are no fully connected layers and hence it is only convolutional. A decoder upsamples its input using the transferred pool indices from its encoder to produce a sparse feature map(s). It then performs convolution with a trainable filter bank to densify the feature map. The final decoder output feature maps are fed to a soft-max classifier for pixel-wise classification.
=== 4 Benchmarking ===
5 Discussion and Future Work
References
;
| Author | volume | Date Value | title | type | journal | titleUrl | doi | note | year | |
|---|---|---|---|---|---|---|---|---|---|---|
| 2017 SegNetADeepConvolutionalEncoder | Vijay Badrinarayanan Alex Kendall Roberto Cipolla | SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation | 10.1109/TPAMI.2016.2644615 | 2017 |