Convolutional (CNN/CNN)-based Encoder-Decoder Neural Network
A Convolutional (CNN/CNN)-based Encoder-Decoder Neural Network is a spatial hierarchical encoder-decoder neural network that can support spatial transformation tasks through convolutional encoding-decoding architectures.
- AKA: CNN Encoder-Decoder Network, Convolutional Encoder-Decoder Network, CNN-based Encoder-Decoder, Conv Encoder-Decoder.
- Context:
- It can typically extract Hierarchical Spatial Features through convolutional encoder layers with pooling operations.
- It can typically reconstruct Spatial Outputs through convolutional decoder layers with upsampling operations.
- It can typically preserve Spatial Locality through convolutional filter operations in both convolutional encoder modules and convolutional decoder modules.
- It can typically enable End-to-End Spatial Mapping from input spatial representations to output spatial representations.
- It can typically support Multi-Scale Feature Processing through hierarchical convolutional architectures.
- ...
- It can often incorporate Skip Connections between convolutional encoder layers and convolutional decoder layers for fine-grained detail preservation.
- It can often utilize Pooling Index Preservation to maintain spatial correspondence during convolutional upsampling processes.
- It can often implement Dilated Convolutions to increase receptive field size without losing spatial resolution.
- It can often employ Attention Mechanisms to focus on relevant spatial regions during convolutional transformation.
- ...
- It can range from being a Simple Convolutional Encoder-Decoder Neural Network to being a Complex Convolutional Encoder-Decoder Neural Network, depending on its convolutional architectural depth.
- It can range from being a Symmetric Convolutional Encoder-Decoder Neural Network to being an Asymmetric Convolutional Encoder-Decoder Neural Network, depending on its convolutional encoder-decoder balance.
- It can range from being a Single-Scale Convolutional Encoder-Decoder Neural Network to being a Multi-Scale Convolutional Encoder-Decoder Neural Network, depending on its convolutional feature resolution handling.
- ...
- It can be trained by Convolutional Encoder-Decoder Training Systems implementing convolutional encoder-decoder training algorithms.
- It can be optimized through Convolutional Weight Sharing across spatial dimensions.
- It can be regularized using Convolutional Dropout and Batch Normalization in convolutional encoder-decoder layers.
- It can be evaluated using Spatial Evaluation Metrics such as IoU scores and pixel accuracy measures.
- It can be deployed in Real-Time Convolutional Processing Systems for online spatial transformation.
- ...
- Example(s):
- Image Segmentation Convolutional Encoder-Decoder Architectures, such as:
- Medical Image Segmentation Networks, such as:
- U-Net Convolutional Encoder-Decoder Neural Network demonstrating biomedical image segmentation through symmetric skip connections.
- V-Net Convolutional Encoder-Decoder Neural Network demonstrating 3D medical volume segmentation through volumetric convolutions.
- Attention U-Net Convolutional Encoder-Decoder Neural Network demonstrating attention-gated segmentation for organ localization.
- Scene Understanding Networks, such as:
- SegNet Convolutional Encoder-Decoder Neural Network demonstrating efficient semantic segmentation through pooling index memorization.
- DeepLab Convolutional Encoder-Decoder Neural Network demonstrating atrous spatial pyramid pooling for multi-scale segmentation.
- PSPNet Convolutional Encoder-Decoder Neural Network demonstrating pyramid scene parsing for global context aggregation.
- Medical Image Segmentation Networks, such as:
- Image-to-Image Translation Networks, such as:
- Generative Translation Networks, such as:
- Pix2Pix Convolutional Encoder-Decoder Neural Network demonstrating conditional image generation through adversarial training.
- CycleGAN Convolutional Encoder-Decoder Neural Network demonstrating unpaired image translation through cycle consistency.
- Enhancement Networks, such as:
- SRCNN Convolutional Encoder-Decoder Neural Network demonstrating super-resolution reconstruction through convolutional mapping.
- Denoising Convolutional Encoder-Decoder Neural Network demonstrating noise removal through residual learning.
- Generative Translation Networks, such as:
- Dense Prediction Networks, such as:
- Depth Estimation Networks, such as:
- MonoDepth Convolutional Encoder-Decoder Neural Network demonstrating monocular depth prediction through disparity estimation.
- Surface Normal Prediction Networks, such as:
- MarrNet Convolutional Encoder-Decoder Neural Network demonstrating 3D shape reconstruction from 2D images.
- Depth Estimation Networks, such as:
- Sequence Processing Convolutional Encoder-Decoder Networks, such as:
- Text Processing Networks, such as:
- GEC Convolutional Encoder-Decoder Neural Network demonstrating grammatical error correction through character-level convolutions.
- ByteNet Convolutional Encoder-Decoder Neural Network demonstrating neural machine translation through dilated convolutions.
- Time Series Networks, such as:
- Temporal Convolutional Encoder-Decoder Neural Network demonstrating sequence modeling through causal convolutions.
- Text Processing Networks, such as:
- ...
- Image Segmentation Convolutional Encoder-Decoder Architectures, such as:
- Counter-Example(s):
- Recurrent Encoder-Decoder Neural Network, which processes sequential data through temporal state evolution rather than spatial convolution operations.
- Transformer Encoder-Decoder Neural Network, which uses self-attention mechanisms rather than convolutional filters for feature extraction.
- Fully Connected Encoder-Decoder Neural Network, which lacks spatial weight sharing and local connectivity patterns of convolutional architectures.
- Graph Encoder-Decoder Neural Network, which operates on graph-structured data rather than grid-structured spatial data.
- See: Convolutional Neural Network, Image Segmentation Task, Spatial Feature Learning, Encoder-Decoder Architecture, Deep Learning for Computer Vision, Semantic Segmentation, Image-to-Image Translation.
References
2018
- (Chollampatt & Ng, 2018) ⇒ Shamil Chollampatt, and Hwee Tou Ng. (2018). “A Multilayer Convolutional Encoder-Decoder Neural Network for Grammatical Error Correction.” In: Proceedings of the Thirty-Second Conference on Artificial Intelligence (AAAI-2018).
- QUOTE: The encoder and decoder are made up of [math]\displaystyle{ L }[/math] layers each. The architecture of the network is shown in Figure 1. The source token embeddings, [math]\displaystyle{ s_1, \cdots, s_m }[/math], are linearly mapped to get input vectors of the first encoder layer, [math]\displaystyle{ h^0_1 , \cdots, h^0_m, }[/math] where [math]\displaystyle{ h^0_i \in R^h }[/math] and [math]\displaystyle{ h }[/math] is the input and output dimension of all encoder and decoder layers.

=== 2018b ===
- (Saxena, 2018) ⇒ Rohan Saxena (April, 2018). "What is an Encoder/Decoder in Deep Learning?".
- QUOTE: In a CNN, an encoder-decoder network typically looks like this (a CNN encoder and a CNN decoder):
Image Credits: (Badrinarayanan et al., 2017)
This is a network to perform semantic segmentation of an image. The left half of the network maps raw image pixels to a rich representation of a collection of feature vectors. The right half of the network takes these features, produces an output and maps the output back into the “raw” format (in this case, image pixels). …
- QUOTE: In a CNN, an encoder-decoder network typically looks like this (a CNN encoder and a CNN decoder):
2017
- (Badrinarayanan et al., 2017) ⇒ Vijay Badrinarayanan, Alex Kendall, and Roberto Cipolla. (2017). “SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation.” In: IEEE Transactions on Pattern Analysis and Machine Intelligence, 39(12). doi:10.1109/TPAMI.2016.2644615
- QUOTE: SegNet has an encoder network and a corresponding decoder network, followed by a final pixelwise classification layer. This architecture is illustrated in Fig. 2. The encoder network consists of 13 convolutional layers which correspond to the first 13 convolutional layers in the VGG16 network (Simonyan & Zisserman, 2014) designed for object classification. ...
Each encoder layer has a corresponding decoder layer and hence the decoder network has 13 layers. The final decoder output is fed to a multi-class soft-max classifier to produce class probabilities for each pixel independently.
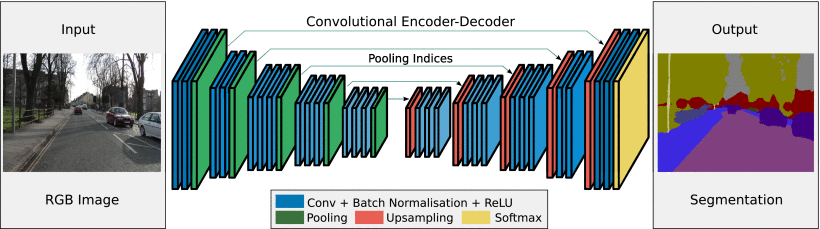
Figure 2. An illustration of the SegNet architecture. There are no fully connected layers and hence it is only convolutional. A decoder upsamples its input using the transferred pool indices from its encoder to produce a sparse feature map(s). It then performs convolution with a trainable filter bank to densify the feature map. The final decoder output feature maps are fed to a soft-max classifier for pixel-wise classification.
- QUOTE: SegNet has an encoder network and a corresponding decoder network, followed by a final pixelwise classification layer. This architecture is illustrated in Fig. 2. The encoder network consists of 13 convolutional layers which correspond to the first 13 convolutional layers in the VGG16 network (Simonyan & Zisserman, 2014) designed for object classification.