Deep Convolutional Neural Network (DCNN)
A Deep Convolutional Neural Network (DCNN) is a convolutional-pooling neural network that is a relatively deep learning neural network.
- Context:
- It can range from being a Very Deep CNN to being a Medium Depth CNN.
- …
- Example(s):
- an AlexNet (with 5 or more convolutional layers Krizhevsky et al., 2012) ;
- a DenseNet;
- a GoogLeNet;
- an InceptionV3;
- a LeNet-5;
- a MatConvNet;
- a SqueezeNet (with 10 convolutional layers and 8 max-pooling layers);
- a VGG CNN.
- …
- Counter-Example(s):
- See: Deep learning.
References
2017b
- (Rawat & Wang, 2017) ⇒ Rawat, W., & Wang, Z. (2017). Deep Convolutional Neural Networks for Image Classification: A comprehensive review. Neural computation, 29(9), 2352-2449.
- QUOTE: CNNs are feedforward networks in that information flow takes place in one direction only, from their inputs to their outputs. Just as artificial neural networks (ANN) are biologically inspired, so are CNNs. The visual cortex in the brain, which consists of alternating layers of simple and complex cells (Hubel & Wiesel, 1959, 1962), motivates their architecture. CNN architectures come in several variations; however, in general, they consist of convolutional and pooling (or subsampling) layers, which are grouped into modules. Either one or more fully connected layers, as in a standard feedforward neural network, follow these modules. Modules are often stacked on top of each other to form a deep model. Figure 1 illustrates typical CNN architecture for a toy image classification task. An image is input directly to the network, and this is followed by several stages of convolution and pooling. Thereafter, representations from these operations feed one or more fully connected layers. Finally, the last fully connected layer outputs the class label. Despite this being the most popular base architecture found in the literature, several architecture changes have been proposed in recent years with the objective of improving image classification accuracy or reducing computation costs. Although for the remainder of this section, we merely fleetingly introduce standard CNN architecture, in section 5 we deal with several architectural design changes that have facilitated enhanced image classification performance.

Figure 1: CNN image classification pipeline.
- QUOTE: CNNs are feedforward networks in that information flow takes place in one direction only, from their inputs to their outputs. Just as artificial neural networks (ANN) are biologically inspired, so are CNNs. The visual cortex in the brain, which consists of alternating layers of simple and complex cells (Hubel & Wiesel, 1959, 1962), motivates their architecture. CNN architectures come in several variations; however, in general, they consist of convolutional and pooling (or subsampling) layers, which are grouped into modules. Either one or more fully connected layers, as in a standard feedforward neural network, follow these modules. Modules are often stacked on top of each other to form a deep model. Figure 1 illustrates typical CNN architecture for a toy image classification task. An image is input directly to the network, and this is followed by several stages of convolution and pooling. Thereafter, representations from these operations feed one or more fully connected layers. Finally, the last fully connected layer outputs the class label. Despite this being the most popular base architecture found in the literature, several architecture changes have been proposed in recent years with the objective of improving image classification accuracy or reducing computation costs. Although for the remainder of this section, we merely fleetingly introduce standard CNN architecture, in section 5 we deal with several architectural design changes that have facilitated enhanced image classification performance.
2015
- (Patel et al., 2015) ⇒ Ankit B. Patel, Tan Nguyen, and Richard G. Baraniuk. (2015). “A Probabilistic Theory of Deep Learning." (PDF) In: arXiv:1504.00641 Journal.
- QUOTE: Furthermore, by relaxing the generative model to a discriminative one, we can recover two of the current leading deep learning systems, deep convolutional neural networks (DCNs) and random decision forests (RDFs), providing insights into their successes and shortcomings as well as a principled route to their improvement.
2014
- (Yu et al., 2014) ⇒ Yu, W., Yang, K., Bai, Y., Yao, H., & Rui, Y. (2014). Visualizing and comparing convolutional neural networks. arXiv preprint arXiv:1412.6631.
- ABSTRACT: Convolutional Neural Networks (CNNs) have achieved comparable error rates to well-trained human on ILSVRC2014 image classification task. To achieve better performance, the complexity of CNNs is continually increasing with deeper and bigger architectures. Though CNNs achieved promising external classification behavior, understanding of their internal work mechanism is still limited. In this work, we attempt to understand the internal work mechanism of CNNs by probing the internal representations in two comprehensive aspects, i.e., visualizing patches in the representation spaces constructed by different layers, and visualizing visual information kept in each layer. We further compare CNNs with different depths and show the advantages brought by deeper architecture.
2012
- (Krizhevsky et al., 2012) ⇒ Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton. "Imagenet Classification with Deep Convolutional Neural Networks." (PDF) In: Advances in Neural Information Processing Systems (NIPS 2012).
- QUOTE: Now we are ready to describe the overall architecture of our CNN. As depicted in Figure 2, the net contains eight layers with weights; the first five are convolutional and the remaining three are fully-connected. The output of the last fully-connected layer is fed to a 1000-way softmax which produces a distribution over the 1000 class labels. Our network maximizes the multinomial logistic regression objective, which is equivalent to maximizing the average across training cases of the log-probability of the correct label under the prediction distribution.
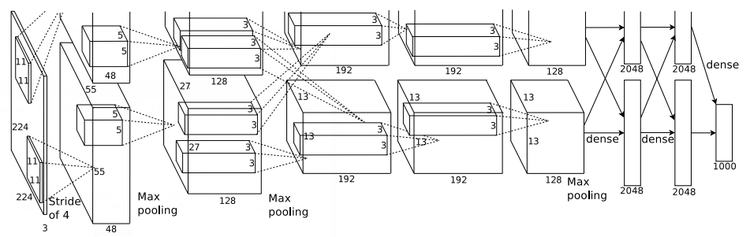
Figure 2: An illustration of the architecture of our CNN, explicitly showing the delineation of responsibilities between the two GPUs. One GPU runs the layer-parts at the top of the figure while the other runs the layer-parts at the bottom. The GPUs communicate only at certain layers. The network’s input is 150,528-dimensional, and the number of neurons in the network’s remaining layers is given by 253,440–186,624–64,896–64,896–43,264– 4096–4096–1000.
- QUOTE: Now we are ready to describe the overall architecture of our CNN. As depicted in Figure 2, the net contains eight layers with weights; the first five are convolutional and the remaining three are fully-connected. The output of the last fully-connected layer is fed to a 1000-way softmax which produces a distribution over the 1000 class labels. Our network maximizes the multinomial logistic regression objective, which is equivalent to maximizing the average across training cases of the log-probability of the correct label under the prediction distribution.
