Information Extraction System
An Information Extraction System is a data processing system that can solve an information extraction task by implementing an information extraction algorithm.
- AKA: Information Extractor, IE System, Automated Information Extraction System, Information Extraction Software.
- Context:
- It can typically process Unstructured Text Documents to extract information extraction target data.
- It can typically implement Information Extraction Algorithms for information extraction pattern matching.
- It can typically populate Information Extraction Templates with information extraction results.
- It can typically handle Multiple Information Extraction Tasks through information extraction pipelines.
- It can typically maintain Information Extraction Rule Sets for information extraction pattern recognition.
- ...
- It can often integrate Natural Language Processing Components for information extraction text analysis.
- It can often utilize Machine Learning Models for information extraction pattern learning.
- It can often support Domain-Specific Information Extraction Schemas for information extraction customization.
- It can often provide Information Extraction Confidence Scores for information extraction quality assessment.
- ...
- It can range from being a Heuristic Information Extraction System to being a Data-Driven Information Extraction System, depending on its information extraction methodology type.
- It can range from being an IE from Text System to being an IE from Semi-Structured Data System, depending on its information extraction data source type.
- It can range from being an Open Information Extraction System to being a Closed Information Extraction System, depending on its information extraction schema specification.
- It can range from being a General-Purpose Information Extraction System to being a Domain-Specific Information Extraction System, depending on its information extraction application scope.
- It can range from being a Rule-Based Information Extraction System to being a Statistical Information Extraction System, depending on its information extraction processing approach.
- ...
- It can process Domain-Specific Formatting Requirements to extract information extraction structured information.
- It can integrate with Knowledge Base Systems for information extraction entity linking.
- It can utilize Ontology-Based Information Extraction Frameworks for information extraction semantic processing.
- It can employ Information Extraction Evaluation Metrics for information extraction performance measurement.
- It can support Information Extraction APIs for information extraction service integration.
- ...
- Example(s):
- General-Purpose Information Extraction Systems, such as:
- Text Engineering Platforms, such as:
- NLP Toolkit-Based Systems, such as:
- Machine Learning Platforms, such as:
- Domain-Specific Information Extraction Systems, such as:
- Biomedical Information Extraction Systems, such as:
- Financial Information Extraction Systems, such as:
- Legal Information Extraction Systems, such as:
- Task-Specific Information Extraction Systems, such as:
- Entity-Focused Systems, such as:
- Relation-Focused Systems, such as:
- Event-Focused Systems, such as:
- Specialized Information Extraction Systems, such as:
- Template Filling Systems for information extraction slot filling.
- Knowledge Base Population Systems for information extraction fact extraction.
- Ontology Population Systems for information extraction knowledge acquisition.
- Definition Extraction Systems for information extraction terminology mining.
- GM-RKB Content Extraction System for information extraction wiki-formatted content.
- Web-Based Information Extraction Systems, such as:
- ...
- General-Purpose Information Extraction Systems, such as:
- Counter-Example(s):
- Information Retrieval System, which finds relevant documents rather than extracting information extraction structured data.
- Named Entity Recognition System, which only identifies entity mentions rather than performing information extraction template filling.
- Part-Of-Speech Tagging System, which assigns grammatical tags rather than extracting information extraction semantic content.
- Sentence Segmentation System, which splits text rather than extracting information extraction structured information.
- Word Sense Disambiguation System, which resolves lexical ambiguity rather than performing information extraction data structuring.
- See: Information Extraction Task, Information Extraction Algorithm, Semantic Relation Recognition System, Pattern Extractor, Natural Language Processing System, GM-RKB Content Extraction System, Definition Extraction Task.
References
2023
- (Wei, Cui et al., 2023) ⇒ Xiang Wei, Xingyu Cui, Ning Cheng, Xiaobin Wang, Xin Zhang, Shen Huang, Pengjun Xie, Jinan Xu, Yufeng Chen, Meishan Zhang and others. (2023). “Zero-shot Information Extraction via Chatting with Chatgpt.” In: arXiv preprint arXiv:2302.10205. doi:10.48550/arXiv.2302.10205
- QUOTE: Zero-shot information extraction (IE) aims to build IE systems from the unannotated text. ...
2019
- (Wikipedia, 2019) ⇒ https://en.wikipedia.org/wiki/Information_extraction Retrieved:2019-3-10.
- Information extraction (IE) is the task of automatically extracting structured information from unstructured and/or semi-structured machine-readable documents. In most of the cases this activity concerns processing human language texts by means of natural language processing (NLP). Recent activities in multimedia document processing like automatic annotation and content extraction out of images/audio/video/documents could be seen as information extraction
Due to the difficulty of the problem, current approaches to IE focus on narrowly restricted domains. An example is the extraction from newswire reports of corporate mergers, such as denoted by the formal relation:
[math]\displaystyle{ \mathrm{MergerBetween}(company_1, company_2, date) }[/math] ,
from an online news sentence such as:
"Yesterday, New York based Foo Inc. announced their acquisition of Bar Corp."
A broad goal of IE is to allow computation to be done on the previously unstructured data. A more specific goal is to allow logical reasoning to draw inferences based on the logical content of the input data. Structured data is semantically well-defined data from a chosen target domain, interpreted with respect to category and context.
Information Extraction is the part of a greater puzzle which deals with the problem of devising automatic methods for text management, beyond its transmission, storage and display. The discipline of information retrieval (IR) has developed automatic methods, typically of a statistical flavor, for indexing large document collections and classifying documents. Another complementary approach is that of natural language processing (NLP) which has solved the problem of modelling human language processing with considerable success when taking into account the magnitude of the task. In terms of both difficulty and emphasis, IE deals with tasks in between both IR and NLP. In terms of input, IE assumes the existence of a set of documents in which each document follows a template, i.e. describes one or more entities or events in a manner that is similar to those in other documents but differing in the details. An example, consider a group of newswire articles on Latin American terrorism with each article presumed to be based upon one or more terroristic acts. We also define for any given IE task a template, which is a(or a set of) case frame(s) to hold the information contained in a single document. For the terrorism example, a template would have slots corresponding to the perpetrator, victim, and weapon of the terroristic act, and the date on which the event happened. An IE system for this problem is required to “understand” an attack article only enough to find data corresponding to the slots in this template.
- Information extraction (IE) is the task of automatically extracting structured information from unstructured and/or semi-structured machine-readable documents. In most of the cases this activity concerns processing human language texts by means of natural language processing (NLP). Recent activities in multimedia document processing like automatic annotation and content extraction out of images/audio/video/documents could be seen as information extraction
2009
- (Bird et al., 2009) ⇒ Steven Bird, Ewan Klein, and Edward Loper. (2009). "Extracting Information from Text". In:“Natural Language Processing with Python." O'Reilly Media. ISBN:9780596555719 (Chapter 7).
- QUOTE: Figure 7-1 shows the architecture for a simple information extraction system. It begins by processing a document using several of the procedures discussed in Chapters 3 and 5: first, the raw text of the document is split into sentences using a sentence segmenter, and each sentence is further subdivided into words using a tokenizer. Next, each sentence is tagged with part-of-speech tags, which will prove very helpful in the next step, named entity recognition. In this step, we search for mentions of potentially interesting entities in each sentence. Finally, we use relation recognition to search for likely relations between different entities in the text.
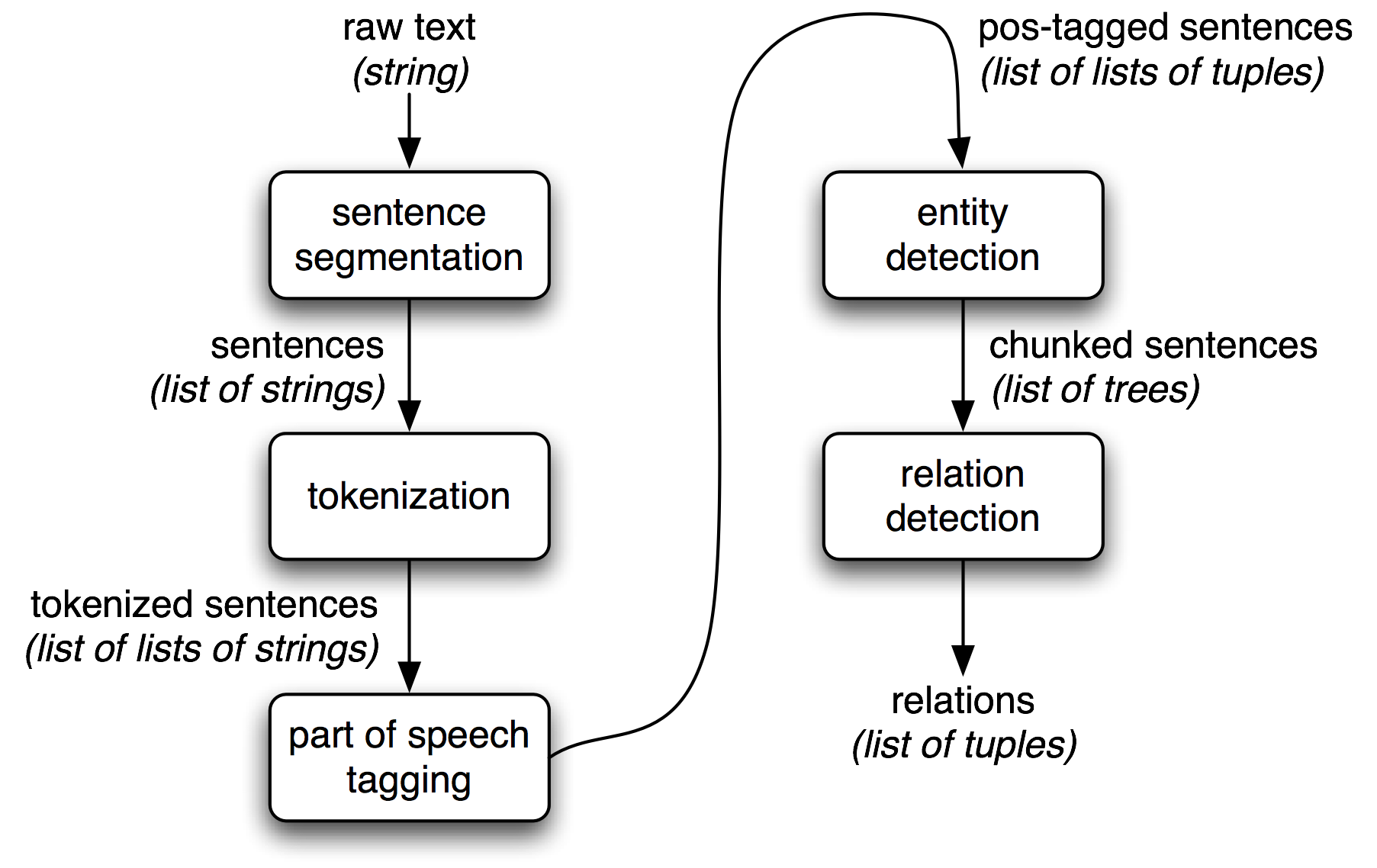
Figure 7-1. Simple pipeline architecture for an information extraction system. This system takes the raw text of a document as its input, and generates a list of (entity, relation, entity) tuples as its output. For example, given a document that indicates that the company Georgia-Pacific is located in Atlanta, it might generate the tuple (
[ORG: 'Georgia-Pacific']'in'[LOC: 'Atlanta']).
- QUOTE: Figure 7-1 shows the architecture for a simple information extraction system. It begins by processing a document using several of the procedures discussed in Chapters 3 and 5: first, the raw text of the document is split into sentences using a sentence segmenter, and each sentence is further subdivided into words using a tokenizer. Next, each sentence is tagged with part-of-speech tags, which will prove very helpful in the next step, named entity recognition. In this step, we search for mentions of potentially interesting entities in each sentence. Finally, we use relation recognition to search for likely relations between different entities in the text.