SparkContext Object
A SparkContext Object is a Spark object (within a Spark Driver) that acts as the cluster program master of a Spark application.
- Context:
- It can (typically) be preceded with the creation of a SparkConf Object (that contains information about the Spark application).
- It can (typically) be defined by a Spark Driver Program.
- It can (typically) be used to create RDDs, accumulators and broadcast variables, access Spark services and run jobs.
- …
- Counter-Example(s):
- See: SparkConf, Spark Platform.
References

2016
- https://spark.apache.org/docs/latest/api/java/org/apache/spark/SparkContext.html
- QUOTE: Main entry point for Spark functionality. A SparkContext represents the connection to a Spark cluster, and can be used to create RDDs, accumulators and broadcast variables on that cluster.
Only one SparkContext may be active per JVM. You must stop() the active SparkContext before creating a new one. This limitation may eventually be removed; see SPARK-2243 for more details.
param: config a Spark Config object describing the application configuration. Any settings in this config overrides the default configs as well as system properties.
- QUOTE: Main entry point for Spark functionality. A SparkContext represents the connection to a Spark cluster, and can be used to create RDDs, accumulators and broadcast variables on that cluster.
2016
- https://spark.apache.org/docs/latest/programming-guide.html
- QUOTE: The first thing a Spark program must do is to create a SparkContext object, which tells Spark how to access a cluster. To create a SparkContext you first need to build a SparkConf object that contains information about your application.
- conf = SparkConf().setAppName(appName).setMaster(master)
- sc = SparkContext(conf=conf)
- The appName parameter is a name for your application to show on the cluster UI. master is a Spark, Mesos or YARN cluster URL, or a special “local” string to run in local mode. In practice, when running on a cluster, you will not want to hardcode master in the program, but rather launch the application with spark-submit and receive it there. However, for local testing and unit tests, you can pass “local” to run Spark in-process.
- QUOTE: The first thing a Spark program must do is to create a SparkContext object, which tells Spark how to access a cluster. To create a SparkContext you first need to build a SparkConf object that contains information about your application.
2016
- http://github.com/jaceklaskowski/mastering-apache-spark-book/blob/master/spark-sparkcontext.adoc
- QUOTE: A Spark context is essentially a client of Spark’s execution environment and acts as the master of your Spark application (don’t get confused with the other meaning of Master in Spark, though).
Once a SparkContext instance is created you can use it to create RDDs, accumulators and broadcast variables, access Spark services and run jobs.
- QUOTE: A Spark context is essentially a client of Spark’s execution environment and acts as the master of your Spark application (don’t get confused with the other meaning of Master in Spark, though).
2015
- http://spark.apache.org/docs/latest/cluster-overview.html
- QUOTE: Spark applications run as independent sets of processes on a cluster, coordinated by the SparkContext object in your main program (called the driver program).
Specifically, to run on a cluster, the SparkContext can connect to several types of cluster managers (either Spark’s own standalone cluster manager, Mesos or YARN), which allocate resources across applications. Once connected, Spark acquires executors on nodes in the cluster, which are processes that run computations and store data for your application. Next, it sends your application code (defined by JAR or Python files passed to SparkContext) to the executors. Finally, SparkContext sends tasks to the executors to run.
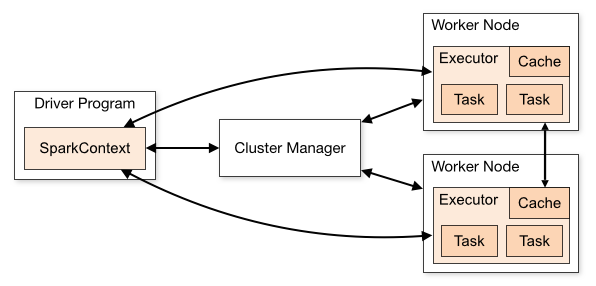
There are several useful things to note about this architecture:- Each application gets its own executor processes, which stay up for the duration of the whole application and run tasks in multiple threads. This has the benefit of isolating applications from each other, on both the scheduling side (each driver schedules its own tasks) and executor side (tasks from different applications run in different JVMs). However, it also means that data cannot be shared across different Spark applications (instances of SparkContext) without writing it to an external storage system.
- Spark is agnostic to the underlying cluster manager. As long as it can acquire executor processes, and these communicate with each other, it is relatively easy to run it even on a cluster manager that also supports other applications (e.g. Mesos/YARN).
- The driver program must listen for and accept incoming connections from its executors throughout its lifetime (e.g., see spark.driver.port and spark.fileserver.port in the network config section). As such, the driver program must be network addressable from the worker nodes.
- Because the driver schedules tasks on the cluster, it should be run close to the worker nodes, preferably on the same local area network. If you’d like to send requests to the cluster remotely, it’s better to open an RPC to the driver and have it submit operations from nearby than to run a driver far away from the worker nodes.
- QUOTE: Spark applications run as independent sets of processes on a cluster, coordinated by the SparkContext object in your main program (called the driver program).

2015
- (StackOverflow, 2015): "What are workers, executors, cores in Spark Standalone cluster?.” In: StackOverflow, answered Sep 17 '15 Marco (edited Mar 26 at 15:58 Jacek Laskowski)
- QUOTE: Spark uses a master/slave architecture. As you can see in the figure, it has one central coordinator (Driver) that communicates with many distributed workers (executors). The driver and each of the executors run in their own Java processes.
DRIVER: The driver is the process where the main method runs. First it converts the user program into tasks and after that it schedules the tasks on the executors.
EXECUTORS: Executors are worker nodes' processes in charge of running individual tasks in a given Spark job. They are launched at the beginning of a Spark application and typically run for the entire lifetime of an application. Once they have run the task they send the results to the driver. They also provide in-memory storage for RDDs that are cached by user programs through Block Manager.
APPLICATION EXECUTION FLOW With this in mind, when you submit an application to the cluster with spark-submit this is what happens internally:
- A standalone application starts and instantiates a SparkContext instance (and it is only then when you can call the application a driver).
- The driver program ask for resources to the cluster manager to launch executors.
- The cluster manager launches executors.
- The driver process runs through the user application. Depending on the actions and transformations over RDDs task are sent to executors.
- Executors run the tasks and save the results.
- If any worker crashes, its tasks will be sent to different executors to be processed again. In the book "Learning Spark: Lightning-Fast Big Data Analysis" they talk about Spark and Fault Tolerance:
- Spark automatically deals with failed or slow machines by re-executing failed or slow tasks. For example, if the node running a partition of a map() operation crashes, Spark will rerun it on another node; and even if the node does not crash but is simply much slower than other nodes, Spark can preemptively launch a “speculative” copy of the task on another node, and take its result if that finishes.
With SparkContext.stop() from the driver or if the main method exits/crashes all the executors will be terminated and the cluster resources will be released by the cluster manager.
- When executors are started they register themselves with the driver and from so on they communicate directly. The workers are in charge of communicating the cluster manager the availability of their resources.
- In a YARN cluster you can do that with --num-executors. In a standalone cluster you will get one executor per worker unless you play with spark.executor.cores and a worker has enough cores to hold more than one executor. (As @JacekLaskowski pointed out, --num-executors is no longer in use in YARN https://github.com/apache/spark/commit/16b6d18613e150c7038c613992d80a7828413e66)
- You can assign the number of cores per executor with --executor-cores
- --total-executor-cores is the max number of executor cores per application
- QUOTE: Spark uses a master/slave architecture. As you can see in the figure, it has one central coordinator (Driver) that communicates with many distributed workers (executors). The driver and each of the executors run in their own Java processes.