Rule Induction Algorithm
Jump to navigation
Jump to search
A Rule Induction Algorithm is an Inductive Logic Programming Algorithm that produces a rule-based model.
- AKA: Rule Learning Algorithm, Rule Extraction Algorithm.
- Context:
- It can be implemented by Rule Induction System (that solves a rule induction task).
- It can range from being a Propositional Rule Induction Algorithm to being a First-Order Rule Logic Rule Induction Algorithm.
- It ranges from being a Global Rule Induction Algorithm to being a Local Rule Induction Algorithm.
- Example(s):
- CN2 Algorithm (Clark & Nibblet, 1989),
- FINDBESTRULE Algorithm (Furnkranz, 2017)
- FOIL Algorithm (Quinlan, 1990),
- FURIA Algorithm (Huhn & Hullermeier, 2009),
- LEM-based Algorithms (e.g. Grzymala‐Busse & Stefanowski, 2001),
- Progol Algorithm (Muggleton, 1995),
- RIPPER Algorithm (Cohen, 1995)
- Rulearner Algorithm (Sahami, 1995),
- RULEX Algorithm (Andrews & Geva, 1995).
- …
- Counter-Example(s):
- See: Pattern Mining Algorithm, Decision Tree Induction Algorithm, Inductive Logic Programming, If-Then Rule, First-Order Logic Rule.
References
2019
- (Wikipedia, 2019) ⇒ https://en.wikipedia.org/wiki/Rule_induction Retrieved:2019-11-2.
- Rule induction is an area of machine learning in which formal rules are extracted from a set of observations. The rules extracted may represent a full scientific model of the data, or merely represent local patterns in the data.
2018a
- (Sushil et al., 2018) ⇒ Madhumita Sushil, Simon Suster, and Walter Daelemans. (2018). “Rule Induction for Global Explanation of Trained Models.” In: Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP. doi:10.18653/v1/W18-5411
- QUOTE: Our proposed technique comprises of these main steps:
- 1. Input saliency computation (§ 3.1)
- 2. Input transformation and selection (§ 3.2)
- 3. Rule induction (§ 3.3)
- The entire pipeline is depicted in Figure 1.

|
2018b
- (Kotelnikov & Milov, 2018) ⇒ E V Kotelnikov, and V R Milov. (2018). “Comparison of Rule Induction, Decision Trees and Formal Concept Analysis Approaches for Classification.” In: Proceedings of International Conference Information Technologies in Business and Industry 2018 IOP Publishing. IOP Conf. Series: Journal of Physics: Conf. Series 1015 (2018) 032068 doi:10.1088/1742-6596/1015/3/032068
- QUOTE: Ripper (Repeated Incremental Pruning to Produce Error Reduction) [4] is a rule induction based on reduced error pruning [5]. Ripper includes three stages of rule processing: building, optimization and clean-up [6]. In the first stage, a training dataset is divided into growing and pruning sets. Rules are constructed on the basis of a growing set. Later these rules are reduced with the help of a pruning set. At the optimization stage, all rules are reconsidered in order to reduce the error on the entire dataset. At the clean-up phase, it is checked whether each Description Length (DL) rule increases the whole rule set and the dataset. The calculation of DL allows one to quantify the complexity of various rule sets, which describe dataset [7]. In case if the rule increases DL, it is deleted.
2017a
- (Cussens, 2017) ⇒ James Cussens (2017). "Induction". In: Sammut & Webb (2017). DOI:10.1007/978-1-4899-7687-1_388
- QUOTE: Induction is the process of inferring a general rule from a collection of observed instances. Sometimes it is used more generally to refer to any inference from premises to conclusion where the truth of the conclusion does not follow deductively from the premises, but where the premises provide evidence for the conclusion. In this more general sense, induction includes abduction where facts rather than rules are inferred. (The word “induction” also denotes a different, entirely deductive form of argument used in mathematics.)
2017b
- (Furnkranz, 2017) ⇒ Johannes Furnkranz (2017). "Rule Learning". In: Sammut & Webb (2017). DOI:10.1007/978-1-4899-7687-1_744
- QUOTE: FINDBESTRULE is a prototypical algorithm that searches for a rule which optimizes a given quality criterion defined in EVALUATERULE. The value of this heuristic function is the higher the more positive and the less negative examples are covered by the candidate rule. FINDBESTRULE maintains Rules, a sorted list of candidate rules, which is initialized by the procedure INITIALIZERULE. New rules will be inserted in appropriate places (INSERTSORT), so that Rules will always be sorted in decreasing order of the heuristic evaluations of the rules. At each cycle, SELECTCANDIDATES selects a subset of these candidate rules, which are then refined using the refinement operator REFINERULE. Each refinement is evaluated and inserted into the sorted Rules list unless the STOPPINGCRITERION prevents this. If the evaluation of the NewRule is better than the best rule found previously, BestRule is set to NewRule. FILTERRULES selects the subset of the ordered rule list that will be used in subsequent iterations. When all candidate rules have been processed, the best rule will be returned.
2009a
- (Huhn & Hullermeier, 2009) ⇒ Jens Huhn, and Eyke Hullermeier. (2009). “FURIA: An Algorithm for Unordered Fuzzy Rule Induction.” In: Data mining and knowledge discovery Journal, 19(3). doi:10.1007/s10618-009-0131-8
- QUOTE: This paper introduces a novel fuzzy rule-based classification method called FURIA, which is short for Fuzzy Unordered Rule Induction Algorithm. FURIA extends the well-known RIPPER algorithm, a state-of-the-art rule learner, while preserving its advantages, such as simple and comprehensible rule sets. In addition, it includes a number of modifications and extensions. In particular, FURIA learns fuzzy rules instead of conventional rules and unordered rule sets instead of rule lists.
2009b
- (Grzymala-Busse, 2009) ⇒ Jerzy W. Grzymala-Busse. (2009). “Rule Induction.” In: Maimon O., Rokach L. (eds) Data Mining and Knowledge Discovery Handbook. ISBN:978-0-387-09822-7, 978-0-387-09823-4. doi:10.1007/978-0-387-09823-4_13
- QUOTE: In general, rule induction algorithms may be categorized as global and local. In global rule induction algorithms the search space is the set of all attribute values, while in local rule induction algorithms the search space is the set of attribute-value pairs.
2001
- (Grzymala‐Busse & Stefanowski, 2001) ⇒ Jerzy W. Grzymala-Busse, and Jerzy Stefanowski(2001). "Three Discretization Methods For Rule Induction". Proceedings of the International Journal of Intelligent Systems, 16(1), 29-38.
- QUOTE: We compare the classification accuracy of a discretization method based on conditional entropy, applied before rule induction, with two newly proposed methods, incorporated directly into the rule induction algorithm LEM2, where discretization and rule induction are performed at the same time. In all three approaches the same system is used for classification of new, unseen data. As a result, we conclude that an error rate for all three methods does not show significant difference, however, rules induced by the two new methods are simpler and stronger.
1997
- (Palmer, 1997) ⇒ David D. Palmer. (1997). “A Trainable Rule-based Algorithm for Word Segmentation.” In: Proceedings of the ACL 1997 Conference. doi:10.3115/976909.979658.
- This paper presents a trainable rule-based algorithm for performing word segmentation....
1996
- (Domingos, 1996) ⇒ Pedro Domingos. (1996). “Unifying Instance-based and Rule-based Induction.” In: Machine Learning, 24(2). doi:10.1023/A:1018006431188
- Rule induction algorithms (Michalski, 1983; Michalski, Mozetic, Hong & Lavrac, 1986; Clark & Niblett, 1989; Rivest, 1987) typically employ a set covering or “separate and conquer” approach to induction.
1995a
- (Cohen, 1995) ⇒ William W.Cohen (1995). "Fast Effective Rule induction". Proceedings of the Twelfth International Conference on Machine Learning (ICML 1995). DOI:10.1016/B978-1-55860-377-6.50023-2
- ABSTRACT: Many existing rule learning systems are computationally expensive on large noisy datasets. In this paper we evaluate the recently-proposed rule learning algorithm IREP on a large and diverse collection of benchmark problems. We show that while IREP is extremely efficient, it frequently gives error rates higher than those of C4.5 and C4.5rules. We then propose a number of modifications resulting in an algorithm RIPPERk that is very competitive with C4.5rules with respect to error rates, but much more efficient on large samples. RIPPERk obtains error rates lower than or equivalent to C4.5rules on 22 of 37 benchmark problems, scales nearly linearly with the number of training examples, and can efficiently process noisy datasets containing hundreds of thousands of examples.
1995b
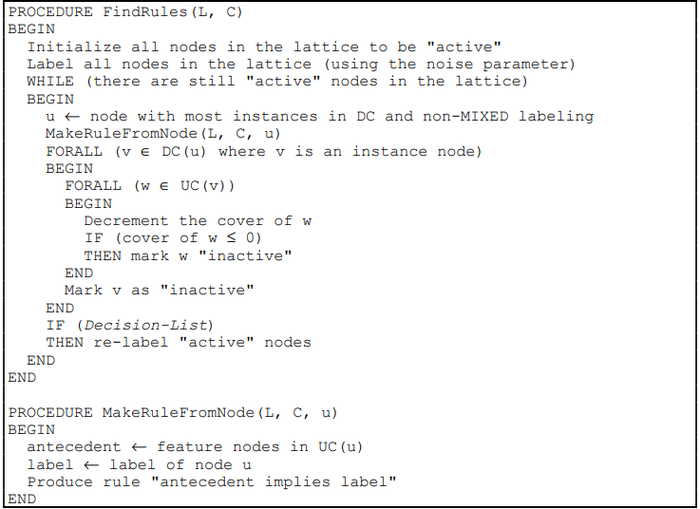
- (Sahami, 1995) ⇒ Mehran Sahami (1995). "Learning Classification Rules Using Lattices". In: Proceedings of the European Conference on Machine Learning (ECML-95). DOI:10.1007/3-540-59286-5_83
- QUOTE: The Rulearner algorithm takes as input a lattice, L, and a set of instance classification labelings, C, which correspond to the instance nodes in L. The algorithm produces a set of symbolic classification rules as output. The user is also able to specify a noise parameter to the system as a percentage figure by which each induced rule can misclassify some portion of the training instances that it applies to. Furthermore, the user can configure the system to induce either a decision-list or an unordered set of rules, and can also decide whether the classification rules induced should only identify one given labeling (i.e. derive only rules with a "positive" labeling) or if the rules should attempt to classify all instances in the training set. While the basic framework of the algorithm is general enough to properly deal with more than two classification labelings, we present the algorithm here as a binary classifier for easier understanding.

Table 1: Pseudo-code for the Rulearner algorithm. Note that L is the input lattice and C is the classification labelings for the instances which were used in building L.
1995c
- (Andrews & Geva, 1995) ⇒ Robert Andrews, and Shlomo Geva (1995). "RULEX & CEBP Networks As the Basis for a Rule Refinement System". Hybrid problems, hybrid solutions, 27, 1.
- QUOTE: We Also describe RULEX, an automated procedure for extracting accurate symbolic rules from the local basins of attraction produced by CEBP networks. RULEX extracts propositional if-then rules by direct interpretation of the parameters which describe the CEBP local functions thus making it very computationally efficient. We also describe how RULEX can be used to preconfigure the CEBP network to encapsulate existing domain knowledge. This ability to encode existing knowledge into the network, train and then extract accurate rules makes the CEBP network and RULEX the basis for a good knowledge refinement system. Further, the degree of accuracy and computational efficiency of the knowledge insertion, training, and rule extraction process gives this method significant advantages over existing ANN rule refinement techniques.
1995d
- (Muggleton, 1995) ⇒ Stephen Muggleton (1995). "Inverse Entailment And Progol". New Generation Computing, 13(3-4), 245-286. DOI:10.1007/BF03037227
- QUOTE: This paper firstly provides a re-appraisal of the development of techniques for inverting deduction, secondly introduces Mode-Directed Inverse Entailment (MDIE) as a generalisation and enhancement of previous approaches and thirdly describes an implementation of MDIE in the Progol system. Progol is implemented in C and available by anonymous ftp. The re-assessment of previous techniques in terms of inverse implication leads to new results for learning from positive data and inverting implication between pairs of clauses.
1993
- (Brill, 1993a) ⇒ Eric D. Brill. (1993). “A Simple Rule-based Part of Speech Tagger.” In: Proceedings of the third Conference on Applied Natural Language Processing. doi:10.3115/974499.974526
1991
- (Muggleton, 1991) ⇒ Stephen Muggleton. (1991). “Inductive Logic Programming.” In: Journal of New Generation Computing, 8(4). doi:10.1007/BF03037089
1990
- (Quinlan, 1990) ⇒ J. Ross Quinlan. (1990). “Learning Logical Definitions from Examples.” In: Machine Learning, 5(3). doi:10.1007/BF00117105
- QUOTE: This paper describes FOIL, a system that learns Horn clauses from data expressed as relations. FOIL is based on ideas that have proved effective in attribute-value learning systems, but extends them to a first-order formalism. This new system has been applied successfully to several tasks taken from the machine learning literature.
1989
- (Clark & Nibblet, 1989) ⇒ Peter Clark, Tim Niblett (1989). “The CN2 Induction Algorithm”. In: Machine Learning, 3(4)DOI:10.1023/A:1022641700528
- QUOTE: This paper presents a description and empirical evaluation of a new induction system, CN2, designed for the efficient induction of simple, comprehensible production rules in domains where problems of poor description language and/or noise may be present. Implementations of the CN2, ID3, and AQ algorithms are compared on three medical classification tasks.
1987
- (Rivest, 1987) ⇒ R. L. Rivest. (1987). “Learning Decision Lists.” In: Machine Learning, 2.
1986
- R. S. Michalski, I. Mozetic, J. Hong, and N. Lavrac. (1986). “The multi-purpose incremental learning system AQ 15 and its testing application to three medical domains.” In: Proceedings of the Fifth National Conference on Artificial Intelligence.
1983
- R. S. Michalski. (1983). “A Theory and Methodology of Inductive Learning.” In: Artificial Intelligence, 20.