2017 BidirectionalAttentionFlowforMa
- (Seo et al., 2017) ⇒ Minjoon Seo, Aniruddha Kembhavi, Ali Farhadi, and Hannaneh Hajishirzi. (2017). “Bidirectional Attention Flow for Machine Comprehension.” In: Proceedings of ICLR 2017.
Subject Headings:
Notes
Cited By
Quotes
Abstract
Machine comprehension (MC), answering a query about a given context paragraph, requires modeling complex interactions between the context and the query. Recently, attention mechanisms have been successfully extended to MC. Typically these methods use attention to focus on a small portion of the context and summarize it with a fixed-size vector, couple attentions temporally, and/or often form a uni-directional attention. In this paper we introduce the Bi-Directional Attention Flow (BIDAF) network, a multi-stage hierarchical process that represents the context at different levels of granularity and uses bi-directional attention flow mechanism to obtain a query-aware context representation without early summarization. Our experimental evaluations show that our model achieves the state-of-the-art results in Stanford Question Answering Dataset (SQuAD) and CNN / DailyMail cloze test.
1 INTRODUCTION
The tasks of machine comprehension (MC) and question answering (QA) have gained significant popularity over the past few years within the natural language processing and computer vision communities. Systems trained end-to-end now achieve promising results on a variety of tasks in the text and image domains. One of the key factors to the advancement has been the use of neural attention mechanism, which enables the system to focus on a targeted area within a context paragraph (for MC) or within an image (for Visual QA), that is most relevant to answer the question (Weston et al., 2015; Antol et al., 2015; Xiong et al., 2016a). Attention mechanisms in previous works typically have one or more of the following characteristics. First, the computed attention weights are often used to extract the most relevant information from the context for answering the question by summarizing the context into a fixed-size vector. Second, in the text domain, they are often temporally dynamic, whereby the attention weights at the current time step are a function of the attended vector at the previous time step. Third, they are usually uni-directional, wherein the query attends on the context paragraph or the image.
In this paper, we introduce the Bi-Directional Attention Flow (BIDAF) network, a hierarchical multi-stage architecture for modeling the representations of the context paragraph at different levels of granularity (Figure 1). BIDAF includes character-level, word-level, and contextual embeddings, and uses bi-directional attention flow to obtain a query-aware context representation. Our attention mechanism offers following improvements to the previously popular attention paradigms. First, our attention layer is not used to summarize the context paragraph into a fixed-size vector. Instead, the attention is computed for every time step, and the attended vector at each time step, along with the representations from previous layers, is allowed to flow through to the subsequent modeling layer. This reduces the information loss caused by early summarization. Second, we use a memory-less attention mechanism. That is, while we iteratively compute attention through time as in Bahdanau et al. (2015), the attention at each time step is a function of only the query and the context paragraph at the current time step and does not directly depend on the attention at the previous time step. We hypothesize that this simplification leads to the division of labor between the attention layer and the modeling layer. It forces the attention layer to focus on learning the attention between the query and the context, and enables the modeling layer to focus on learning the interaction within the query-aware context representation (the output of the attention layer). It also allows the attention at each time step to be unaffected from incorrect attendances at previous time steps. Our experiments show that memory-less attention gives a clear advantage over dynamic attention. Third, we use attention mechanisms in both directions, query-to-context and context-to-query, which provide complimentary information to each other.
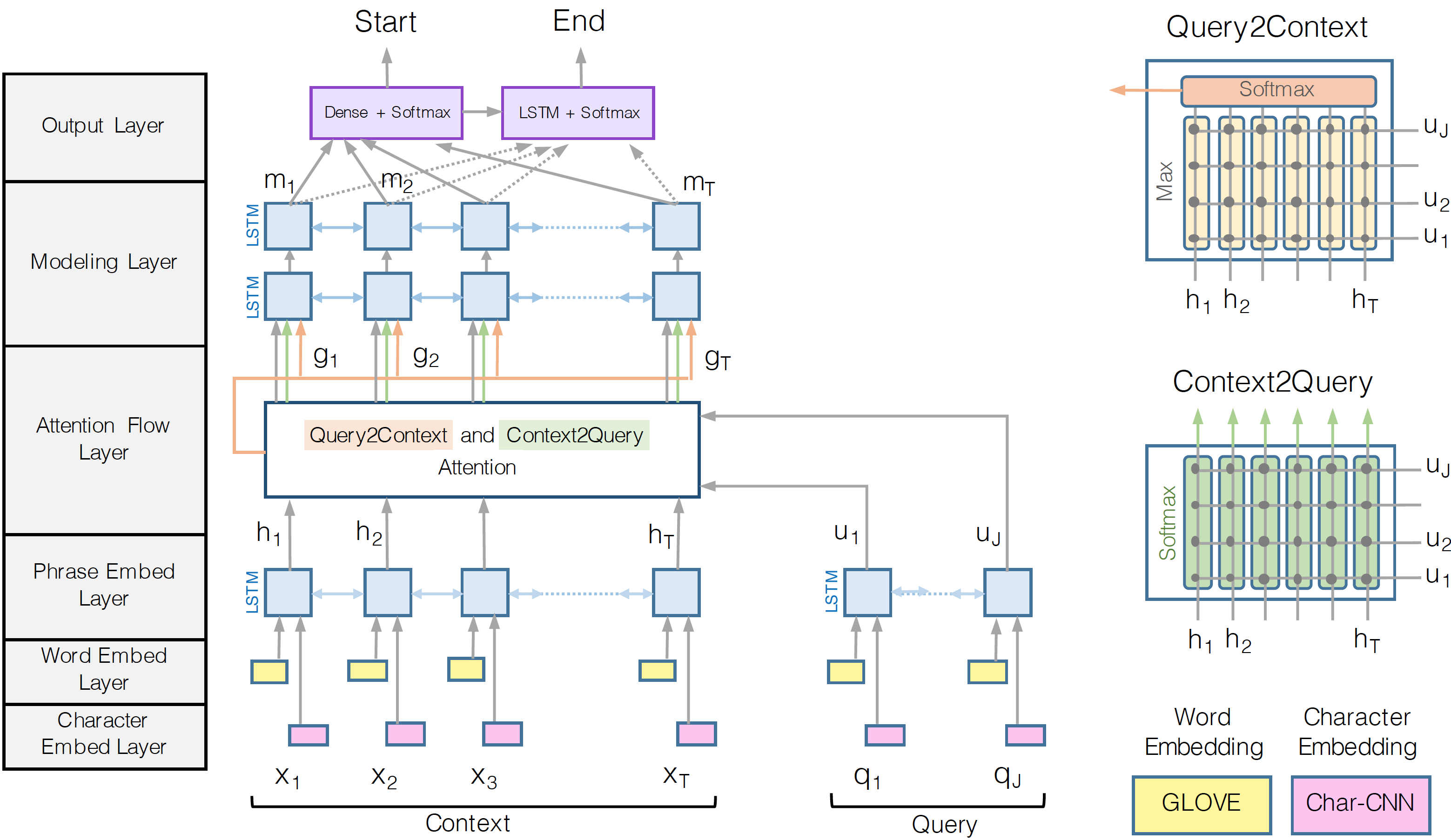
Figure 1: BiDirectional Attention Flow Model (best viewed in color)
Our BIDAF model1 outperforms all previous approaches on the highly-competitive Stanford Question Answering Dataset (SQuAD) test set leaderboard at the time of submission. With a modification to only the output layer, BIDAF achieves the state-of-the-art results on the CNN/DailyMail cloze test. We also provide an in-depth ablation study of our model on the SQuAD development set, visualize the intermediate feature spaces in our model, and analyse its performance as compared to a more traditional language model for machine comprehension (Rajpurkar et al., 2016).
2 MODEL
Our machine comprehension model is a hierarchical multi-stage process and consists of six …
- . Character Embedding Layer maps each word to a vector space using character-level CNNs.
- . Word Embedding Layer maps each word to a vector space using a pre-trained word embedding model.
- . Contextual Embedding Layer utilizes contextual cues from surrounding words to refine the embedding of the words. These first three layers are applied to both the query and context.
- . Attention Flow Layer couples the query and context vectors and produces a set of query-aware feature vectors for each word in the context.
- . Modeling Layer employs a Recurrent Neural Network to scan the context.
- . Output Layer provides an answer to the query.
- 1. Character Embedding Layer.
Character embedding layer is responsible for mapping each word to a high-dimensional vector space. Let [math]\displaystyle{ \{x_1, ..., x_T\} }[/math] and [math]\displaystyle{ \{q_1, ..., q_J\} }[/math] represent the words in the input context paragraph and query, respectively. Following Kim (2014), we obtain the character-level embedding of each word using Convolutional Neural Networks (CNN). Characters are embedded into vectors, which can be considered as 1D inputs to the CNN, and whose size is the input channel size of the CNN. The outputs of the CNN are max-pooled over the entire width to obtain a fixed-size vector for each word.
- 2. Word Embedding Layer.
Word embedding layer also maps each word to a high-dimensional vector space. We use pre-trained word vectors, GloVe (Pennington et al., 2014), to obtain the fixed word embedding of each word. The concatenation of the character and word embedding vectors is passed to a two-layer Highway Network (Srivastava et al., 2015). The outputs of the Highway Network are two sequences of d- dimensional vectors, or more conveniently, two matrices: X 2 Rd�T for the context and Q 2 Rd�J for the query.
- 3. Contextual Embedding Layer.
We use a Long Short-Term Memory Network (LSTM) (Hochreiter & Schmidhuber, 1997) on top of the embeddings provided by the previous layers to model the temporal interactions between words. We place an LSTM in both directions, and concatenate the outputs of the two LSTMs. Hence we obtain H 2 R2d�T from the context word vectors X, and U 2 R2d�J from query word vectors Q. Note that each column vector of H and U is 2d-dimensional because of the concatenation of the outputs of the forward and backward LSTMs, each with d-dimensional output. It is worth noting that the first three layers of the model are computing features from the query and context at different levels of granularity, akin to the multi-stage feature computation of convolutional neural networks in the computer vision field.
- 4. Attention Flow Layer.
Attention flow layer is responsible for linking and fusing information from the context and the query words. Unlike previously popular attention mechanisms (Weston et al., 2015; Hill et al., 2016; Sordoni et al., 2016; Shen et al., 2016), the attention flow layer is not used to summarize the query and context into single feature vectors. Instead, the attention vector at each time step, along with the embeddings from previous layers, are allowed to flow through to the subsequent modeling layer. This reduces the information loss caused by early summarization. The inputs to the layer are contextual vector representations of the context H and the query U. The outputs of the layer are the query-aware vector representations of the context words, G, along with the contextual embeddings from the previous layer. In this layer, we compute attentions in two directions: from context to query as well as from query to context. Both of these attentions, which will be discussed below, are derived from a shared similarity matrix, S 2 RT�J , between the contextual embeddings of the context (H) and the query (U), where Stj indicates the similarity between t-th context word and j-th query word. The similarity matrix is computed by Stj = �(H:t;U:j) 2 R (1) where � is a trainable scalar function that encodes the similarity between its two input vectors,H:t is t-th column vector of H, and U:j is j-th column vector of U, We choose �(h; u) = w> (S)[h; u; h � u], where w(S) 2 R6d is a trainable weight vector, � is elementwise multiplication, [;] is vector concatenation across row, and implicit multiplication is matrix multiplication. Now we use S to obtain the attentions and the attended vectors in both directions. Context-to-query Attention. Context-to-query (C2Q) attention signifies which query words are most relevant to each context word. Let at 2 RJ represent the attention weights on the query words by t-th context word, P atj = 1 for all t. The attention weight is computed by at = softmax(St:) 2 RJ , and subsequently each attended query vector is ~U
- t =
P j atjU:j . Hence ~U is a 2d-by-T matrix containing the attended query vectors for the entire context. Query-to-context Attention. Query-to-context (Q2C) attention signifies which context words have the closest similarity to one of the query words and are hence critical for answering the query.
We obtain the attention weights on the context words by b = softmax(maxcol(S)) 2 RT , where the maximum function (maxcol) is performed across the column. Then the attended context vector is ~h = P t btH:t 2 R2d. This vector indicates the weighted sum of the most important words in the context with respect to the query. ~h is tiled T times across the column, thus giving ~H 2 R2d�T . Finally, the contextual embeddings and the attention vectors are combined together to yield G, where each column vector can be considered as the query-aware representation of each context word. We define G by G:t = �(H:t; ~U
- t; ~H
- t) 2 RdG (2)
where G:t is the t-th column vector (corresponding to t-th context word), � is a trainable vector function that fuses its (three) input vectors, and dG is the output dimension of the � function. While the � function can be an arbitrary trainable neural network, such as multi-layer perceptron, a simple concatenation as following still shows good performance in our experiments: �(h; ~u;~ h) = [h; ~u; h � ~u; h � ~ h] 2 R8d�T (i.e., dG = 8d).
- 5. Modeling Layer.
The input to the modeling layer is G, which encodes the query-aware representations of context words. The output of the modeling layer captures the interaction among the context words conditioned on the query. This is different from the contextual embedding layer, which captures the interaction among context words independent of the query. We use two layers of bi-directional LSTM, with the output size of d for each direction. Hence we obtain a matrix M 2 R2d�T , which is passed onto the output layer to predict the answer. Each column vector of M is expected to contain contextual information about the word with respect to the entire context paragraph and the query.
- 6. Output Layer.
The output layer is application-specific. The modular nature of BIDAF allows us to easily swap out the output layer based on the task, with the rest of the architecture remaining exactly the same. Here, we describe the output layer for the QA task. In section 5, we use a slight modification of this output layer for cloze-style comprehension. The QA task requires the model to find a sub-phrase of the paragraph to answer the query. The phrase is derived by predicting the start and the end indices of the phrase in the paragraph. We obtain the probability distribution of the start index over the entire paragraph by p1 = softmax(w> (p1)[G;M]); (3) where w(p1) 2 R10d is a trainable weight vector. For the end index of the answer phrase, we pass M to another bidirectional LSTM layer and obtain M2 2 R2d�T . Then we use M2 to obtain the probability distribution of the end index in a similar manner: p2 = softmax(w> (p2)[G;M2]) (4) Training. We define the training loss (to be minimized) as the sum of the negative log probabilities of the true start and end indices by the predicted distributions, averaged over all examples: L(�) = 1 N XN i log(p1 y1 i ) + log(p2 y2 i ) (5) where � is the set of all trainable weights in the model (the weights and biases of CNN filters and LSTM cells, w(S), w(p1) and w(p2)), N is the number of examples in the dataset, y1 i and y2 i are the true start and end indices of the i-th example, respectively, and pk indicates the k-th value of the vector p. Test. The answer span (k; l) where k � l with the maximum value of p1 kp2l is chosen, which can be computed in linear time with dynamic programming.
3 RELATED WORK
A significant contributor to the advancement of MC models has been the availability of large datasets. Early datasets such as MCTest (Richardson et al., 2013) were too small to train end-to-end neural models. Massive cloze test datasets (CNN/DailyMail by Hermann et al. (2015) and Childrens Book Test by Hill et al. (2016)), enabled the application of deep neural architectures to this task. More recently, Rajpurkar et al. (2016) released the Stanford Question Answering (SQuAD) dataset with over 100,000 questions. We evaluate the performance of our comprehension system on both SQuAD and CNN/DailyMail datasets.
Previous works in end-to-end machine comprehension use attention mechanisms in three distinct ways. The first group (largely inspired by Bahdanau et al. (2015)) uses a dynamic attention mechanism, in which the attention weights are updated dynamically given the query and the context as well as the previous attention. Hermann et al. (2015) argue that the dynamic attention model performs better than using a single fixed query vector to attend on context words on CNN & DailyMail datasets. Chen et al. (2016) show that simply using bilinear term for computing the attention weights in the same model drastically improves the accuracy. Wang & Jiang (2016) reverse the direction of the attention (attending on query words as the context RNN progresses) for SQuAD. In contrast to these models, BIDAF uses a memory-less attention mechanism.
The second group computes the attention weights once, which are then fed into an output layer for final prediction (e.g., Kadlec et al. (2016)). Attention-over-attention model (Cui et al., 2016) uses a 2D similarity matrix between the query and context words (similar to Equation 1) to compute the weighted average of query-to-context attention. In contrast to these models, BIDAF does not summarize the two modalities in the attention layer and instead lets the attention vectors flow into the modeling (RNN) layer.
The third group (considered as variants of Memory Network (Weston et al., 2015)) repeats computing an attention vector between the query and the context through multiple layers, typically referred to as multi-hop (Sordoni et al., 2016; Dhingra et al., 2016). Shen et al. (2016) combine Memory Networks with Reinforcement Learning in order to dynamically control the number of hops. One can also extend our BIDAF model to incorporate multiple hops.
The task of question answering has also gained a lot of interest in the computer vision community. Early works on visual question answering (VQA) involved encoding the question using an RNN, encoding the image using a CNN and combining them to answer the question (Antol et al., 2015; Malinowski et al., 2015). Attention mechanisms have also been successfully employed for the VQA task and can be broadly clustered based on the granularity of their attention and the approach to construct the attention matrix. At the coarse level of granularity, the question attends to different patches in the image (Zhu et al., 2016; Xiong et al., 2016a). At a finer level, each question word attends to each image patch and the highest attention value for each spatial location (Xu & Saenko, 2016) is adopted. A hybrid approach is to combine questions representations at multiple levels of granularity (unigrams, bigrams, trigrams) (Yang et al., 2015). Several approaches to constructing the attention matrix have been used including element-wise product, element-wise sum, concatenation and Multimodal Compact Bilinear Pooling (Fukui et al., 2016). Lu et al. (2016) have recently shown that in addition to attending from the question to image patches, attending from the image back to the question words provides an improvement on the VQA task. This finding in the visual domain is consistent with our finding in the language domain, where our bi-directional attention between the query and context provides improved results. Their model, however, uses the attention weights directly in the output layer and does not take advantage of the attention flow to the modeling layer.
4 QUESTION ANSWERING EXPERIMENTS
In this section, we evaluate our model on the task of question answering using the recently released SQuAD (Rajpurkar et al., 2016), which has gained a huge attention over a few months. In the next section, we evaluate our model on the task of cloze-style reading comprehension.
- Dataset
SQuAD is a machine comprehension dataset on a large set of Wikipedia articles, with more than 100,000 questions. The answer to each question is always a span in the context. The model is given a credit if its answer matches one of the human written answers. Two metrics are used to evaluate models: Exact Match (EM) and a softer metric, F1 score, which measures the weighted average of the precision and recall rate at character level. The dataset consists of 90k/10k train/dev question-context tuples with a large hidden test set. It is one of the largest available MC datasets with human-written questions and serves as a great test bed for our model.
…
…
6 CONCLUSION
In this paper, we introduce BIDAF, a multi-stage hierarchical process that represents the context at different levels of granularity and uses a bi-directional attention flow mechanism to achieve a queryaware context representation without early summarization. The experimental evaluations show that our model achieves the state-of-the-art results in Stanford Question Answering Dataset (SQuAD) and CNN/DailyMail cloze test. The ablation analyses demonstrate the importance of each component in our model. The visualizations and discussions show that our model is learning a suitable representation for MC and is capable of answering complex questions by attending to correct locations in the given paragraph. Future work involves extending our approach to incorporate multiple hops of the attention layer.
References
- Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C Lawrence Zitnick, and Devi Parikh. Vqa: Visual question answering. In ICCV, 2015.
- Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate. ICLR, 2015.
- Danqi Chen, Jason Bolton, and Christopher D. Manning. A thorough examination of the cnn/daily mail reading comprehension task. In ACL, 2016.
- Yiming Cui, Zhipeng Chen, Si Wei, Shijin Wang, Ting Liu, and Guoping Hu. Attention-overattention neural networks for reading comprehension. arXiv preprint arXiv:1607.04423, 2016.
- Bhuwan Dhingra, Hanxiao Liu, William W Cohen, and Ruslan Salakhutdinov. Gated-attention readers for text comprehension. arXiv preprint arXiv:1606.01549, 2016.
- Akira Fukui, Dong Huk Park, Daylen Yang, Anna Rohrbach, Trevor Darrell, and Marcus Rohrbach. Multimodal compact bilinear pooling for visual question answering and visual grounding. In EMNLP, 2016.
- Karl Moritz Hermann, Tom´as Kocisk´y, Edward Grefenstette, Lasse Espeholt, Will Kay, Mustafa Suleyman, and Phil Blunsom. Teaching machines to read and comprehend. In NIPS, 2015.
- Felix Hill, Antoine Bordes, Sumit Chopra, and Jason Weston. The goldilocks principle: Reading children’s books with explicit memory representations. In ICLR, 2016.
- Sepp Hochreiter and Jurgen Schmidhuber. Long short-term memory. Neural Computation, 1997.
- Rudolf Kadlec, Martin Schmid, Ondrej Bajgar, and Jan Kleindienst. Text understanding with the attention sum reader network. In ACL, 2016
- Yoon Kim. Convolutional neural networks for sentence classification. In EMNLP, 2014.
- Sosuke Kobayashi, Ran Tian, Naoaki Okazaki, and Kentaro Inui. Dynamic entity representation with max-pooling improves machine reading. In NAACL-HLT, 2016.
- Jiasen Lu, Jianwei Yang, Dhruv Batra, and Devi Parikh. Hierarchical question-image co-attention for visual question answering. In NIPS, 2016.
- Mateusz Malinowski, Marcus Rohrbach, and Mario Fritz. Ask your neurons: A neural-based approach to answering questions about images. In ICCV, 2015.
- Jeffrey Pennington, Richard Socher, and Christopher D Manning. Glove: Global vectors for word representation. In EMNLP, 2014.
- Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. Squad: 100,000+ questions for machine comprehension of text. In EMNLP, 2016.
- Matthew Richardson, Christopher JC Burges, and Erin Renshaw. Mctest: A challenge dataset for the open-domain machine comprehension of text. In EMNLP, 2013.
- Yelong Shen, Po-Sen Huang, Jianfeng Gao, and Weizhu Chen. Reasonet: Learning to stop reading in machine comprehension. arXiv preprint arXiv:1609.05284, 2016.
- Alessandro Sordoni, Phillip Bachman, and Yoshua Bengio. Iterative alternating neural attention for machine reading. arXiv preprint arXiv:1606.02245, 2016.
- Nitish Srivastava, Geoffrey E. Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. Dropout: a simple way to prevent neural networks from overfitting. JMLR, 2014.
- Rupesh Kumar Srivastava, Klaus Greff, and J¨urgen Schmidhuber. Highway networks. arXiv preprint arXiv:1505.00387, 2015.
- Adam Trischler, Zheng Ye, Xingdi Yuan, and Kaheer Suleman. Natural language comprehension with the epireader. In EMNLP, 2016.
- Shuohang Wang and Jing Jiang. Machine comprehension using match-lstm and answer pointer. arXiv preprint arXiv:1608.07905, 2016.
- Jason Weston, Sumit Chopra, and Antoine Bordes. Memory networks. In ICLR, 2015.
- Caiming Xiong, Stephen Merity, and Richard Socher. Dynamic memory networks for visual and textual question answering. In ICML, 2016a.
- Caiming Xiong, Victor Zhong, and Richard Socher. Dynamic coattention networks for question answering. arXiv preprint arXiv:1611.01604, 2016b.
- Huijuan Xu and Kate Saenko. Ask, attend and answer: Exploring question-guided spatial attention for visual question answering. In ECCV, 2016.
- Zhilin Yang, Bhuwan Dhingra, Ye Yuan, Junjie Hu, William W Cohen, and Ruslan Salakhutdinov. Words or characters? fine-grained gating for reading comprehension. arXiv preprint arXiv:1611.01724, 2016.
- Zichao Yang, Xiaodong He, Jianfeng Gao, Li Deng, and Alex Smola. Stacked attention networks for image question answering. arXiv preprint arXiv:1511.02274, 2015.
- Yang Yu, Wei Zhang, Kazi Hasan, Mo Yu, Bing Xiang, and Bowen Zhou. End-to-end reading comprehension with dynamic answer chunk ranking. arXiv preprint arXiv:1610.09996, 2016.
- Matthew D Zeiler. Adadelta: an adaptive learning rate method. arXiv preprint arXiv:1212.5701, 2012.
- Yuke Zhu, Oliver Groth, Michael S. Bernstein, and Li Fei-Fei. Visual7w: Grounded question answering in images. In CVPR, 2016.
;
| Author | volume | Date Value | title | type | journal | titleUrl | doi | note | year | |
|---|---|---|---|---|---|---|---|---|---|---|
| 2017 BidirectionalAttentionFlowforMa | Ali Farhadi Minjoon Seo Aniruddha Kembhavi Hannaneh Hajishirzi | Bidirectional Attention Flow for Machine Comprehension | 2017 |