AlphaGo Zero System
Jump to navigation
Jump to search
An AlphaGo Zero System is a Go-playing AI agent within the Alpha Go project first release in ~Oct, 2017.
- Context:
- It can (typically) be based on self-playing reinforcement learning.
- …
- Example(s):
- Counter-Example(s):
- See: DeepMind, Go Software, AlphaGo, Nature (Journal).
References
2017d
- http://www.barrons.com/articles/artificial-intelligences-winners-and-losers-1509761253
- QUOTE: The rise of these machines will lift demand for certain computer components. Just the one AlphaGo Zero system required about $25 million in hardware, including custom A.I.-processing chips designed by Google.
2017a
- (Wikipedia, 2017) ⇒ https://en.wikipedia.org/wiki/AlphaGo_Zero Retrieved:2017-10-22.
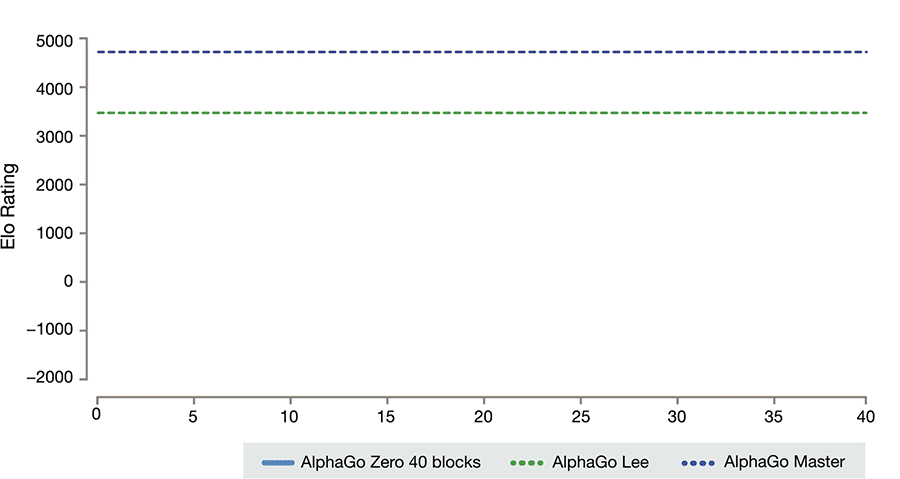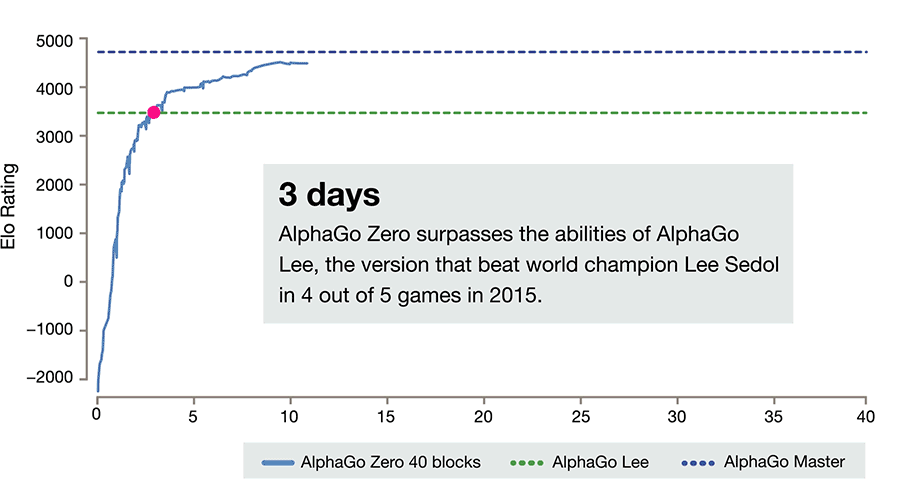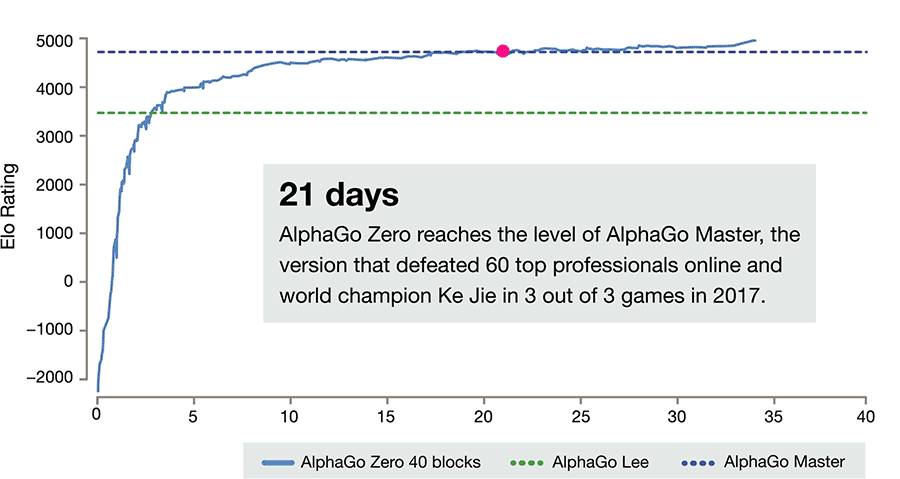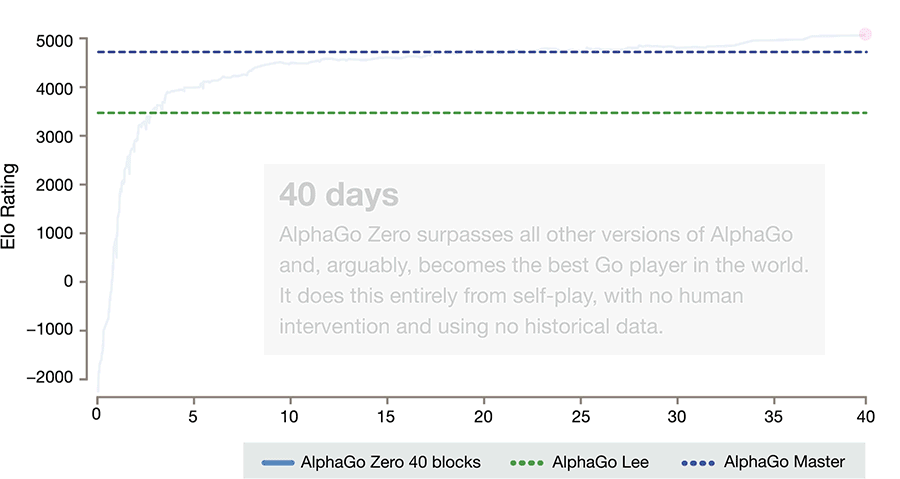
- AlphaGo Zero is a version of DeepMind's Go software AlphaGo. AlphaGo's team published an article in the journal Nature on 19 October 2017, introducing AlphaGo Zero, a version created without using data from human games, and stronger than any previous version. By playing games against itself, AlphaGo Zero surpassed the strength of AlphaGo Lee in three days by winning 100 games to 0, reached the level of AlphaGo Master in 21 days, and exceeded all the old versions in 40 days.
Training artificial intelligence (AI) without datasets derived from human experts has significant implications for the development of AI with superhuman skills because expert data is "often expensive, unreliable or simply unavailable.” Demis Hassabis, the co-founder and CEO of DeepMind, said that AlphaGo Zero was so powerful because it was "no longer constrained by the limits of human knowledge". David Silver, one of the first authors of DeepMind's papers published in Nature on AlphaGo, said that it is possible to have generalised AI algorithms by removing the need to learn from humans.
- AlphaGo Zero is a version of DeepMind's Go software AlphaGo. AlphaGo's team published an article in the journal Nature on 19 October 2017, introducing AlphaGo Zero, a version created without using data from human games, and stronger than any previous version. By playing games against itself, AlphaGo Zero surpassed the strength of AlphaGo Lee in three days by winning 100 games to 0, reached the level of AlphaGo Master in 21 days, and exceeded all the old versions in 40 days.
2017b
- (Wikipedia, 2017) ⇒ https://en.wikipedia.org/wiki/AlphaGo_Zero#Comparison_with_predecessors Retrieved:2017-10-22.
| Versions | Hardware | Elo rating | Matches |
|---|---|---|---|
| AlphaGo Fan | 176 GPUs, distributed | 3,144 | 5:0 against Fan Hui |
| AlphaGo Lee | 48 TPUs, distributed | 3,739 | 4:1 against Lee Sedol |
| AlphaGo Master | 4 TPUs v2, single machine | 4,858 | 60:0 against professional players; |
| AlphaGo Zero | 4 TPUs v2, single machine | 5,185 | 100:0 against AlphaGo Lee
89:11 against AlphaGo Master |
2017c
- https://deepmind.com/blog/alphago-zero-learning-scratch/
- QUOTE: It also differs from previous versions in other notable ways.
- AlphaGo Zero only uses the black and white stones from the Go board as its input, whereas previous versions of AlphaGo included a small number of hand-engineered features.
- It uses one neural network rather than two. Earlier versions of AlphaGo used a “policy network” to select the next move to play and a ”value network” to predict the winner of the game from each position. These are combined in AlphaGo Zero, allowing it to be trained and evaluated more efficiently.
- AlphaGo Zero does not use “rollouts” - fast, random games used by other Go programs to predict which player will win from the current board position. Instead, it relies on its high quality neural networks to evaluate positions.
- QUOTE: It also differs from previous versions in other notable ways.
2017d
- (Silver et al., 2017) ⇒ David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou, Aja Huang, Arthur Guez, Thomas Hubert, Lucas Baker, Matthew Lai, Adrian Bolton, Yutian Chen, Timothy Lillicrap, Fan Hui, Laurent Sifre, George van den Driessche, Thore Graepel, and Demis Hassabis. (2017). “Mastering the Game of Go Without Human Knowledge.” In: Nature, 550(7676).
- QUOTE: Our program, AlphaGo Zero, differs from AlphaGo Fan and AlphaGo Lee (12) in several important aspects. First and foremost, it is trained solely by self-play reinforcement learning, starting from random play, without any supervision or use of human data. Second, it only uses the black and white stones from the board as input features. Third, it uses a single neural network, rather than separate policy and value networks. Finally, it uses a simpler tree search that relies upon this single neural network to evaluate positions and sample moves, without performing any Monte-Carlo rollouts. To achieve these results, we introduce a new reinforcement learning algorithm that incorporates lookahead search inside the training loop, resulting in rapid improvement and precise and stable learning. Further technical differences in the search algorithm, training procedure and network architecture are described in Methods.
- ↑ "【柯洁战败解密】AlphaGo Master最新架构和算法,谷歌云与TPU拆解" (in Chinese). Sohu. 24 May 2017. http://www.sohu.com/a/143092581_473283. Retrieved 1 June 2017.