Distributional Word Embedding Modeling Task
Jump to navigation
Jump to search
A Distributional Word Embedding Modeling Task is a continuous dense distributional word model creation task that is a continuous word vector space model training task (that requires a continuous dense distributional word model/distributional continuous dense word model).
- Context:
- It can range from (typically) being a Data-Driven Distributional Continuous Dense Word Modeling Task to being a Heuristic Distributional Continuous Dense Word Modeling Task.
- It can be solved by a Continuous Dense Distributional Word Model Training System (that implements a continuous dense distributional word model training algorithm).
- …
- Example(s):
- e.g. “
Embed” =>[0.271, 0.729, 0.0180, ...]. - …
- e.g. “
- Counter-Example(s):
- See: word2vec System, Distributional Dense Word Model Training, Distributional Continuous Word Model Training, Distributional Continuous Dense Word Modeling System.
References
2013
- http://google-opensource.blogspot.be/2013/08/learning-meaning-behind-words.html
- QUOTE: Word2vec uses distributed representations of text to capture similarities among concepts. For example, it understands that Paris and France are related the same way Berlin and Germany are (capital and country), and not the same way Madrid and Italy are. This chart shows how well it can learn the concept of capital cities, just by reading lots of news articles -- with no human supervision:
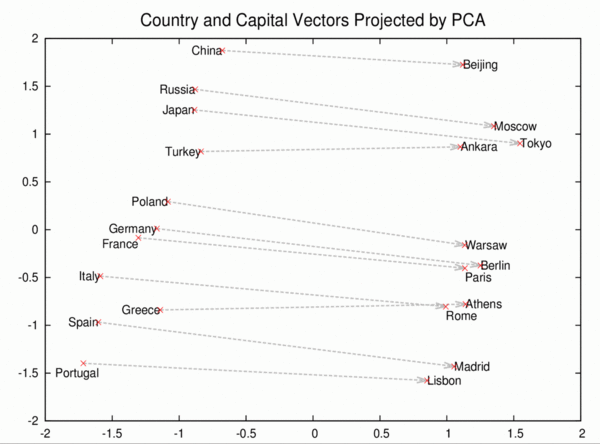
The model not only places similar countries next to each other, but also arranges their capital cities in parallel. The most interesting part is that we didn’t provide any supervised information before or during training. Many more patterns like this arise automatically in training.This has a very broad range of potential applications: knowledge representation and extraction; machine translation; question answering; conversational systems; and many others. We’re open sourcing the code for computing these text representations efficiently (on even a single machine) so the research community can take these models further.
- QUOTE: Word2vec uses distributed representations of text to capture similarities among concepts. For example, it understands that Paris and France are related the same way Berlin and Germany are (capital and country), and not the same way Madrid and Italy are. This chart shows how well it can learn the concept of capital cities, just by reading lots of news articles -- with no human supervision:
