kappa Measure of Agreement Statistic
(Redirected from kappa statistic)
A kappa Measure of Agreement Statistic is an measure of classification agreement that ...
- AKA: κ.
- Context:
- Example(s):
- Cohen's kappa.
- Fleiss' kappa.
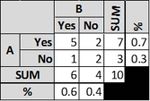
[math]\displaystyle{ Pr(a)=(5+2)/10=0.70 }[/math]
[math]\displaystyle{ Pr(e)=(.7 \times .6)+(.3 \times .4)=0.54 }[/math]
[math]\displaystyle{ κ = \frac{Pr(a)−Pr(e)}{1−Pr(e)} }[/math]
[math]\displaystyle{ κ=0.70−0.54; κ=1−0.54;κ=0.348 }[/math]
- Counter-Example(s):
- See: Classifier Performance Measure, Inter-Rater Agreement.

References
2015
- (Wikipedia, 2015) ⇒ http://en.wikipedia.org/wiki/Cohen's_kappa Retrieved:2015-4-24.
- Cohen's kappa coefficient is a statistic which measures inter-rater agreement for qualitative (categorical) items. It is generally thought to be a more robust measure than simple percent agreement calculation, since κ takes into account the agreement occurring by chance.
[1] Some researchers have expressed concern over κ's tendency to take the observed categories' frequencies as givens, which can have the effect of underestimating agreement for a category that is also commonly used; for this reason, κ is considered an overly conservative measure of agreement. Others contest the assertion that kappa "takes into account" chance agreement. To do this effectively would require an explicit model of how chance affects rater decisions. The so-called chance adjustment of kappa statistics supposes that, when not completely certain, raters simply guess — a very unrealistic scenario.
- Cohen's kappa coefficient is a statistic which measures inter-rater agreement for qualitative (categorical) items. It is generally thought to be a more robust measure than simple percent agreement calculation, since κ takes into account the agreement occurring by chance.
- ↑ Carletta, Jean. (1996) Assessing agreement on classification tasks: The kappa statistic. Computational Linguistics, 22(2), pp. 249–254.
2011
- http://en.wikipedia.org/wiki/Cohen%27s_kappa
- Cohen's kappa measures the agreement between two raters who each classify [math]\displaystyle{ N }[/math] items into [math]\displaystyle{ C }[/math] mutually exclusive categories. The first mention of a kappa-like statistic is attributed to Galton (1892). The equation for κ is: [math]\displaystyle{ \kappa = \frac{\Pr(a) - \Pr(e)}{1 - \Pr(e)}, \! }[/math] where Pr(a) is the relative observed agreement among raters, and Pr(e) is the hypothetical probability of chance agreement, using the observed data to calculate the probabilities of each observer randomly saying each category. If the raters are in complete agreement then κ = 1. If there is no agreement among the raters other than what would be expected by chance (as defined by Pr(e)), κ = 0.
2008
- (Arnstein & Poesio, 2008) ⇒ Ron Artstein, and Massimo Poesio. (2008). “Inter-Coder Agreement for Computational Linguistics.” In: Computational Linguistics, 34(4). doi:10.1162/coli.07-034-R2
- QUOTE: This article is a survey of methods for measuring agreement among corpus annotators. It exposes the mathematics and underlying assumptions of agreement coefficients, covering Krippendorff's alpha as well as Scott's pi and Cohen's kappa; discusses the use of coefficients in several annotation tasks; and argues that weighted, alpha-like coefficients, traditionally less used than kappa-like measures in computational linguistics, may be more appropriate for many corpus annotation tasks — but that their use makes the interpretation of the value of the coefficient even harder.
- (Upton & Cook, 2008) ⇒ Graham Upton, and Ian Cook. (2008). “A Dictionary of Statistics, 2nd edition revised." Oxford University Press. ISBN:0199541450
- QUOTE: Cohen's Kappa [math]\displaystyle{ (\kappa) }[/math]: A measure of agreement between two observers, suggested by Cohen in 1960. Suppose that the observers are required, independently, to assign items to one of [math]\displaystyle{ m }[/math] classes. Let [math]\displaystyle{ f_{jk} }[/math] be the number of individuals assigned to class [math]\displaystyle{ j }[/math] by the first observer and to class [math]\displaystyle{ k }[/math] by the second observer. Let [math]\displaystyle{ f_{j0} = \sum_{k=1}^{m} f_{jk}, f_{0k} = \sum_{j=1}^{m}f_{jk} and f_{00}\sum_{j=1}^{m}\sum_{k=1}^{m}f_{jk} }[/math]. Define the quantities [math]\displaystyle{ O }[/math] and [math]\displaystyle{ E }[/math] by :[math]\displaystyle{ O = \sum_{j=1}{m}f_{jj} E = \sum{j=1}{m} \frac{f_{j0}f_{0j} }{f_{00} } }[/math] so that [math]\displaystyle{ O }[/math] is the total nmnber of individuals on which the observers are in complete agreement, and E is the expected total number of agreements that would have occurred if the observers had been statistically independent. The formula for Cohen’s kappa is :[math]\displaystyle{ \kappa {O - E \over f_{00} - E} }[/math] A value of 0 indicates statistical independence, and a value of 1 indicates perfect agreement.
2010
- (Liakata et al., 2010) ⇒ Maria Liakata, Simone Teufel, Advaith Siddharthan, and Colin R. Batchelor. (2010). “Corpora for the Conceptualisation and Zoning of Scientific Papers.” In: Proceedings of LREC Conference (LREC 2010).
- QUOTE: The CoreSC corpus was developed in two different phases. During phase I, fifteen Chemistry experts were split into five groups of three, each of which annotated eight different papers; A 16th expert annotated across groups as a consistency check. This resulted in a total of 41 papers being annotated, all of which received multiple annotations. We ranked annotators according to median success in terms of inter-annotator agreement (as measured by Cohen’s (Cohen, 1960) kappa) both within their groups and for a paper common across groups.
1996
- (Carletta, 1996) ⇒ Jean Carletta. (1996). “Assessing Agreement on Classification Tasks: The kappa Statistic.” In: Computational Linguistics, 22(2).
- ABSTRACT: Currently, computational linguists and cognitive scientists working in the area of discourse and dialogue argue that their subjective judgments are reliable using several different statistics, none of which are easily interpretable or comparable to each other. Meanwhile, researchers in content analysis have already experienced the same difficulties and come up with a solution in the kappa statistic. We discuss what is wrong with reliability measures as they are currently used for discourse and dialogue work in computational linguistics and cognitive science, and argue that we would be better off as a field adopting techniques from content analysis.
1960
- (Cohen, 1960) ⇒ J. Cohen. (1960). “A Coefficient of Agreement for Nominal Scales.” In: Educational and Psychological Measurement, 20.