Collective Entity Linking System
Jump to navigation
Jump to search
A Collective Entity Linking System is a Named Entity Disambiguation System that is based on a Collective Inference Model.
- AKA: Collective Named Entity Disambiguation System, Collective Entity Disambiguation System.
- Context:
- It solves a Collective Entity Linking Task by implementing a Collective Entity Linking Algorithm.
- …
- Example(s):
- Counter-Example(s):
- See: Semantic Search System, Entity Mention, Natural Language Processing, Wikipedia, Knowledge Base.
References
2011a
- (Han et al., 2011) ⇒ Xianpei Han, Le Sun, and Jun Zhao. (2011). “Collective Entity Linking in Web Text: A Graph-based Method.” In: Proceedings of the 34th international ACM SIGIR conference on Research and development in Information Retrieval. doi:10.1145/2009916.2010019
- QUOTE: The key issue is to correctly link the name mentions in a document with their referent entities in the knowledge base, which is usually referred to as Entity Linking (EL for short). For example, in Figure 1 an entity linking system should link the name mentions “Bulls”, “Jordan” and “Space Jam” to their corresponding referent entities Chicago Bulls, Michael Jordan and Space Jam in the knowledge base.
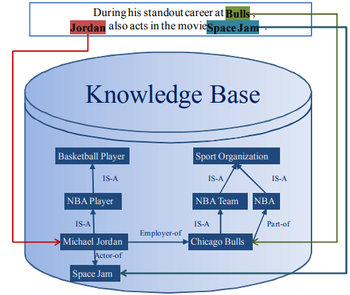
Figure 1. An illustration of entity linking.
- QUOTE: The key issue is to correctly link the name mentions in a document with their referent entities in the knowledge base, which is usually referred to as Entity Linking (EL for short). For example, in Figure 1 an entity linking system should link the name mentions “Bulls”, “Jordan” and “Space Jam” to their corresponding referent entities Chicago Bulls, Michael Jordan and Space Jam in the knowledge base.

2009
- (Kulkarni et al., 2009) ⇒ Sayali Kulkarni, Amit Singh, Ganesh Ramakrishnan, and Soumen Chakrabarti. (2009). “Collective Annotation of Wikipedia Entities in Web Text.” In: Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD-2009). doi:10.1145/1557019.1557073
- QUOTE: We proposed new models and algorithms for a highly motivated problem: annotating unstructured (Web) text with entity IDs from an entity catalog (Wikipedia). Unlike prior work that is biased toward specific entity types like persons and places, with low recall and high precision, our intention is aggressive, high-recall open-domain annotation for indexing and mining tasks downstream.