Encoder-Decoder Neural Network
An Encoder-Decoder Neural Network is a sequential bidirectional modular neural network that can support sequence transformation tasks through encoder-decoder architectures.
- AKA: Encoder-Decoder Network, Encoder-Decoder Model, Encoder/Decoder Neural Network, Seq2Seq Network.
- Context:
- It can typically transform Input Sequences into latent representations through encoder neural modules.
- It can typically generate Output Sequences from encoded representations through decoder neural modules.
- It can typically support Variable-Length Sequence Processing through dynamic encoding-decoding mechanisms.
- It can typically enable Cross-Domain Transformation between different modalities through specialized encoder-decoder pairs.
- It can typically facilitate Representation Learning through bottleneck architectures that force information compression.
- ...
- It can often incorporate Attention Mechanisms to preserve input-output alignment during sequence transformation.
- It can often utilize Copy Mechanisms to directly transfer input elements to output sequences.
- It can often implement Bidirectional Processing in encoder modules for context-aware encoding.
- It can often support Beam Search Decoding for optimal output generation during inference phase.
- ...
- It can range from being a Simple Encoder-Decoder Neural Network to being a Complex Encoder-Decoder Neural Network, depending on its encoder-decoder architectural complexity.
- It can range from being a Fixed-Length Encoder-Decoder Neural Network to being a Variable-Length Encoder-Decoder Neural Network, depending on its encoder-decoder sequence handling capability.
- It can range from being a Homogeneous Encoder-Decoder Neural Network to being a Heterogeneous Encoder-Decoder Neural Network, depending on its encoder-decoder module architecture type.
- ...
- It can be trained by Encoder-Decoder Training Systems implementing encoder-decoder training algorithms.
- It can be optimized through Teacher Forcing Training for efficient decoder learning.
- It can be enhanced with Scheduled Sampling to reduce exposure bias during encoder-decoder training.
- It can be evaluated using Sequence Evaluation Metrics such as BLEU scores and perplexity measures.
- It can be deployed in Production Encoder-Decoder Systems for real-time sequence transformation.
- ...
- Example(s):
- Recurrent-Based Encoder-Decoder Architectures, such as:
- Basic RNN Encoder-Decoder Networks, such as:
- Vanilla RNN Encoder-Decoder Network demonstrating sequential encoding-decoding for simple sequence tasks.
- LSTM Encoder-Decoder Network demonstrating long-term dependency handling through gated encoder-decoder mechanisms.
- GRU Encoder-Decoder Network demonstrating efficient sequence transformation with simplified gating structures.
- Attention-Enhanced RNN Encoder-Decoder Networks, such as:
- Bahdanau Attention Encoder-Decoder Network demonstrating soft attention mechanism for neural machine translation.
- Luong Attention Encoder-Decoder Network demonstrating global/local attention for alignment learning.
- Hierarchical Attention Encoder-Decoder Network demonstrating multi-level attention for document-level transformation.
- Basic RNN Encoder-Decoder Networks, such as:
- Convolutional-Based Encoder-Decoder Architectures, such as:
- CNN Encoder-Decoder Networks, such as:
- SegNet Encoder-Decoder Network demonstrating pixel-wise segmentation through pooling index preservation.
- U-Net Encoder-Decoder Network demonstrating biomedical image segmentation through skip connections.
- Fully Convolutional Encoder-Decoder Network demonstrating end-to-end spatial transformation.
- CNN Encoder-Decoder Networks, such as:
- Transformer-Based Encoder-Decoder Architectures, such as:
- Original Transformer Network demonstrating self-attention based transformation for parallel sequence processing.
- T5 (Text-to-Text Transfer Transformer) demonstrating unified text transformation for multi-task learning.
- BART (Bidirectional and Auto-Regressive Transformer) demonstrating denoising sequence reconstruction for text generation tasks.
- Hybrid Encoder-Decoder Architectures, such as:
- CNN-RNN Encoder-Decoder Network demonstrating spatial-temporal transformation for video captioning tasks.
- Pointer-Generator Network demonstrating hybrid generation mechanism combining abstractive and extractive approachs.
- Graph-to-Sequence Encoder-Decoder Network demonstrating structured data transformation for AMR parsing tasks.
- Domain-Specific Encoder-Decoder Applications, such as:
- Neural Machine Translation Systems demonstrating cross-lingual transformation.
- Speech Recognition Encoder-Decoder Systems demonstrating audio-to-text transformation.
- Image Captioning Encoder-Decoder Systems demonstrating visual-to-textual transformation.
- Grammatical Error Correction Systems demonstrating text refinement transformation.
- ...
- Recurrent-Based Encoder-Decoder Architectures, such as:
- Counter-Example(s):
- Encoder-Only Neural Network, which processes input sequences without output generation capability.
- Decoder-Only Neural Network, which generates output sequences without explicit input encoding phase.
- Feed-Forward Neural Network, which lacks sequential processing capability and modular encoder-decoder structure.
- End-to-End Neural Network, which performs direct transformation without intermediate representation bottleneck.
- Siamese Neural Network, which compares multiple inputs rather than transforming single sequences.
- See: Sequence-to-Sequence Learning, Neural Machine Translation, Attention Mechanism, Autoencoder Network, Transformer Architecture, Recurrent Neural Network, Convolutional Neural Network.
References
2018a
- (Liao et al., 2018) ⇒ Binbing Liao, Jingqing Zhang, Chao Wu, Douglas McIlwraith, Tong Chen, Shengwen Yang, Yike Guo, and Fei Wu. (2018). “Deep Sequence Learning with Auxiliary Information for Traffic Prediction.” In: Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. ISBN:978-1-4503-5552-0 doi:10.1145/3219819.3219895
- QUOTE: In this paper, we effectively utilise three kinds of auxiliary information in an encoder-decoder sequence to sequence (Seq2Seq) [7, 32] learning manner as follows: a wide linear model is used to encode the interactions among geographical and social attributes, a graph convolution neural network is used to learn the spatial correlation of road segments, and the query impact is quantified and encoded to learn the potential influence of online crowd queries(...)
Figure 4 shows the architecture of the Seq2Seq model for traffic prediction. The encoder embeds the input traffic speed sequence [math]\displaystyle{ \{v_1,v_2, \cdots, v_t \} }[/math] and the final hidden state of the encoder is fed into the decoder, which learns to predict the future traffic speed [math]\displaystyle{ \{\tilde{v}_{t+1},\tilde{v}_{t+2}, \cdots,\tilde{v}_{t+t'} \} }[/math]. Hybrid model that integrates the auxiliary information will be proposed based on the Seq2Seq model.
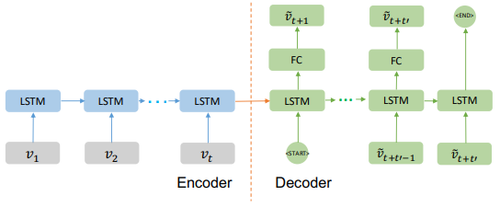
Figure 4: Seq2Seq: The Sequence to Sequence model predicts future traffic speed [math]\displaystyle{ \{\tilde{v}_{t+1},\tilde{v}_{t+2}, \cdots ,\tilde{v}_{t+t'} \} }[/math], given the previous traffic speed [math]\displaystyle{ {v_1,v_2, ...v_t } }[/math].
- QUOTE: In this paper, we effectively utilise three kinds of auxiliary information in an encoder-decoder sequence to sequence (Seq2Seq) [7, 32] learning manner as follows: a wide linear model is used to encode the interactions among geographical and social attributes, a graph convolution neural network is used to learn the spatial correlation of road segments, and the query impact is quantified and encoded to learn the potential influence of online crowd queries(...)

2018b
- (Saxena, 2018) ⇒ Rohan Saxena (April, 2018). "What is an Encoder/Decoder in Deep Learning?". In: Quora.
- QUOTE: Some network architectures explicitly aim to leverage this ability of neural networks to learn efficient representations. They use an encoder network to map raw inputs to feature representations, and a decoder network to take this feature representation as input, process it to make its decision, and produce an output. This is called an encoder-decoder network. ...
In a CNN, an encoder-decoder network typically looks like this (a CNN encoder and a CNN decoder):
Image Credits: (Badrinarayanan et al., 2017)
...In an RNN, an encoder-decoder network typically looks like this (an RNN encoder and an RNN decoder):
...We can mix and match and use a CNN encoder with RNN decoder, or vice versa; any combination can be used which is suitable for the given task.
An example from a paper I recently implemented from scratch, Text-guided Attention Model for Image Captioning (T-ATT):
- QUOTE: Some network architectures explicitly aim to leverage this ability of neural networks to learn efficient representations. They use an encoder network to map raw inputs to feature representations, and a decoder network to take this feature representation as input, process it to make its decision, and produce an output. This is called an encoder-decoder network.
2017a
- (Ramachandran et al., 2017) ⇒ Prajit Ramachandran, Peter J. Liu, and Quoc V. Le. (2017). “Unsupervised Pretraining for Sequence to Sequence Learning.” In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing (EMNLP 2017). arViv:1611.02683
- QUOTE: Therefore, the basic procedure of our approach is to pretrain both the seq2seq encoder and decoder networks with language models, which can be trained on large amounts of unlabeled text data. This can be seen in Figure 1, where the parameters in the shaded boxes are pretrained. In the following we will describe the method in detail using machine translation as an example application.
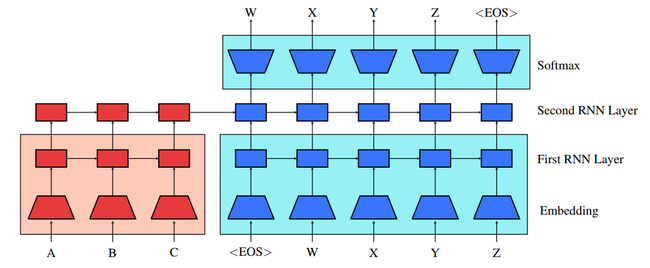
Figure 1: Pretrained sequence to sequence model. The red parameters are the encoder and the blue parameters are the decoder. All parameters in a shaded box are pretrained, either from the source side (light red) or target side (light blue) language model. Otherwise, they are randomly initialized.
- QUOTE: Therefore, the basic procedure of our approach is to pretrain both the seq2seq encoder and decoder networks with language models, which can be trained on large amounts of unlabeled text data. This can be seen in Figure 1, where the parameters in the shaded boxes are pretrained. In the following we will describe the method in detail using machine translation as an example application.

2017b
- (Badrinarayanan et al., 2017) ⇒ Vijay Badrinarayanan, Alex Kendall, and Roberto Cipolla. (2017). “SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation.” In: IEEE Transactions on Pattern Analysis and Machine Intelligence, 39(12). doi:10.1109/TPAMI.2016.2644615
2016a
- (Cucurull, 2016) ⇒ Guillem Cucurull (May 3, 2016). “What is the SegNet neural network? Why is it important?."
- QUOTE: It is a convolutional neural network (CNN) that performs image segmentation. This means that the network learns to assign each pixel a class depending on the object or surface it belongs, e.g a car, highway, tree, building...
It uses an Encoder-Decoder architecture, were the image is first down-sampled by an encoder as in a "traditional" CNN like VGG, and then it is upsampled by using a decoder that is like a reversed CNN, with upsampling layers instead of pooling layers.
- QUOTE: It is a convolutional neural network (CNN) that performs image segmentation. This means that the network learns to assign each pixel a class depending on the object or surface it belongs, e.g a car, highway, tree, building...
2016b
- (Schnober et al., 2016) ⇒ Carsten Schnober, Steffen Eger, Erik-Lan Do Dinh, and Iryna Gurevych. (2016). “Still Not There? Comparing Traditional Sequence-to-Sequence Models to Encoder-Decoder Neural Networks on Monotone String Translation Tasks.” In: Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers.
- QUOTE: We compare three variants of encoder-decoder models: the ‘classic’ variant and two modifications:
enc-dec: Encoder-decoder models using recurrent neural networks (RNNs) for Seq2Seq tasks were introduced by Cho et al. (2014) and Sutskever et al. (2014) (...)attn-enc-dec: We explore the attention-based encoder-decoder model proposed by Bahdanau et al. (2014) (Figure 1). It extends the encoder-decoder model by learning to align and translate jointly (...)morph-trans: Faruqui et al. (2016) present a new encoder-decoder model designed for morphological inflection, proposing to feed the input sequence directly into the decoder. This approach is motivated by the observation that input and output are usually very similar in problems such as morphological inflection (...)
- QUOTE: We compare three variants of encoder-decoder models: the ‘classic’ variant and two modifications:

2016c
- (Faruqui et al., 2016) ⇒ Manaal Faruqui, Yulia Tsvetkov, Graham Neubig, and Chris Dyer. (2016). “Morphological Inflection Generation Using Character Sequence to Sequence Learning.” In: Proceedings of the 2016 Conference of the North {{American Chapter of the Association for Computational Linguistics: Human Language Technologies. DOI:10.18653/v1/N16-1077
2016d
- (Gu et al., 2016) ⇒ Jiatao Gu, Zhengdong Lu, Hang Li, and Victor O.K. Li. (2016). “Incorporating Copying Mechanism in Sequence-to-Sequence Learning.” In: Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). doi:10.18653/v1/P16-1154
2015
- (Bahdanau et al., 2015) ⇒ Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. (2015). “Neural Machine Translation by Jointly Learning to Align and Translate.” In: Proceedings of the Third International Conference on Learning Representations, (ICLR-2015).
2014a
- (Sutskever et al., 2014) ⇒ Ilya Sutskever, Oriol Vinyals, and Quoc V. Le. (2014). “Sequence to Sequence Learning with Neural Networks.” In: Advances in Neural Information Processing Systems. arXiv:1409.321
2014b
- (Cho et al., 2014a) ⇒ Kyunghyun Cho, Bart van Merrienboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. (2014). “Learning Phrase Representations Using RNN Encoder-Decoder for Statistical Machine Translation”. In: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, (EMNLP-2014). arXiv:1406.1078
- QUOTE: In this paper, we propose a novel neural network architecture that learns to encode a variable-length sequence into a fixed-length vector representation and to decode a given fixed-length vector representation back into a variable-length sequence.