File:2018 BERTPreTrainingofDeepBidirectio Fig1.png
Jump to navigation
Jump to search
Size of this preview: 800 × 184 pixels. Other resolution: 1,194 × 274 pixels.
{kind=link}
Original file (1,194 × 274 pixels, file size: 85 KB, MIME type: image/png)
Summary
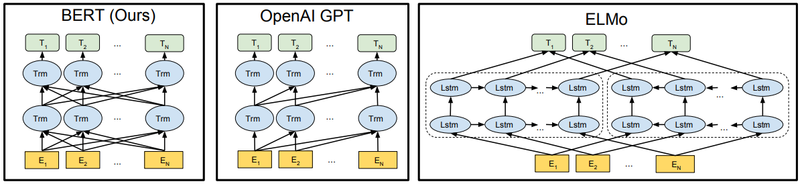
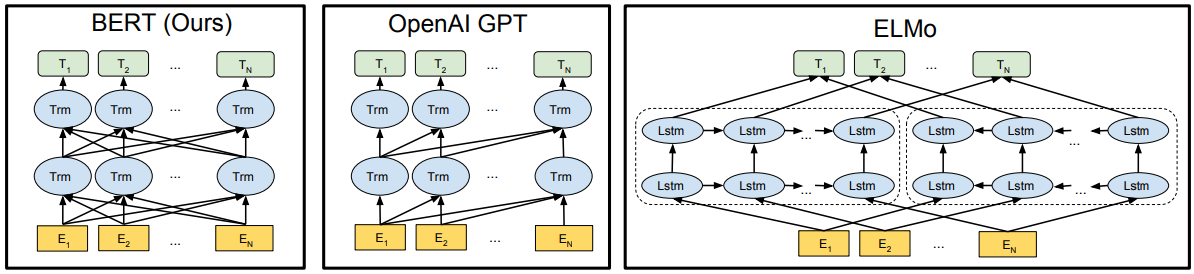
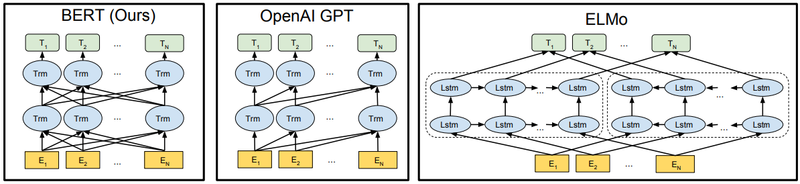
Figure 1: Differences in pre-training model architectures. BERT uses a bidirectional Transformer. OpenAI GPT uses a left-to-right Transformer. ELMo uses the concatenation of independently trained left-to-right and rightto-left LSTM to generate features for downstream tasks. Among three, only BERT representations are jointly conditioned on both left and right context in all layers.
Copyright: Devlin et al. (2018).
File history
Click on a date/time to view the file as it appeared at that time.
| Date/Time | Thumbnail | Dimensions | User | Comment | |
|---|---|---|---|---|---|
| current | 05:03, 28 April 2019 | 1,194 × 274 (85 KB) | Omoreira (talk | contribs) | <B>Figure 1:</B> Differences in pre-training model architectures. BERT uses a bidirectional Transformer. OpenAI GPT uses a left-to-right Transformer. ELMo uses the concatenation of independently trained left-to-right and rig... |
You cannot overwrite this file.
File usage
The following 5 pages use this file:
{kind=link}