Long Short-Term Memory (LSTM) Unit
A Long Short-Term Memory (LSTM) Unit is a recurrent neural network unit composed of an memory cell, an input gate, a forget gate, and an output gate.
- AKA: LSTM Cell.
- Context:
- It can (typically) be a part of an LSTM Network.
- Example(s):
- Counter-Example(s):
- a GRU Unit.
- a Standard RNN Unit.
- See: LSTM Training Algorithm.

References
2018a
- (Wikipedia, 2018) ⇒ https://en.wikipedia.org/wiki/long_short-term_memory Retrieved:2018-3-27.
- Long short-term memory (LSTM) units (or blocks) are a building unit for layers of a recurrent neural network (RNN). A RNN composed of LSTM units is often called an LSTM network. A common LSTM unit is composed of a cell, an input gate, an output gate and a forget gate. The cell is responsible for "remembering" values over arbitrary time intervals; hence the word "memory" in LSTM. Each of the three gates can be thought of as a "conventional" artificial neuron, as in a multi-layer (or feedforward) neural network: that is, they compute an activation (using an activation function) of a weighted sum. Intuitively, they can be thought as regulators of the flow of values that goes through the connections of the LSTM; hence the denotation "gate". There are connections between these gates and the cell.
The expression long short-term refers to the fact that LSTM is a model for the short-term memory which can last for a long period of time. An LSTM is well-suited to classify, process and predict time series given time lags of unknown size and duration between important events. LSTMs were developed to deal with the exploding and vanishing gradient problem when training traditional RNNs. Relative insensitivity to gap length gives an advantage to LSTM over alternative RNNs, hidden Markov models and other sequence learning methods in numerous applications.
- Long short-term memory (LSTM) units (or blocks) are a building unit for layers of a recurrent neural network (RNN). A RNN composed of LSTM units is often called an LSTM network. A common LSTM unit is composed of a cell, an input gate, an output gate and a forget gate. The cell is responsible for "remembering" values over arbitrary time intervals; hence the word "memory" in LSTM. Each of the three gates can be thought of as a "conventional" artificial neuron, as in a multi-layer (or feedforward) neural network: that is, they compute an activation (using an activation function) of a weighted sum. Intuitively, they can be thought as regulators of the flow of values that goes through the connections of the LSTM; hence the denotation "gate". There are connections between these gates and the cell.
2018b
- (Thomas, 2018) ⇒ Andy Thomas (2018). "A brief introduction to LSTM networks" from Adventures in Machine Learning Retrieved:2018-7-8.
- QUOTE: As mentioned previously, in this Keras LSTM tutorial we will be building an LSTM network for text prediction. An LSTM network is a recurrent neural network that has LSTM cell blocks in place of our standard neural network layers. These cells have various components called the input gate, the forget gate and the output gate – these will be explained more fully later. Here is a graphical representation of the LSTM cell:

LSTM cell diagram
2018c
- (Jurasky & Martin, 2018) ⇒ Daniel Jurafsky, and James H. Martin (2018). "Chapter 9 -- Sequence Processing with Recurrent Networks". In: Speech and Language Processing (3rd ed. draft). Draft of September 23, 2018.
2017
- Brandon Rohrer. (2017). “Recurrent Neural Networks (RNN) and Long Short-Term Memory (LSTM)." YouTube video, Jun 27, 2017
- QUOTE: A gentle walk through how they work and how they are useful.
2016
- (Ma & Hovy, 2016) ⇒ Xuezhe Ma, and Eduard Hovy (2016). "End-to-end sequence labeling via bi-directional lstm-cnns-crf". arXiv preprint arXiv:1603.01354.
- QUOTE: Basically, a LSTM unit is composed of three multiplicative gates which control the proportions of information to forget and to pass on to the next time step. Figure 2 gives the basic structure of an LSTM unit. .
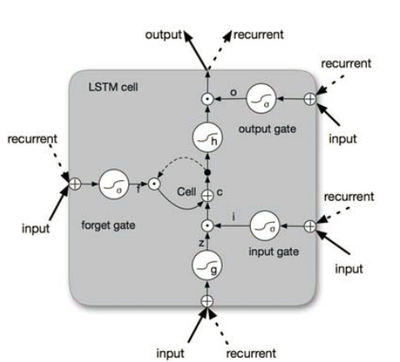
Figure 2: Schematic of LSTM unit
- QUOTE: Basically, a LSTM unit is composed of three multiplicative gates which control the proportions of information to forget and to pass on to the next time step. Figure 2 gives the basic structure of an LSTM unit.

2015a
- (Olah, 2015) ⇒ Christopher Olah (2015). “Understanding LSTM Networks" from http://colah.github.io/posts/2015-08-Understanding-LSTMs/
- QUOTE: All recurrent neural networks have the form of a chain of repeating modules of neural network. In standard RNNs, this repeating module will have a very simple structure, such as a single tanh layer. The repeating module in a standard RNN contains a single layer.

LSTMs also have this chain like structure, but the repeating module has a different structure. Instead of having a single neural network layer, there are four, interacting in a very special way.


In the above diagram, each line carries an entire vector, from the output of one node to the inputs of others. The pink circles represent pointwise operations, like vector addition, while the yellow boxes are learned neural network layers. Lines merging denote concatenation, while a line forking denote its content being copied and the copies going to different locations.
- QUOTE: All recurrent neural networks have the form of a chain of repeating modules of neural network. In standard RNNs, this repeating module will have a very simple structure, such as a single tanh layer. The repeating module in a standard RNN contains a single layer.
2015b
- (Huang et al., 2015) ⇒ Zhiheng Huang, Wei Xu, and Kai Yu. (2015). “Bidirectional LSTM-CRF Models for Sequence Tagging.” In: arXiv preprint [arXiv:1508.01991].
- QUOTE: Long Short-Term Memory networks are the same as RNNs, except that the hidden layer updates are replaced by purpose-built memory cells. As a result, they may be better at finding and exploiting long range dependencies in the data. Fig. 2 illustrates a single LSTM memory cell (Graves et al., 2005).
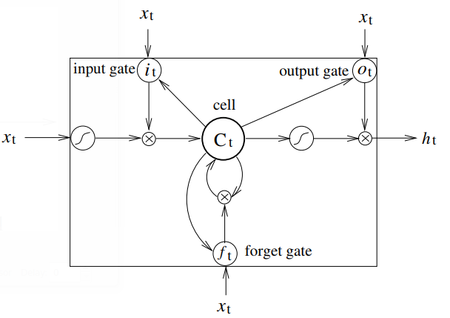
Figure 2: A Long Short-Term Memory Cell.
- QUOTE: Long Short-Term Memory networks are the same as RNNs, except that the hidden layer updates are replaced by purpose-built memory cells. As a result, they may be better at finding and exploiting long range dependencies in the data. Fig. 2 illustrates a single LSTM memory cell (Graves et al., 2005).

2014
- (Chung et al., 2014) ⇒ Junyoung Chung, Caglar Gulcehre, KyungHyun Cho, and Yoshua Bengio. (2014). "Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling". In: Proceedings of the Deep Learning and Representation Learning Workshop at NIPS 2014.
- QUOTE: Unlike to the traditional recurrent unit which overwrites its content at each time-step (see Eq. (2)), an LSTM unit is able to decide whether to keep the existing memory via the introduced gates. Intuitively, if the LSTM unit detects an important feature from an input sequence at early stage, it easily carries this information (the existence of the feature) over a long distance, hence, capturing potential long-distance dependencies.
See Fig. 1 (a) for the graphical illustration.
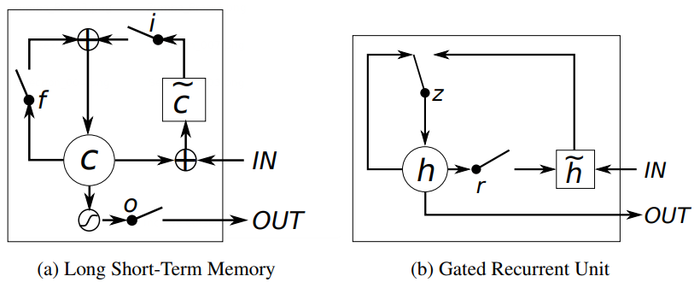
- QUOTE: Unlike to the traditional recurrent unit which overwrites its content at each time-step (see Eq. (2)), an LSTM unit is able to decide whether to keep the existing memory via the introduced gates. Intuitively, if the LSTM unit detects an important feature from an input sequence at early stage, it easily carries this information (the existence of the feature) over a long distance, hence, capturing potential long-distance dependencies.

- Figure 1: Illustration of (a) LSTM and (b) gated recurrent units. (a) [math]\displaystyle{ i }[/math], [math]\displaystyle{ f }[/math] and [math]\displaystyle{ o }[/math] are the input, forget and output gates, respectively. [math]\displaystyle{ c }[/math] and [math]\displaystyle{ \tilde{c} }[/math] denote the memory cell and the new memory cell content. (b) [math]\displaystyle{ r }[/math] and [math]\displaystyle{ z }[/math] are the reset and update gates, and [math]\displaystyle{ h }[/math] and [math]\displaystyle{ \tilde{h} }[/math] are the activation and the candidate activation.
2013
- (Graves, 2013) ⇒ Alex Graves. (2013). “Generating Sequences With Recurrent Neural Networks.” In: CoRR, abs/1308.0850.
- QUOTE:
- QUOTE:
2005
- (Graves & Schmidhuber, 2005) ⇒ Alex Graves, and Jurgen Schmidhuber (2005). "Framewise phoneme classification with bidirectional LSTM and other neural network architectures". Neural Networks, 18(5-6), 602-610.
- QUOTE: An LSTM layer consists of a set of recurrently connected blocks, known as memory blocks. These blocks can be thought of as a differentiable version of the memory chips in a digital computer. Each one contains one or more recurrently connected memory cells and three multiplicative units — the input, output and forget gates — that provide continuous analogues of write, read and reset operations for the cells. More precisely, the input to the cells is multiplied by the activation of the input gate, the output to the net is multiplied by that of the output gate, and the previous cell values are multiplied by the forget gate. The net can only interact with the cells via the gates.
2002
- (Gers et al., 2002) ⇒ Felix A. Gers, Nicol N. Schraudolph, and Jurgen Schmidhuber (2002). "Learning precise timing with LSTM recurrent networks". Journal of machine learning research, 3(Aug), 115-143.
- QUOTE: The basic unit of an LSTM network is the memory block containing one or more memory cells and three adaptive, multiplicative gating units shared by all cells in the block (Figure 1). Each memory cell has at its core a recurrently self-connected linear unit we call the “Constant Error Carousel” (CEC). By recirculating activation and error signals indefinitely,the CEC provides short-term memory storage for extended time periods. The input, forget, and output gate can be trained to learn, respectively, what information to store in the memory, how long to store it, and when to read it out. Combining memory cells into blocks allows them to share the same gates (provided the task permits this), thus reducing the number of adaptive parameters.
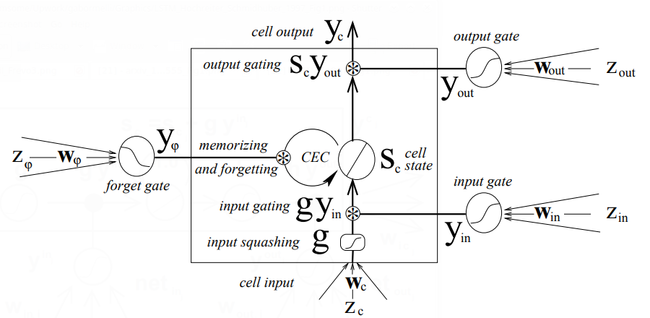
- QUOTE: The basic unit of an LSTM network is the memory block containing one or more memory cells and three adaptive, multiplicative gating units shared by all cells in the block (Figure 1). Each memory cell has at its core a recurrently self-connected linear unit we call the “Constant Error Carousel” (CEC). By recirculating activation and error signals indefinitely,the CEC provides short-term memory storage for extended time periods. The input, forget, and output gate can be trained to learn, respectively, what information to store in the memory, how long to store it, and when to read it out. Combining memory cells into blocks allows them to share the same gates (provided the task permits this), thus reducing the number of adaptive parameters.

- Figure 1: LSTM memory block with one cell (rectangle). The so-called CEC maintains the cell state [math]\displaystyle{ s_c }[/math],which may be reset by the forget gate. Input and output gate control read and write access to the CEC; [math]\displaystyle{ g }[/math] squashes the cell input.
1997
- (Hochreiter & Schmidhuber,1997) ⇒ Sepp Hochreiter and Jurgen Schmidhuber (1997). "Long short-term memory". Neural computation, 9(8), 1735-1780.
- QUOTE: To construct an architecture that allows for constant error flow through special, self-connected units without the disadvantages of the naive approach, we extend the constant error carrousel (CEC) embodied by the self-connected, linear unit j from Section 3.2 by introducing additional features. A multiplicative input gate unit is introduced to protect the memory contents stored in j from perturbation by irrelevant inputs. Likewise, a multiplicative output gate unit is introduced which protects other units from perturbation by currently irrelevant memory contents stored in j.
The resulting, more complex unit is called a memory cell (see Figure 1).
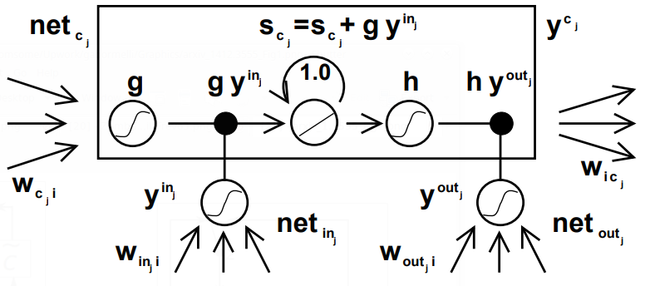
- QUOTE: To construct an architecture that allows for constant error flow through special, self-connected units without the disadvantages of the naive approach, we extend the constant error carrousel (CEC) embodied by the self-connected, linear unit j from Section 3.2 by introducing additional features. A multiplicative input gate unit is introduced to protect the memory contents stored in j from perturbation by irrelevant inputs. Likewise, a multiplicative output gate unit is introduced which protects other units from perturbation by currently irrelevant memory contents stored in j.

- Figure 1: Architecture of memory cell [math]\displaystyle{ c_j }[/math] (the box) and its gate units [math]\displaystyle{ in_j }[/math], [math]\displaystyle{ out_j }[/math]. The self-recurrent connection (with weight 1.0) indicates feedback with a delay of 1 time step. It builds the basis of the “constant error carrousel” CEC. The gate units open and close access to CEC. See text and appendix A.1 for details.