File:2019 MultiTaskDeepNeuralNetworksfor Fig1.png
2019_MultiTaskDeepNeuralNetworksfor_Fig1.png (683 × 492 pixels, file size: 74 KB, MIME type: image/png)
Summary
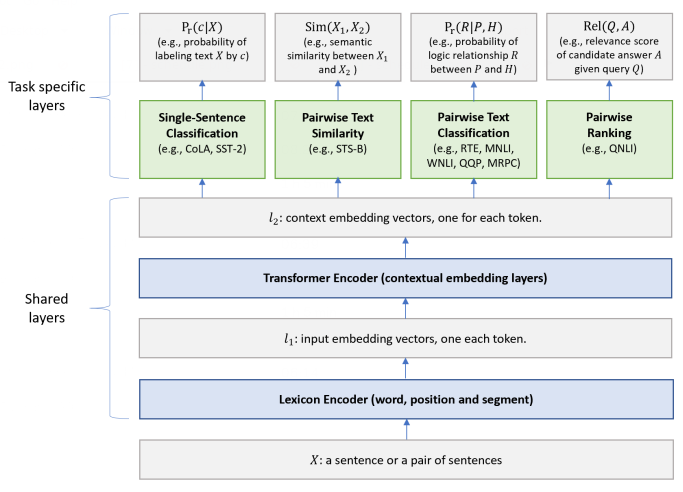
Figure 1: Architecture of the MT-DNN model for representation learning. The lower layers are shared across all tasks while the top layers are task-specific. The input [math]\displaystyle{ X }[/math] (either a sentence or a pair of sentences) is first represented as a sequence of embedding vectors, one for each word, in [math]\displaystyle{ \ell_1 }[/math]. Then the Transformer encoder captures the contextual information for each word and generates the shared contextual embedding vectors in [math]\displaystyle{ \ell_2 }[/math]. Finally, for each task, additional task-specific layers generate task-specific representations, followed by operations necessary for classification, similarity scoring, or relevance ranking. Copyright: Liu et al. (2019)
File history
Click on a date/time to view the file as it appeared at that time.
| Date/Time | Thumbnail | Dimensions | User | Comment | |
|---|---|---|---|---|---|
| current | 04:05, 28 April 2019 | | 683 × 492 (74 KB) | Omoreira (talk | contribs) | <B>Figure 1:</B> Architecture of the MT-DNN model for representation learning. The lower layers are shared across all tasks while the top layers are task-specific. The input <math>X</math> (either a sentence... |
You cannot overwrite this file.
File usage
The following 2 pages use this file:
{kind=link}