Multi-Task Deep Neural Network (MT-DNN)
A Multi-Task Deep Neural Network (MT-DNN) is a Deep Learning Neural Network that is composed of two or more Task Specific Neural Layers.
- Example(s):
- Counter-Example(s):
- See: Multi-Task Learning, Neural Natural Language Processing System, Natural Language Understanding Task.
References
2019
- (Liu et al., 2019) ⇒ Xiaodong Liu, Pengcheng He, Weizhu Chen, and Jianfeng Gao. (2019). “Multi-Task Deep Neural Networks for Natural Language Understanding.” arXiv:1901.11504
- QUOTE: The architecture of the MT-DNN model is shown in Figure 1. The lower layers are shared across all tasks, while the top layers represent task-specific outputs. The input [math]\displaystyle{ X }[/math], which is a word sequence (either a sentence or a pair of sentences packed together) is first represented as a sequence of embedding vectors, one for each word, in [math]\displaystyle{ \ell_1 }[/math]. Then the transformer encoder captures the contextual information for each word via self-attention, and generates a sequence of contextual embeddings in [math]\displaystyle{ \ell_2 }[/math]. This is the shared semantic representation that is trained by our multi-task objectives. In what follows, we elaborate on the model in detail.
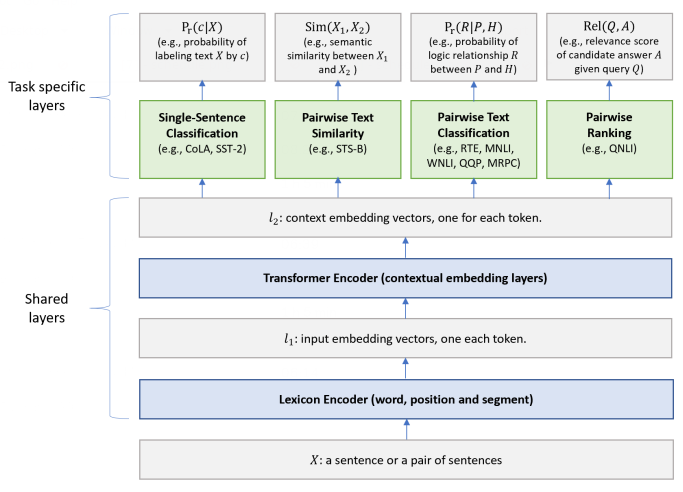
Figure 1: Architecture of the MT-DNN model for representation learning. The lower layers are shared across all tasks while the top layers are task-specific. The input [math]\displaystyle{ X }[/math] (either a sentence or a pair of sentences) is first represented as a sequence of embedding vectors, one for each word, in [math]\displaystyle{ \ell_1 }[/math]. Then the Transformer encoder captures the contextual information for each word and generates the shared contextual embedding vectors in [math]\displaystyle{ \ell_2 }[/math]. Finally, for each task, additional task-specific layers generate task-specific representations, followed by operations necessary for classification, similarity scoring, or relevance ranking.
- QUOTE: The architecture of the MT-DNN model is shown in Figure 1. The lower layers are shared across all tasks, while the top layers represent task-specific outputs. The input [math]\displaystyle{ X }[/math], which is a word sequence (either a sentence or a pair of sentences packed together) is first represented as a sequence of embedding vectors, one for each word, in [math]\displaystyle{ \ell_1 }[/math]. Then the transformer encoder captures the contextual information for each word via self-attention, and generates a sequence of contextual embeddings in [math]\displaystyle{ \ell_2 }[/math]. This is the shared semantic representation that is trained by our multi-task objectives. In what follows, we elaborate on the model in detail.
