Universal Language Model Fine-tuning for Text Classification (ULMFiT) System
A Universal Language Model Fine-tuning for Text Classification (ULMFiT) System is a Language Modeling System based on a Transfer Learning that can be used for Text Classification.
- Context:
- It is composed of a Pretrained Encoder and Classifier Model.
- It is based on an AWD-LSTM Neural Network architecture.
- It can range from being a Semi-Supervised ULMFiT System to being a Supervised ULMFiT System.
- It uses a Wikitext 103 Dataset.
- Example(s):
- ...
- …
- Counter-Example(s):
- See: Natural Language Processing System, LSTM Neural Network, Text Classification System, Natural Language Understanding System, Natural Language Inference System.
References
2019
- (Turgutlu, 2019) ⇒ Kerem Turgutlu (2019) "Understanding building blocks of ULMFIT" ML Review.
- QUOTE: High level idea of ULMFIT is to train a language model using a very large corpus like Wikitext-103 (103M tokens), then to take this pretrained model's encoder and combine it with a custom head model, e.g. for classification, and to do the good old fine tuning using discriminative learning rates in multiple stages carefully (...) Above is the layer by layer exposure of ULMFIT in fast.ai library. Model is composed of pretrained encoder (MultiBatchRNNCore — module 0) and a custom head, e.g. for binary classification task in this case (PoolingLinearClassifier — module 1).
Architecture that ULMFIT uses for it’s language modeling task is an AWD-LSTM. The name is an abbreviation of ASGD Weight-Dropped LSTM.
- QUOTE: High level idea of ULMFIT is to train a language model using a very large corpus like Wikitext-103 (103M tokens), then to take this pretrained model's encoder and combine it with a custom head model, e.g. for classification, and to do the good old fine tuning using discriminative learning rates in multiple stages carefully (...) Above is the layer by layer exposure of ULMFIT in fast.ai library. Model is composed of pretrained encoder (MultiBatchRNNCore — module 0) and a custom head, e.g. for binary classification task in this case (PoolingLinearClassifier — module 1).
2018a
- (Howard & Ruder, 2018) ⇒ Jeremy Howard, and Sebastian Ruder. (2018). “Universal Language Model Fine-tuning for Text Classification.” In: Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (ACL-2018).
- QUOTE: We propose Universal Language Model Fine-tuning (ULMFiT), which pretrains a language model (LM) on a large general-domain corpus and fine-tunes it on the target task using novel techniques. The method is universal in the sense that it meets these practical criteria: 1) It works across tasks varying in document size, number, and label type; 2) it uses a single architecture and training process; 3) it requires no custom feature engineering or preprocessing; and 4) it does not require additional in-domain documents or labels.
In our experiments, we use the state-of-the-art language model AWD-LSTM (Merity et al., 2017a), a regular LSTM (with no attention, short-cut connections, or other sophisticated additions) with various tuned dropout hyperparameters. Analogous to CV, we expect that downstream performance can be improved by using higher performance language models in the future.
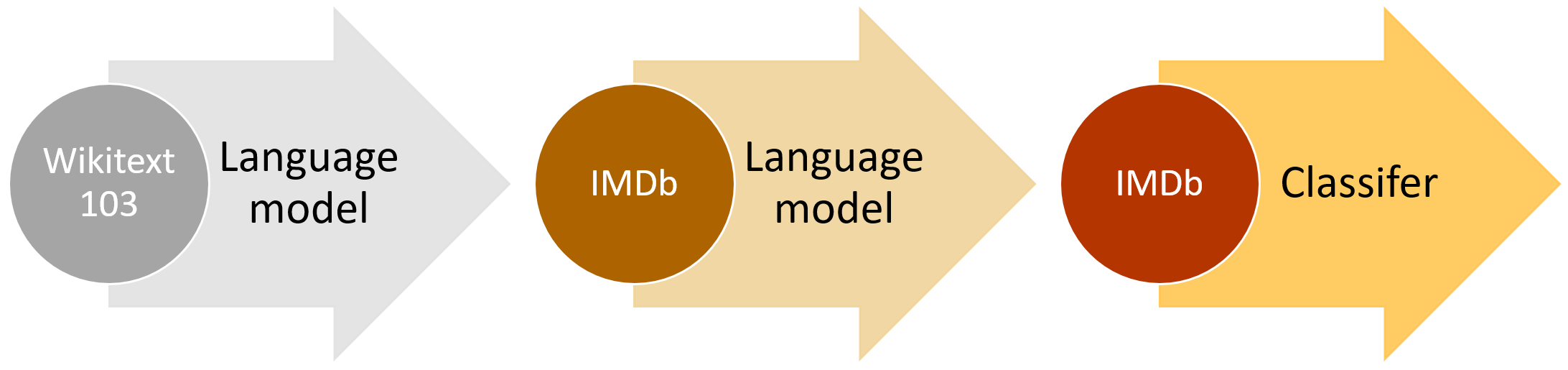
ULMFiT consists of the following steps, which we show in Figure 1: a) General-domain LM pretraining (3.1); b) target task LM fine-tuning (3.2); and c) target task classifier fine-tuning (3.3). We discuss these in the following sections.
- QUOTE: We propose Universal Language Model Fine-tuning (ULMFiT), which pretrains a language model (LM) on a large general-domain corpus and fine-tunes it on the target task using novel techniques. The method is universal in the sense that it meets these practical criteria: 1) It works across tasks varying in document size, number, and label type; 2) it uses a single architecture and training process; 3) it requires no custom feature engineering or preprocessing; and 4) it does not require additional in-domain documents or labels.

2018b
- (Howard & Ruder, 2018) ⇒ Jeremy Howard and Sebastian Ruder (15 May, 2018). "Introducing state of the art text classification with universal language models". fast.ai NLP.
- QUOTE: We found that in practice this approach to transfer learning has the features that allow it to be a universal approach to NLP transfer learning:
- It works across tasks varying in document size, number, and label type
- It uses a single architecture and training process.
- It requires no custom feature engineering or preprocessing.
- It does not require additional in-domain documents or labels.
- QUOTE: We found that in practice this approach to transfer learning has the features that allow it to be a universal approach to NLP transfer learning:
- (...) This idea has been tried before, but required millions of documents for adequate performance. We found that we could do a lot better by being smarter about how we fine-tune our language model. In particular, we found that if we carefully control how fast our model learns and update the pre-trained model so that it does not forget what it has previously learned, the model can adapt a lot better to a new dataset. One thing that we were particularly excited to find is that the model can learn well even from a limited number of examples. On one text classification dataset with two classes, we found that training our approach with only 100 labeled examples (and giving it access to about 50,000 unlabeled examples), we were able to achieve the same performance as training a model from scratch with 10,000 labeled examples.
Another important insight was that we could use any reasonably general and large language corpus to create a universal language model—something that we could fine-tune for any NLP target corpus. We decided to use Stephen Merity’s Wikitext 103 dataset, which contains a pre-processed large subset of English Wikipedia.
- (...) This idea has been tried before, but required millions of documents for adequate performance. We found that we could do a lot better by being smarter about how we fine-tune our language model. In particular, we found that if we carefully control how fast our model learns and update the pre-trained model so that it does not forget what it has previously learned, the model can adapt a lot better to a new dataset. One thing that we were particularly excited to find is that the model can learn well even from a limited number of examples. On one text classification dataset with two classes, we found that training our approach with only 100 labeled examples (and giving it access to about 50,000 unlabeled examples), we were able to achieve the same performance as training a model from scratch with 10,000 labeled examples.