Coreference Clustering Task
A Coreference Clustering Task is a clustering task where all referencers must be grouped into coreference clusters (that share a coreference relation).
- AKA: Coreference Resolution, Duplicate Referencer Detection.
- Context:
- Input: A Referencer Set (with some reference information).
- optional: Background Knowledge, such as a canonical entity database.
- output: A set of Coreference Clusters.
- It can range from (typically) being an Entity Reference Clustering Task to being a Relation Reference Clustering Task.
- It can be solved by a Coreference Resolution System (that implements a Coreference Resolution algorithm).
- It can range from being a Heuristic Coreference Resolution Task to being a Data-Driven Coreference Resolution Task.
- It can range from being a General Coreference Resolution Task to being a Domain-Specific Coreference Resolution Task.
- It can support a Reference Grounding Task.
- …
- Input: A Referencer Set (with some reference information).
- Example(s):
- Counter-Example(s):
- See: Coreference Chain, Coreferential Expression Set, Ontology, Word Mention Clustering Task, Coreference Relation, Markable, Natural Language Processing Task, Tokenization, Sentence Segmentation, Part-Of-Speech Tagging, Named Entity Recognition.
References
2019
- (Wikipedia, 2019) ⇒ https://en.wikipedia.org/wiki/Coreference#Coreference_resolution Retrieved:2019-3-15.
- In computational linguistics, coreference resolution is a well-studied problem in discourse. To derive the correct interpretation of a text, or even to estimate the relative importance of various mentioned subjects, pronouns and other referring expressions must be connected to the right individuals. Algorithms intended to resolve coreferences commonly look first for the nearest preceding individual that is compatible with the referring expression. For example, she might attach to a preceding expression such as the woman or Anne, but not to Bill. Pronouns such as himself have much stricter constraints. Algorithms for resolving coreference tend to have accuracy in the 75% range. As with many linguistic tasks, there is a tradeoff between precision and recall.
A classic problem for coreference resolution in English is the pronoun it, which has many uses. It can refer much like he and she, except that it generally refers to inanimate objects (the rules are actually more complex: animals may be any of it, he, or she; ships are traditionally she; hurricanes are usually it despite having gendered names). It can also refer to abstractions rather than beings: "He was paid minimum wage, but didn't seem to mind it." Finally, it also has pleonastic uses, which do not refer to anything specific:
- In computational linguistics, coreference resolution is a well-studied problem in discourse. To derive the correct interpretation of a text, or even to estimate the relative importance of various mentioned subjects, pronouns and other referring expressions must be connected to the right individuals. Algorithms intended to resolve coreferences commonly look first for the nearest preceding individual that is compatible with the referring expression. For example, she might attach to a preceding expression such as the woman or Anne, but not to Bill. Pronouns such as himself have much stricter constraints. Algorithms for resolving coreference tend to have accuracy in the 75% range. As with many linguistic tasks, there is a tradeoff between precision and recall.
- a. It's raining.
- b. It's really a shame.
- c. It takes a lot of work to succeed.
- d. Sometimes it's the loudest who have the most influence.
- Pleonastic uses are not considered referential, and so are not part of coreference. [1]
2015
- (Sawhney & Wang, 2015) ⇒ Kartik Sawhney, and Rebecca Wang. (2015). “Coreference Resolution.” f
- Overview - Coreference resolution refers to the task of clustering different mentions referring to the same entity. This is particularly useful in other NLP tasks, including retrieving information about specific named entities, machine translation, among others. In this report, we discuss our approach, implementation and observations for a few baseline systems, a rule-based system, and a classifier-based system. To quantify the effectiveness of our implementation, we use the MUC and B^3 measures (precision, recall and F1) for coreference evaluation. The difference in the two scoring metrics in how they define a coreference set within a text (in terms of links or in terms of classes or clusters) results in interesting observations as we discuss in the report.
2012
- (Stoyanov & Eisner, 2012) ⇒ Veselin Stoyanov, and Jason Eisner. (2012). “Easy-first Coreference Resolution.” In: Proceedings of COLING 2012.
2014
- http://cogcomp.cs.illinois.edu/page/demos/
- QUOTE: A given entity - representing a person, a location, or an organization - may be mentioned in text in multiple, ambiguous ways. Understanding natural language and supporting intelligent access to textual information requires identifying whether different entity mentions are actually referencing the same entity. The Coreference Resolution Demo processes unannotated text, detecting mentions of entities and showing which mentions are coreferential.
2009
- (Wick et al., 2009) ⇒ Michael Wick, Aron Culotta, Khashayar Rohanimanesh, and Andrew McCallum. (2009). “An Entity Based Model for Coreference Resolution.” In: Proceedings of the SIAM International Conference on Data Mining (SDM 2009).
- QUOTE: Coreference resolution is the problem of clustering mentions (or records) into sets referring to the same underlying entity (e.g., person, places, organizations). Over the past several years, increasingly powerful supervised machine learning techniques have been developed to solve this problem. Initial solutions treated it as a set of independent binary classifications, one for each pair of mentions [1, 2]. Next, relational probability models were developed to capture the dependency between each of these classifications [3, 4]; however the parameterization of these methods still consists of features over pairs of mentions. Finally, methods have been developed to enable arbitrary features over entire clusters of mentions [5, 6, 7].
2006
- (Pasula, 2006) ⇒ Hanna Pasula. (2006). “Approximate Inference Techniques for Identity Uncertainty." Lecture
- QUOTE: Many interesting tasks, such as vehicle tracking, data association, and mapping, involve reasoning about the objects present in a domain. However, the observations on which this reasoning is to be based frequently fail to explicitly describe these objects' identities, properties, or even their number, and may in addition be noisy or nondeterministic. When this is the case, identifying the set of objects present becomes an important aspect of the whole task.
2001
- (Soon et al., 2001) ⇒ Wee Meng Soon, Hwee Tou Ng, and Daniel Chung Yong Lim. (2001). “A Machine Learning Approach to Coreference Resolution of Noun Phrases.” In: Computational Linguistics, Vol. 27, No. 4.
- QUOTE: A prerequisite for coreference resolution is to obtain most, if not all, of the possible markables in a raw input text. To determine the markables, a pipeline of natural language processing (NLP) modules is used, as shown in Figure 1. They consist of tokenization, sentence segmentation, morphological processing, part-of-speech tagging, noun phrase identification, named entity recognition, nested noun phrase extraction, and semantic class determination. As far as coreference resolution is concerned, the goal of these NLP modules is to determine the boundary of the markables, and to provide the necessary information about each markable for subsequent generation of features in the training examples.
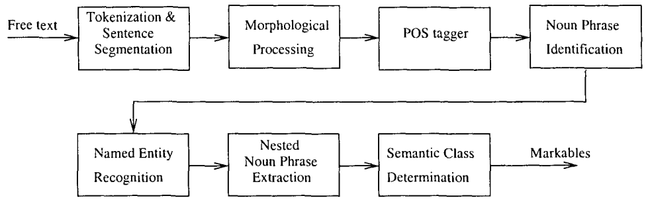
Figure 1 System architecture of natural language processing pipeline.
- QUOTE: A prerequisite for coreference resolution is to obtain most, if not all, of the possible markables in a raw input text. To determine the markables, a pipeline of natural language processing (NLP) modules is used, as shown in Figure 1. They consist of tokenization, sentence segmentation, morphological processing, part-of-speech tagging, noun phrase identification, named entity recognition, nested noun phrase extraction, and semantic class determination. As far as coreference resolution is concerned, the goal of these NLP modules is to determine the boundary of the markables, and to provide the necessary information about each markable for subsequent generation of features in the training examples.
