Encoder-Decoder Sequence-to-Sequence Learning Task
An Encoder-Decoder Sequence-to-Sequence Learning Task is a Sequence-to-Sequence Learning Task that is based on a Encoder-Decoder Neural Network.
- Context:
- Example(s):
- a Neural Machine Translation System that is based on a RNN Encoder-Decoder Network,
- a Sequence-to-Sequence Learning System that is based on a CNN Encoder-Decoder Network.
- …
- Counter-Example(s):
- a Convolutional Sequence-to-Sequence Training Task,
- a Connectionist Sequence Classification Task;
- a Multi-modal Sequence to Sequence Training;
- a Neural seq2seq Model Training;
- a Sequence-to-Sequence Learning with Variational Auto-Encoder;
- a Sequence-to-Sequence Learning via Shared Latent Representation;
- a Sequence-to-Sequence Translation with Attention Mechanism.
- See: Natural Language Processing Task, Sequence Learning Task, Word Sense Disambiguation, LSTM, Deep Neural Network, Memory Augmented Neural Network Training System, Deep Sequence Learning Task, Bidirectional LSTM.
References
2018
- (Liao et al., 2018) ⇒ Binbing Liao, Jingqing Zhang, Chao Wu, Douglas McIlwraith, Tong Chen, Shengwen Yang, Yike Guo, and Fei Wu. (2018). “Deep Sequence Learning with Auxiliary Information for Traffic Prediction.” In: Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. ISBN:978-1-4503-5552-0 doi:10.1145/3219819.3219895
- QUOTE: In this paper, we effectively utilise three kinds of auxiliary information in an encoder-decoder sequence to sequence (Seq2Seq) [7, 32] learning manner as follows: a wide linear model is used to encode the interactions among geographical and social attributes, a graph convolution neural network is used to learn the spatial correlation of road segments, and the query impact is quantified and encoded to learn the potential influence of online crowd queries(...)
Figure 4 shows the architecture of the Seq2Seq model for traffic prediction. The encoder embeds the input traffic speed sequence [math]\displaystyle{ \{v_1,v_2, \cdots ,v_t \} }[/math] and the final hidden state of the encoder is fed into the decoder, which learns to predict the future traffic speed [math]\displaystyle{ \{\tilde{v}_{t+1},\tilde{v}_{t+2}, \cdots,\tilde{v}_{t+t'} \} }[/math]. Hybrid model that integrates the auxiliary information will be proposed based on the Seq2Seq model.
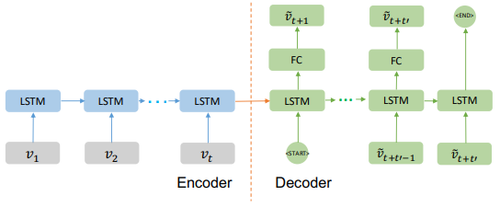
Figure 4: Seq2Seq: The Sequence to Sequence model predicts future traffic speed [math]\displaystyle{ \{\tilde{v}_{t+1},\tilde{v}_{t+2}, \cdots ,\tilde{v}_{t+t'} \} }[/math], given the previous traffic speed [math]\displaystyle{ {v_1,v_2, ...v_t } }[/math].
- QUOTE: In this paper, we effectively utilise three kinds of auxiliary information in an encoder-decoder sequence to sequence (Seq2Seq) [7, 32] learning manner as follows: a wide linear model is used to encode the interactions among geographical and social attributes, a graph convolution neural network is used to learn the spatial correlation of road segments, and the query impact is quantified and encoded to learn the potential influence of online crowd queries(...)

2017
- (Ramachandran et al., 2017) ⇒ Prajit Ramachandran, Peter J. Liu, and Quoc V. Le. (2017). “Unsupervised Pretraining for Sequence to Sequence Learning.” In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing (EMNLP 2017). arViv:1611.02683
- QUOTE: Therefore, the basic procedure of our approach is to pretrain both the seq2seq encoder and decoder networks with language models, which can be trained on large amounts of unlabeled text data. This can be seen in Figure 1, where the parameters in the shaded boxes are pretrained. In the following we will describe the method in detail using machine translation as an example application.
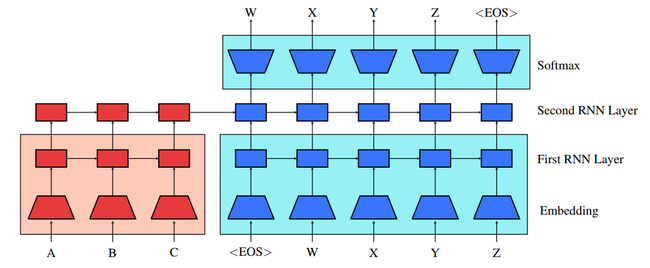
Figure 1: Pretrained sequence to sequence model. The red parameters are the encoder and the blue parameters are the decoder. All parameters in a shaded box are pretrained, either from the source side (light red) or target side (light blue) language model. Otherwise, they are randomly initialized.
- QUOTE: Therefore, the basic procedure of our approach is to pretrain both the seq2seq encoder and decoder networks with language models, which can be trained on large amounts of unlabeled text data. This can be seen in Figure 1, where the parameters in the shaded boxes are pretrained. In the following we will describe the method in detail using machine translation as an example application.

2016
- (Luong et al., 2016) ⇒ Minh-Thang Luong, Quoc V. Le, Ilya Sutskever, Oriol Vinyals, and Lukasz Kaiser. (2016). “Multi-task Sequence to Sequence Learning.” In: Proceedings of 4th International Conference on Learning Representations (ICLR-2016).
2014a
- (Sutskever et al., 2014) ⇒ Ilya Sutskever, Oriol Vinyals, and Quoc V. Le. (2014). “Sequence to Sequence Learning with Neural Networks.” In: Advances in Neural Information Processing Systems. arXiv:1409.321
2014b
- (Cho et al., 2014a) ⇒ Kyunghyun Cho, Bart van Merrienboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. (2014). “Learning Phrase Representations Using RNN Encoder-Decoder for Statistical Machine Translation”. In: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, (EMNLP-2014). arXiv:1406.1078
- QUOTE: In this paper, we propose a novel neural network architecture that learns to encode a variable-length sequence into a fixed-length vector representation and to decode a given fixed-length vector representation back into a variable-length sequence.