Deep Neural Network (DNN) Model
A Deep Neural Network (DNN) Model is an multi hidden-layer neural network with a neural network layer depth larger than three and that can learn hierarchical representations (enabling complex pattern recognition tasks).
- Context:
- It can be trained by Deep Neural Network Training System that implements Deep Neural Network Training Algorithm to solve a Deep Neural Network Training Task.
- It can enable Hierarchical Feature Learning through multiple processing layers.
- It can perform Complex Pattern Recognition through learned representations.
- It can serve as a Generative Approach, producing novel examples by learning a distribution over data (e.g., images, audio, or text).
- ...
- It can range from being a Unidirectional Deep Neural Network to being a Bidirectional Deep Neural Network, depending on its information flow.
- It can range from being an Untrained DNN to being a Trained DNN (such as a fine-tuned DNN model).
- It can range from being a Simple Feed-Forward Architecture to being a Complex Hybrid Architecture, depending on its network topology.
- ...
- It can utilize various DNN Architectures that define the structure and arrangement of layers and neurons.
- It can apply DNN Activation Functions, which are non-linear functions to neuron outputs.
- It can involve DNN Weight Parameters, which are learnable parameters adjusted during training.
- It can require setting DNN Hyperparameters, which are configuration settings that control the learning process.
- ...
- It can face Technical Challenges such as:
- ...
- Examples:
- Computer Vision DNN Models, such as:
- DNN-based Sequence Processing Models, such as:
- Recurrent Neural Network (RNN) with recurrent connections.
- Deep Bidirectional LSTM Convolutional Neural Network (DBLSTM-CNN) combining bidirectional LSTM and convolutional layers.
- Stacked Bidirectional and Unidirectional LSTM (SBU-LSTM) Neural Network with layers of both bidirectional and unidirectional LSTMs.
- DNN Language Models, such as:
- Transformer-based DNN Model using self-attention mechanisms for processing sequential data.
- Bidirectional Encoder Representations from Transformers (BERT) model with bidirectional training for language understanding.
- Generative Pre-trained Transformer (GPT) model pre-trained on large text corpora for generative tasks.
- Hybrid DNN Architectures, such as:
- Deep Neural Network with Deep Belief Network Layers (DBN-DNN) incorporating unsupervised pre-training layers.
- Deep Neural Network with Context-Dependent Hidden Markov Model layers (CD-DNN-HMM) integrating DNN and HMM for context modeling.
- Deep Similarity Neural Network focusing on learning similarity measures between data points.
- Classical Architectures, such as:
- Supervised Deep Feedforward Multilayer Perceptron with multiple fully connected layers.
- DNN-based Generative Models, such as:
- Variational Autoencoder (VAE) that encodes data into a latent space and then reconstructs it.
- Generative Adversarial Network (GAN) that pits two neural networks (generator and discriminator) against each other.
- Diffusion Model that progressively denoises random inputs to produce high-fidelity data.
- ...
- DNN Speech Recognition Model for audio processing.
- DNN Autonomous Driving Model for vehicle control.
- DNN Drug Discovery Model for molecular design.
- ...
- Counter-Examples:
- Shallow Neural Networks, which has fewer than three layers and lacks the capacity for learning complex hierarchical representations.
- Traditional Machine Learning Models, which do not involve deep architectures or hierarchical representation learning.
- Deep Belief Network (DBN), which is a generative model rather than a discriminative model.
- Self-Organizing Map, which uses unsupervised learning without deep hierarchical structure.
- See: Deep Learning, Acoustic Model, Artificial Neural Network, Linear Relationship, Primitive Data Type, Recurrent Neural Networks, Language Model, Convolutional Neural Network, Overfitting, Regularization (Mathematics), Weight Decay, Sparse Matrix, Hyperparameter Optimization#Grid Search.
References
2018
- (Wikipedia, 2018) ⇒ https://en.wikipedia.org/wiki/Deep_learning#Deep_neural_networks Retrieved:2018-8-12.
- A deep neural network (DNN) is an artificial neural network (ANN) with multiple layers between the input and output layers (Bengio, 2009; Schmidhuber, 2015). The DNN finds the correct mathematical manipulation to turn the input into the output, whether it be a linear relationship or a non-linear relationship. The network moves through the layers calculating the probability of each output. For example, a DNN that is trained to recognize dog breeds will go over the given image and calculate the probability that the dog in the image is a certain breed. The user can review the results and select which probabilities the network should display (above a certain threshold, etc.) and return the proposed label. Each mathematical manipulation as such is considered a layer, and complex DNN have many layers, hence the name "deep" networks.
DNNs can model complex non-linear relationships. DNN architectures generate compositional models where the object is expressed as a layered composition of primitives (Szegedy, Toshev & Erhan, 2013). The extra layers enable composition of features from lower layers, potentially modeling complex data with fewer units than a similarly performing shallow network (Bengio, 2009). Deep architectures include many variants of a few basic approaches. Each architecture has found success in specific domains. It is not always possible to compare the performance of multiple architectures, unless they have been evaluated on the same data sets. DNNs are typically feedforward networks in which data flows from the input layer to the output layer without looping back. At first, the DNN creates a map of virtual neurons and assigns random numerical values, or "weights", to connections between them. The weights and inputs are multiplied and return an output between 0 and 1. If the network didn’t accurately recognize a particular pattern, an algorithm would adjust the weights. That way the algorithm can make certain parameters more influential, until it determines the correct mathematical manipulation to fully process the data.
Recurrent neural networks (RNNs), in which data can flow in any direction, are used for applications such as language modeling (Gers & Schmidhuber, 2001; Sutskever, Vinyals & Le, 2014; Jozefowicz et al., 2016; Gillick et al., 2016; and Mikolov et al., 2010). Long short-term memory is particularly effective for this use (Hochreiter & Schmidhuber, 1997; and Gers, Schraudolph & Schmidhuber, 2002).
Convolutional deep neural networks (CNNs) are used in computer vision (LeCun et al., 1998). CNNs also have been applied to acoustic modeling for automatic speech recognition (ASR; Sainath et al., 2013).
- A deep neural network (DNN) is an artificial neural network (ANN) with multiple layers between the input and output layers (Bengio, 2009; Schmidhuber, 2015). The DNN finds the correct mathematical manipulation to turn the input into the output, whether it be a linear relationship or a non-linear relationship. The network moves through the layers calculating the probability of each output. For example, a DNN that is trained to recognize dog breeds will go over the given image and calculate the probability that the dog in the image is a certain breed. The user can review the results and select which probabilities the network should display (above a certain threshold, etc.) and return the proposed label. Each mathematical manipulation as such is considered a layer, and complex DNN have many layers, hence the name "deep" networks.
2017
- (Schmidhuber, 2017) ⇒ Jurgen Schmidhuber (2017) "Deep Learning". In: Sammut & Webb, 2017. DOI 10.1007/978-1-4899-7687-1
- QUOTE: Deep learning networks originated in the 1960s when Ivakhnenko and Lapa (1965) published the first general, working learning algorithm for supervised deep feedforward multilayer perceptrons. Their units had polynomial activation functions combining additions and multiplications in Kolmogorov Gabor polynomials. Ivakhnenko (1971) already described a deep network with eight layers trained by the “group method of data handling,” still popular in the new millennium. Given a training set of input vectors with corresponding target output vectors, layers are incrementally grown and trained by regression analysis and then pruned with the help of a separate validation set, where regularization is used to weed out superfluous units. The numbers of layers and units per layer can be learned in problem-dependent fashion.
Like later deep NNs, Ivakhnenko’s nets learned to create hierarchical, distributed, internal representations of incoming data. Many later nonneural methods of Artificial Intelligence and Machine Learning also learn more and more abstract, hierarchical data representations. For example, syntactic pattern recognition methods (Fu 1977) such as grammar induction discover hierarchies of formal rules to model observations.
- QUOTE: Deep learning networks originated in the 1960s when Ivakhnenko and Lapa (1965) published the first general, working learning algorithm for supervised deep feedforward multilayer perceptrons. Their units had polynomial activation functions combining additions and multiplications in Kolmogorov Gabor polynomials. Ivakhnenko (1971) already described a deep network with eight layers trained by the “group method of data handling,” still popular in the new millennium. Given a training set of input vectors with corresponding target output vectors, layers are incrementally grown and trained by regression analysis and then pruned with the help of a separate validation set, where regularization is used to weed out superfluous units. The numbers of layers and units per layer can be learned in problem-dependent fashion.
2016a
- (Jozefowicz et al., 2016) ⇒ Rafal Jozefowicz, Oriol Vinyals, Mike Schuster, Noam Shazeer, and Yonghui Wu (2016). "Exploring the limits of language modeling". arXiv preprint arXiv:1602.02410.
- QUOTE: Deep Learning and Recurrent Neural Networks (RNNs) have fueled language modeling research in the past years as it allowed researchers to explore many tasks for which the strong conditional independence assumptions are unrealistic. Despite the fact that simpler models, such as Ngrams, only use a short history of previous words to predict the next word, they are still a key component to high quality, low perplexity LMs.
(...) The architectures that we considered in this paper are represented in Figure 1.
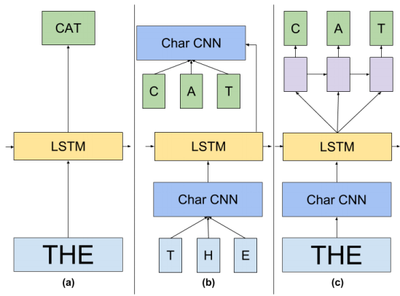
Figure 1. A high-level diagram of the models presented in this paper. (a) is a standard LSTM LM. (b) represents an LM where both input and Softmax embeddings have been replaced by a character CNN. In (c) we replace the Softmax by a next character prediction LSTM network.
- QUOTE: Deep Learning and Recurrent Neural Networks (RNNs) have fueled language modeling research in the past years as it allowed researchers to explore many tasks for which the strong conditional independence assumptions are unrealistic. Despite the fact that simpler models, such as Ngrams, only use a short history of previous words to predict the next word, they are still a key component to high quality, low perplexity LMs.

2016b
- (Gillick et al., 2016) ⇒ Dan Gillick, Cliff Brunk, Oriol Vinyals, Amarnag Subramanya (2015). "Multilingual language processing from bytes". arXiv preprint arXiv:1512.00103.
2015
- (Schmidhuber, 2015) ⇒ Jurgen Schmidhuber (2015). "Deep learning in neural networks: An overview". Neural networks, 61, 85-117.
- QUOTE: A standard neural network (NN) consists of many simple, connected processors called neurons, each producing a sequence of real-valued activations. Input neurons get activated through sensors perceiving the environment, other neurons get activated through weighted connections from previously active neurons (details in Sec. 2). Some neurons may influence the environment by triggering actions. Learning or credit assignment is about finding weights that make the NN exhibit desired behavior, such as driving a car. Depending on the problem and how the neurons are connected, such behavior may require long causal chains of computational stages (Sec. 3), where each stage transforms (often in a non-linear way) the aggregate activation of the network. Deep Learning is about accurately assigning credit across many such stages.
2014
- (Sutskever et al., 2014) ⇒ Ilya Sutskever, Oriol Vinyals, and Quoc V. Le(2014). "Sequence to sequence learning with neural networks". In Advances in Neural Information Processing Systems (pp. 3104-3112).
- QUOTE: Deep Neural Networks (DNNs) are extremely powerful machine learning models that achieve excellent performance on difficult problems such as speech recognition (Hinton et al.,2012; Dahl et al., 2012) and visual object recognition (Krizhevsky, Sutskever & Hinton, 2012; Ciresan, Meier & Schmidhuber, 2012; LeCun et al., 1998; Lee,2013). DNNs are powerful because they can perform arbitrary parallel computation for a modest number of steps. A surprising example of the power of DNNs is their ability to sort N N-bit numbers using only 2 hidden layers of quadratic size (Razborov, 1992). So, while neural networks are related to conventional statistical models, they learn an intricate computation. Furthermore, large DNNs can be trained with supervised backpropagation whenever the labeled training set has enough information to specify the network’s parameters. Thus, if there exists a parameter setting of a large DNN that achieves good results (for example, because humans can solve the task very rapidly), supervised backpropagation will find these parameters and solve the problem.
2013a
- (Szegedy, Toshev & Erhan, 2013) ⇒ Christian Szegedy, Alexander Toshev, and Dumitru Erhan (2013). "Deep neural networks for object detection". In Advances in Neural Information Processing Systems (pp. 2553-2561).
- QUOTE: The core of our approach is a DNN-based regression towards an object mask, as shown in Fig. 1. Based on this regression model, we can generate masks for the full object as well as portions of the object. A single DNN regression can give us masks of multiple objects in an image. To further increase the precision of the localization, we apply the DNN localizer on a small set of large subwindows. The full flow is presented in Fig. 2 and explained below.
Figure 2: After regressing to object masks across several scales and large image boxes, we perform object box extraction. The obtained boxes are refined by repeating the same procedure on the sub images, cropped via the current object boxes. For brevity, we display only the full object mask, however, we use all five object masks.
- QUOTE: The core of our approach is a DNN-based regression towards an object mask, as shown in Fig. 1. Based on this regression model, we can generate masks for the full object as well as portions of the object. A single DNN regression can give us masks of multiple objects in an image. To further increase the precision of the localization, we apply the DNN localizer on a small set of large subwindows. The full flow is presented in Fig. 2 and explained below.


2013b
- (Sainath et al., 2013) ⇒ Tara N. Sainath, Abdel-rahman Mohamed, Brian Kingsbury, and Bhuvana Ramabhadran (2013, May). "Deep convolutional neural networks for LVCSR". In Acoustics, speech and signal processing (ICASSP), 2013 IEEE International Conference on (pp. 8614-8618). IEEE.
2013c
- (Le, 2013) ⇒ Quoc V. Le (2013, May). "Building high-level features using large scale unsupervised learning". In Acoustics, Speech and Signal Processing (ICASSP), 2013 IEEE International Conference on (pp. 8595-8598). IEEE.
2012a
- (Hinton et al.,2012) ⇒ Geoffrey Hinton, Li Deng, Dong Yu, George E. Dahl, Abdel-rahman Mohamed, Navdeep Jaitly, Andrew Senior et al. (2012). "Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups". IEEE Signal processing magazine, 29(6), 82-97.
- QUOTE: So after learning a DBN by training a stack of RBMs, we can jettison the whole probabilistic framework and simply use the generative weights in the reverse direction as a way of initializing all the feature detecting layers of a deterministic feedforward DNN. We then just add a final softmax layer and train the whole DNN discriminatively. Unfortunately, a DNN that is pretrained generatively as a DBN is often still called a DBN in the literature. For clarity, we call it a DBN-DNN ...
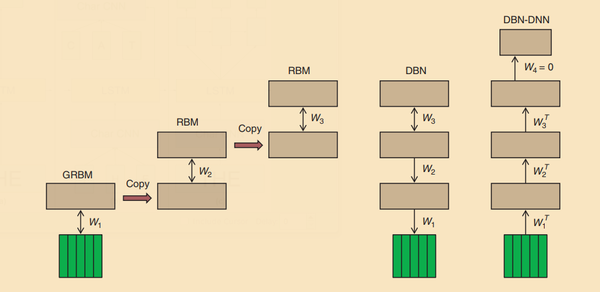
[FIG1] The sequence of operations used to create a DBN with three hidden layers and to convert it to a pretrained DBN-DNN. First, a GRBM is trained to model a window of frames of real-valued acoustic coefficients. Then the states of the binary hidden units of the GRBM are used as data for training an RBM. This is repeated to create as many hidden layers as desired. Then the stack of RBMs is converted to a single generative model, a DBN, by replacing the undirected connections of the lower level RBMs by top-down, directed connections. Finally, a pretrained DBN-DNN is created by adding a “softmax” output layer that contains one unit for each possible state of each HMM. The DBN-DNN is then discriminatively trained to predict the HMM state corresponding to the central frame of the input window in a forced alignment.
- QUOTE: So after learning a DBN by training a stack of RBMs, we can jettison the whole probabilistic framework and simply use the generative weights in the reverse direction as a way of initializing all the feature detecting layers of a deterministic feedforward DNN. We then just add a final softmax layer and train the whole DNN discriminatively. Unfortunately, a DNN that is pretrained generatively as a DBN is often still called a DBN in the literature. For clarity, we call it a DBN-DNN ...

2012b
- (Dahl et al., 2012) ⇒ George E. Dahl, Dong Yu, Li Deng, and Alex Acero (2012). "Context-dependent pre-trained deep neural networks for large-vocabulary speech recognition." IEEE Transactions on audio, speech, and language processing 20.1 (2012): 30-42.
- QUOTE: In this paper, we propose a novel acoustic model, a hybrid between a pre-trained, deep neural network (DNN) and a context-dependent (CD) hidden Markov model. The pre-training algorithm we use is the deep belief network (DBN) pre-training algorithm of Hinton, Osindero & Teh (2006), but we will denote our model with the abbreviation DNN-HMM to help distinguish it from a dynamic Bayes net (which we will not abreviate in this article) and to make it clear that we abandon the deep belief network once pre-training is complete and only retain and continue training the recognition weights. CD-DNN-HMMs combine the representational power of deep neural networks and the sequential modeling ability of context-dependent hidden Markov models (HMMs) ...
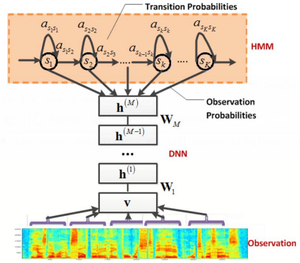
Fig. 1. Diagram of our hybrid architecture employing a deep neural network. The HMM models the sequential property of the speech signal, and the DNN models the scaled observation likelihood of all the senones (tied tri-phone states). The same DNN is replicated over different points in time.
- QUOTE: In this paper, we propose a novel acoustic model, a hybrid between a pre-trained, deep neural network (DNN) and a context-dependent (CD) hidden Markov model. The pre-training algorithm we use is the deep belief network (DBN) pre-training algorithm of Hinton, Osindero & Teh (2006), but we will denote our model with the abbreviation DNN-HMM to help distinguish it from a dynamic Bayes net (which we will not abreviate in this article) and to make it clear that we abandon the deep belief network once pre-training is complete and only retain and continue training the recognition weights. CD-DNN-HMMs combine the representational power of deep neural networks and the sequential modeling ability of context-dependent hidden Markov models (HMMs) ...

2012c
- (Krizhevsky, Sutskever & Hinton, 2012) ⇒ ALex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton (2012). "ImageNet classification with deep convolutional neural networks". In Advances in Neural Information Processing Systems (pp. 1097-1105).
2012d
- (Ciresan, Meier & Schmidhuber, 2012) ⇒ Dan Ciresan, Ueli Meier, and Jurgen Schmidhuber (2012). "Multi-column deep neural networks for image classification". arXiv preprint arXiv:1202.2745.
2010
- (Mikolov et al., 2010) ⇒ Tomáš Mikolov, Martin Karafiat, Lukas Burget, Jan Cernocy, and Sanjeev Khudanpur. (2010). "Recurrent neural network based language model". In Eleventh Annual Conference of the International Speech Communication Association.
2009
- (Bengio, 2009) ⇒ Yoshua Bengio (2009). "Learning Deep Architectures for AI.". Foundations and Trends in Machine Learning. 2 (1): 1–127. doi:10.1561/2200000006.
2002
- (Gers, Schraudolph & Schmidhuber, 2002) ⇒ Felix A. Gers, Nicol N. Schraudolph, and Jurgen Schmidhuber (2002). "Learning precise timing with LSTM recurrent networks". Journal of machine learning research, 3(Aug), 115-143.
2001
- (Gers & Schmidhuber, 2001) ⇒ Felix A. Gers, and Jürgen Schmidhuber, (2001). "LSTM Recurrent Networks Learn Simple Context Free and Context Sensitive Languages". IEEE Trans Neural Netw. 12 (6): 1333–1340. doi:10.1109/72.963769.
1998
- (LeCun et al., 1998) ⇒ Yann LeCun, Leon Bottou, Yoshua Bengio, and Patrick Haffne (1998). "Gradient-based learning applied to document recognition". Proceedings of the IEEE, 86(11), 2278-2324.
1997
- (Hochreiter & Schmidhuber, 1997) ⇒ Sepp Hochreiter and Jurgen Schmidhuber (1997). "Long short-term memory". Neural computation, 9(8), 1735-1780.
1992
- (Razborov, 1992) ⇒ Alexander A. Razborov (1992, July). "On small depth threshold circuits". In Scandinavian Workshop on Algorithm Theory (pp. 42-52). Springer, Berlin, Heidelberg.
1977
- (Fu, 1977) ⇒ King Sun Fu (1977) "Syntactic pattern recognition and applications". Springer, Berlin
1971
- (Ivakhnenko, 1971) ⇒ Aleksei Grigorevich Ivakhnenko (1971) "Polynomial theory of complex systems". IEEE Trans Syst Man Cybern (4):364–378
1965
- (Ivakhnenko & Lapa, 1965) ⇒ Aleksei Grigorevich Ivakhnenko, and Valentin Grigorevich Lapa (1965) Cybernetic Predicting Devices. CCM Information Corporation, New York