Neural Network Architecture
A Neural Network Architecture is a network topology for an artificial neural network.
- AKA: NNet Layout/Topology.
- Context:
- It can (typically) be composed of Neural Network Layers (N), Artificial Neurons, Artificial Neural Connections, and Neural Network Biases.
- It can (typically) have a Neural Network Input Layer ([math]\displaystyle{ N_{IL}=1 }[/math]) and a Neural Network Input Layer ([math]\displaystyle{ N_{OL}=1 }[/math]) and can have any number of Neural Network Input Layers ([math]\displaystyle{ N_{HL} }[/math]).
- It can (often) have Neural Network Hidden Layers, i.e. is called a (N-1) Hidden Layer Neural Network or a N-Layer Neural Network where [math]\displaystyle{ N=N_{HL}+N_{OL}=N_{HL}+1 }[/math].
- It can (typically) have a Neural Network Size, determined by number of Artificial Neurons, number of Neural Network Bias Neurons, number of Artificial Neural Connections.
- It can range from being being a Shallow Neural Network Architecture to being a Deep Neural Network Architecture.
- It can propagate by Neural Network Forwardpass, Neural Network Backwardpass and Neural Network Recurrent Loops.
- It can be described by a Artificial Neural Network Model, [math]\displaystyle{ M(X,Y,\Sigma,A) }[/math] where [math]\displaystyle{ X }[/math] is a Neural Network Input, [math]\displaystyle{ Y }[/math] is a Neural Network Output, [math]\displaystyle{ A }[/math] is a [math]\displaystyle{ \Sigma }[/math] is the Neural Network Adder Function, and [math]\displaystyle{ A }[/math] is the Neural Network Activation Function.
- ...
- Example(s):
- a Feed-Forward Neural Architecture, ...
- a Learnable Modular NNet Architecture, ...
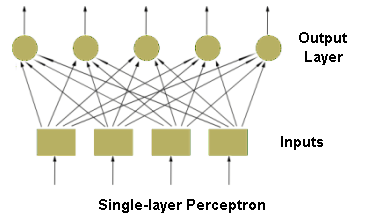
- a Single-Layer Perceptron Architecture (for a single-layer perceptron):
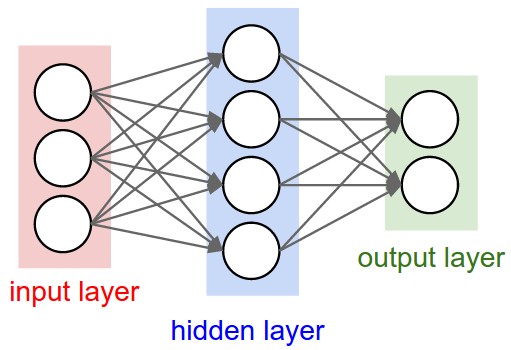
- a Multi-Layer Perceptron Architecture (for a multi-layer perceptron).
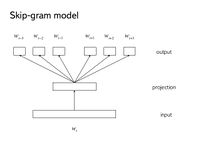
- a Skip-Gram Model Architecture (for a skip-gram model)
 .
. 

- a Transformer-based Architecture.
- …
- Counter-Example(s)
- See: Connectivity; Neural Network Layer; Model Structure.

References
2018
- (Santos, 2017) ⇒ https://leonardoaraujosantos.gitbooks.io/artificial-inteligence/content/neural_networks.html Retrieved: 2018-01-07
- QUOTE: Neural networks are examples of Non-Linear hypothesis, where the model can learn to classify much more complex relations. Also it scale better than Logistic Regression for large number of features.
It's formed by artificial neurons, where those neurons are organised in layers. We have 3 types of layers:
- QUOTE: Neural networks are examples of Non-Linear hypothesis, where the model can learn to classify much more complex relations. Also it scale better than Logistic Regression for large number of features.
- We classify the neural networks from their number of hidden layers and how they connect, for instance the network above have 2 hidden layers. Also if the neural network has/or not loops we can classify them as Recurrent or Feed-forward neural networks.
Neural networks from more than 2 hidden layers can be considered a deep neural network. The advantage of using more deep neural networks is that more complex patterns can be recognised.
- We classify the neural networks from their number of hidden layers and how they connect, for instance the network above have 2 hidden layers. Also if the neural network has/or not loops we can classify them as Recurrent or Feed-forward neural networks.
2017
- (CS231n, 2017) ⇒ http://cs231n.github.io/neural-networks-1/#layers Retrieved: 2017-12-31
- Neural Networks as neurons in graphs. Neural Networks are modeled as collections of neurons that are connected in an acyclic graph. In other words, the outputs of some neurons can become inputs to other neurons. Cycles are not allowed since that would imply an infinite loop in the forward pass of a network. Instead of an amorphous blobs of connected neurons, Neural Network models are often organized into distinct layers of neurons. For regular neural networks, the most common layer type is the fully-connected layer in which neurons between two adjacent layers are fully pairwise connected, but neurons within a single layer share no connections. Below are two example Neural Network topologies that use a stack of fully-connected layers:
|
|
|
Left: A 2-layer Neural Network (one hidden layer of 4 neurons (or units) and one output layer with 2 neurons), and three inputs. Right:A 3-layer neural network with three inputs, two hidden layers of 4 neurons each and one output layer. Notice that in both cases there are connections (synapses) between neurons across layers, but not within a layer. |
- Naming conventions. Notice that when we say N-layer neural network, we do not count the input layer. Therefore, a single-layer neural network describes a network with no hidden layers (input directly mapped to output). In that sense, you can sometimes hear people say that logistic regression or SVMs are simply a special case of single-layer Neural Networks. You may also hear these networks interchangeably referred to as “Artificial Neural Networks” (ANN) or “Multi-Layer Perceptrons” (MLP). Many people do not like the analogies between Neural Networks and real brains and prefer to refer to neurons as units.
Output layer. Unlike all layers in a Neural Network, the output layer neurons most commonly do not have an activation function (or you can think of them as having a linear identity activation function). This is because the last output layer is usually taken to represent the class scores (e.g. in classification), which are arbitrary real-valued numbers, or some kind of real-valued target (e.g. in regression).
Sizing neural networks. The two metrics that people commonly use to measure the size of neural networks are the number of neurons, or more commonly the number of parameters. Working with the two example networks in the above picture:
::* The first network (left) has [math]\displaystyle{ 4 + 2 = 6 }[/math] neurons (not counting the inputs), [math]\displaystyle{ [3 \times 4] + [4 \times 2] = 20 }[/math] weights and 4 + 2 = 6 biases, for a total of 26 learnable parameters.
- The second network (right) has [math]\displaystyle{ 4 + 4 + 1 = 9 }[/math] neurons, [math]\displaystyle{ [3 \times 4] + [4 \times 4] + [4 \times 1] = 12 + 16 + 4 = 32 }[/math] weights and [math]\displaystyle{ 4 + 4 + 1 = 9 }[/math] biases, for a total of 41 learnable parameters.
To give you some context, modern Convolutional Networks contain on orders of 100 million parameters and are usually made up of approximately 10-20 layers (hence deep learning).
- The second network (right) has [math]\displaystyle{ 4 + 4 + 1 = 9 }[/math] neurons, [math]\displaystyle{ [3 \times 4] + [4 \times 4] + [4 \times 1] = 12 + 16 + 4 = 32 }[/math] weights and [math]\displaystyle{ 4 + 4 + 1 = 9 }[/math] biases, for a total of 41 learnable parameters.
- Naming conventions. Notice that when we say N-layer neural network, we do not count the input layer. Therefore, a single-layer neural network describes a network with no hidden layers (input directly mapped to output). In that sense, you can sometimes hear people say that logistic regression or SVMs are simply a special case of single-layer Neural Networks. You may also hear these networks interchangeably referred to as “Artificial Neural Networks” (ANN) or “Multi-Layer Perceptrons” (MLP). Many people do not like the analogies between Neural Networks and real brains and prefer to refer to neurons as units.
2017c
- (Miikkulainen, 2017) ⇒ Miikkulainen R. (2017) "Topology of a Neural Network". In: Sammut, C., Webb, G.I. (eds) "Encyclopedia of Machine Learning and Data Mining". Springer, Boston, MA
- ABSTRACT: Topology of a neural network refers to the way the neurons are connected, and it is an important factor in how the network functions and learns. A common topology in unsupervised learning is a direct mapping of inputs to a collection of units that represents categories (e.g., Self-Organizing Maps). The most common topology in supervised learning is the fully connected, three-layer, feedforward network (see Backpropagation and Radial Basis Function Networks): All input values to the network are connected to all neurons in the hidden layer (hidden because they are not visible in the input or output), the outputs of the hidden neurons are connected to all neurons in the output layer, and the activations of the output neurons constitute the output of the whole network. Such networks are popular partly because they are known theoretically to be universal function approximators (with, e.g., a sigmoid or Gaussian nonlinearity in the hidden layer neurons), although networks with more layers may be easier to train in practice (e.g., Cascade-Correlation)
2016
- (Zhao, 2016) ⇒ Peng Zhao, 2016. "R for Deep Learning (I): Build Fully Connected Neural Network from Scratch".
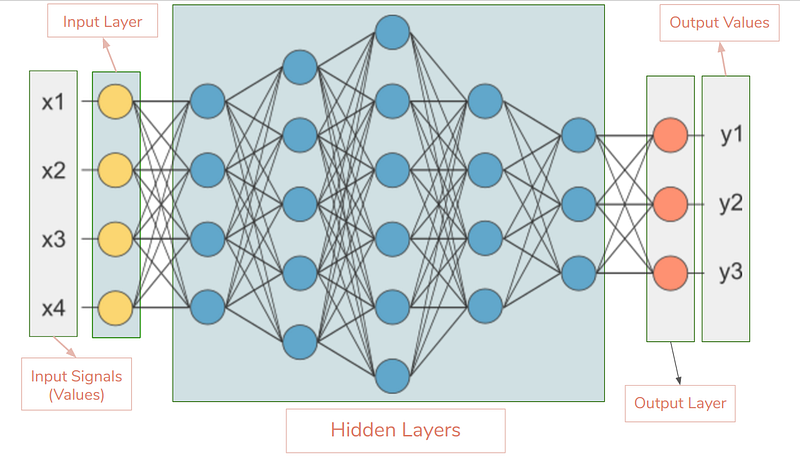
- QUOTE: Fully connected neural network, called DNN in data science, is that adjacent network layers are fully connected to each other. Every neuron in the network is connected to every neuron in adjacent layers.
A very simple and typical neural network is shown below with 1 input layer, 2 hidden layers, and 1 output layer. Mostly, when researchers talk about network’s architecture, it refers to the configuration of DNN, such as how many layers in the network, how many neurons in each layer, what kind of activation, loss function, and regularization are used.
- QUOTE: Fully connected neural network, called DNN in data science, is that adjacent network layers are fully connected to each other. Every neuron in the network is connected to every neuron in adjacent layers.

2005
- (Golda, 2005) ⇒ Adam Golda (2005). "Introduction to neural networks"
- QUOTE: There are different types of neural networks, which can be distinguished on the basis of their structure and directions of signal flow. Each kind of neural network has its own method of training. Generally, neural networks may be differentiated as follows
- Feedforward neural networks, which typical example is one-layer perceptron (see figure of Single-layer perceptron), consist of neurons set in layers. The information flow has one direction. Neurons from a layer are connected only with the neurons from the preceding layer. The multi-layer networks usually consist of input, hidden (one or more), and output layers. Such system may be treated as non-linear function approximation block: [math]\displaystyle{ y = f(u) }[/math].
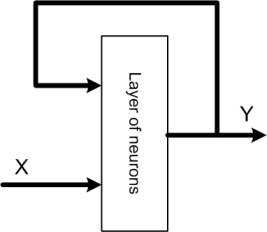
Recurrent neural networks. Such networks have feedback loops (at least one) output signals of a layer are connected to its inputs. It causes dynamic effects during network work. Input signals of layer consist of input and output states (from the previous step) of that layer. The structure of recurrent network depicts the below figure.
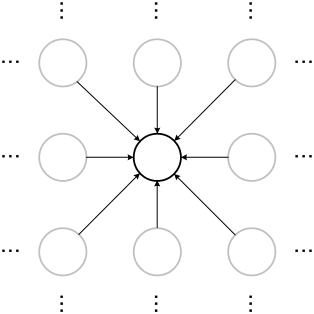
Cellular networks. In this type of neural networks neurons are arranged in a lattice. The connections (usually non-linear) may appear between the closest neurons. The typical example of such networks is Kohonen Self-Organising-Map.
 .
.
- Feedforward neural networks, which typical example is one-layer perceptron (see figure of Single-layer perceptron), consist of neurons set in layers. The information flow has one direction. Neurons from a layer are connected only with the neurons from the preceding layer. The multi-layer networks usually consist of input, hidden (one or more), and output layers. Such system may be treated as non-linear function approximation block: [math]\displaystyle{ y = f(u) }[/math].
2003
- (Aryal & Wang, 2003) ⇒ Aryal, D. R., & Wang, Y. W. (2003). Neural network Forecasting of the production level of Chinese construction industry. Journal of comparative international management, 6(2).
- QUOTE: The human brain is formed by over a billion neurons that are connected in a large network that is responsible for thought. An artificial neural network is just an attempt to imitate how the brain's networks of nerves learn. An ANN is a mathematical structure designed to mimic the information processing functions of a network of neurons in the brain (Hinton, 1992). Each neuron, individually, functions in a quite simple fashion. It receives signals from other cells through connection points (synapses), averages them and if the average over a short of time is greater than a certain value the neuron, produces another signal that is passed on to other cells. As Wasseman (1989) pointed out, it is the high degree of connectivity rather than the functional complexity of the neuron itself that gives the neuron its computational processing ability. Neural networks are very sophisticated modeling techniques, capable of modeling extremely complex functions. The neural network user gathers representative data, and then invokes training algorithms to automatically learn the structure of the data.
.