Gated Recurrent Neural Network
A Gated Recurrent Neural Network is a recurrent neural network that contains one or more hidden layers of GRUs. .
- Context:
- It can be trained by an GRU RNN Training System (that implements a GRU RNN training algorithm to solve an GRU RNN training task).
- It can range from being a Shallow GRU Network to being a Deep GRU Network.
- It can range from being a Unidirectional GRU Network to being a Bidirectional GRU Network.
- …
- Example(s):
- GRU1 RNN ("each gate is computed using only the previous hidden state and the bias."),
- GRU2 RNN ("each gate is computed using only the previous hidden state")
- GRU3 RNN ("each gate is computed using only the bias.").
- Gated Recursive Convolutional Neural Network (Cho et al., 2014b) ,
- …
- Counter-Example(s):
- See: Long Short-Term Memory (LSTM) Neural Network, Neural Network Gating Layer.
References
2018
- (Wikipedia, 2018) ⇒ https://en.wikipedia.org/wiki/Gated_recurrent_unit Retrieved:2018-3-4.
- Gated recurrent units (GRUs) are a gating mechanism in recurrent neural networks, introduced in 2014 by Kyunghyun Cho et al. [1]. Their performance on polyphonic music modeling and speech signal modeling was found to be similar to that of long short-term memory [2] . They have fewer parameters than LSTM, as they lack an output gate [3].
2017
- (Dey & Salem, 2017) ⇒ Rahul Dey, and Fathi M. Salem (2017). "Gate-variants of Gated Recurrent Unit (GRU) neural networks" In: 2017 IEEE 60th International Midwest Symposium on Circuits and Systems (MWSCAS), Boston, MA, 2017, pp. 1597-1600. doi: 10.1109/MWSCAS.2017.8053243
- QUOTE: : In principal, RNN are more suitable for capturing relationships among sequential data types. The so-called simple RNN has a recurrent hidden state as in [math]\displaystyle{ h_t=g(Wx_t+Uh_{t-1})+b\quad }[/math](1)
where [math]\displaystyle{ x_t }[/math] is the (external) m-dimensional input vector at time [math]\displaystyle{ t }[/math], [math]\displaystyle{ h_t }[/math] the n-dimensional hidden state, [math]\displaystyle{ g }[/math] is the (point-wise) activation function, such as the logistic function, the hyperbolic tangent function, or the rectified Linear Unit (ReLU) [2, 6], and [math]\displaystyle{ W }[/math], [math]\displaystyle{ U }[/math] and [math]\displaystyle{ b }[/math] are the appropriately sized parameters (two weights and bias). Specifically, in this case, [math]\displaystyle{ W }[/math] is an [math]\displaystyle{ n\times m }[/math] matrix, [math]\displaystyle{ U }[/math] is an [math]\displaystyle{ n\times n }[/math] matrix, and [math]\displaystyle{ b }[/math] is an [math]\displaystyle{ n\times 1 }[/math] matrix (or vector) (...)
The GRU RNN reduce the gating signals to two from the LSTM RNN model. The two gates are called an update gate [math]\displaystyle{ z_t }[/math]and a reset gate [math]\displaystyle{ r_t }[/math]. The GRU RNN model is presented in the form:
[math]\displaystyle{ h_t=(z-1)\odot h_{t-1}+z_t\odot\tilde{h_t}\quad }[/math](5)[math]\displaystyle{ \tilde{h_t}=g(W_hx_t+U_h(r_t\odot z_t h_{t-1})+b_h)\quad }[/math](6)with the two gates presented as:
[math]\displaystyle{ z_t=\sigma (W_rx_t+U_zh_{t-1}+b_z)\quad }[/math](7)[math]\displaystyle{ r_t=\sigma (W_rx_t+U_rh_{t-1}+b_r)\quad }[/math](8)(...) In essence, the GRU RNN has 3-folds increase in parameters in comparison to the simple RNN of Eqn (1). Specifically, the total number of parameters in the GRU RNN equals [math]\displaystyle{ 3\times (n^2 + nm +n) }[/math] (...)
- QUOTE: : In principal, RNN are more suitable for capturing relationships among sequential data types. The so-called simple RNN has a recurrent hidden state as in
2016
- (WILDML) ⇒ "Recurrent Neural Network Tutorial, Part 4 – Implementing a GRU/LSTM RNN with Python and Theano – WildML". Wildml.com. Retrieved May 18, 2016.
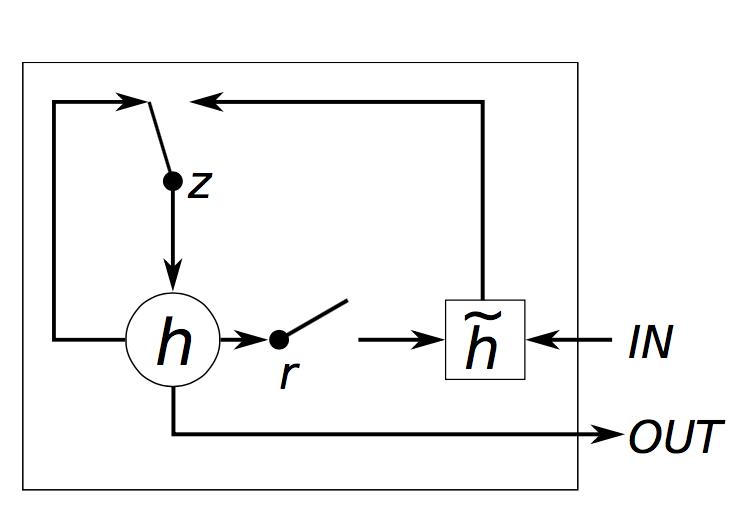
- QUOTE: The idea behind a GRU layer is quite similar to that of a LSTM layer, as are the equations.
[math]\displaystyle{ \begin{aligned} z &=\sigma(x_tU^z + s_{t-1} W^z) \\ r &=\sigma(x_t U^r +s_{t-1} W^r) \\ h &= tanh(x_t U^h + (s_{t-1} \circ r) W^h) \\ s_t &= (1 - z) \circ h + z \circ s_{t-1} \end{aligned} }[/math]
A GRU has two gates, a reset gate r, and an update gate z. Intuitively, the reset gate determines how to combine the new input with the previous memory, and the update gate defines how much of the previous memory to keep around. If we set the reset to all 1’s and update gate to all 0’s we again arrive at our plain RNN model. The basic idea of using a gating mechanism to learn long-term dependencies is the same as in a LSTM, but there are a few key differences:
- A GRU has two gates, an LSTM has three gates.
- GRUs don’t possess and internal memory (ct) that is different from the exposed hidden state. They don’t have the output gate that is present in LSTMs.
- The input and forget gates are coupled by an update gate z and the reset gate r is applied directly to the previous hidden state. Thus, the responsibility of the reset gate in a LSTM is really split up into both r and z.
- We don’t apply a second nonlinearity when computing the output.
- QUOTE: The idea behind a GRU layer is quite similar to that of a LSTM layer, as are the equations.
2014a
- (Cho et al., 2014a) ⇒ Kyunghyun Cho, Bart van Merrienboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio (2014). "Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation". arXiv:1406.1078
- ABSTRACT: In this paper, we propose a novel neural network model called RNN Encoder-Decoder that consists of two recurrent neural networks (RNN). One RNN encodes a sequence of symbols into a fixed-length vector representation, and the other decodes the representation into another sequence of symbols. The encoder and decoder of the proposed model are jointly trained to maximize the conditional probability of a target sequence given a source sequence. The performance of a statistical machine translation system is empirically found to improve by using the conditional probabilities of phrase pairs computed by the RNN Encoder-Decoder as an additional feature in the existing log-linear model. Qualitatively, we show that the proposed model learns a semantically and syntactically meaningful representation of linguistic phrases.
2014b
- (Cho et al., 2014b) ⇒ Kyunghyun Cho, Bart van Merrienboer, Dzmitry Bahdanau, and Yoshua Bengio. (2014). "On the Properties of Neural Machine Translation: Encoder-Decoder Approaches". In: Proceedings of Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation (SSST@EMNLP 2014). DOI:10.3115/v1/W14-4012
2014c
- (Chung et al., 2014) ⇒ Junyoung Chung, Caglar Gulcehre, KyungHyun Cho, and Yoshua Bengio (2014). "Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling". arXiv:1412.3555.
- QUOTE: It is easy to notice similarities between the LSTM unit and the GRU from Fig. 1.
The most prominent feature shared between these units is the additive component of their update from t to t + 1, which is lacking in the traditional recurrent unit. The traditional recurrent unit always replaces the activation, or the content of a unit with a new value computed from the current input and the previous hidden state. On the other hand, both LSTM unit and GRU keep the existing content and add the new content on top of it (...)
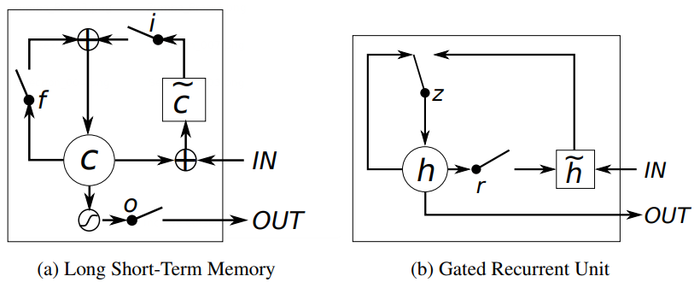
- QUOTE: It is easy to notice similarities between the LSTM unit and the GRU from Fig. 1.

- Figure 1: Illustration of (a) LSTM and (b) gated recurrent units. (a) [math]\displaystyle{ i }[/math], [math]\displaystyle{ f }[/math] and [math]\displaystyle{ o }[/math] are the input, forget and output gates, respectively. [math]\displaystyle{ c }[/math] and [math]\displaystyle{ \tilde{c} }[/math] denote the memory cell and the new memory cell content. (b) [math]\displaystyle{ r }[/math] and [math]\displaystyle{ z }[/math] are the reset and update gates, and [math]\displaystyle{ h }[/math] and [math]\displaystyle{ \tilde{h} }[/math] are the activation and the candidate activation.