Recurrent Neural Network (RNN)
A Recurrent Neural Network (RNN) is an multi hidden-layer neural network with neuron connections that are feedback connections (to form a directed cycle).
- Context:
- It can (typically) make use of a Unit Delay Operator, [math]\displaystyle{ d }[/math].
- It can (typically) be a Sequence-to-Sequence Neural Network.
- It can (often) be trained by a Recurrent Neural Network Training System (that implements a recurrent neural network training algorithm).
- ...
- It can range from being an Shallow Recurrent Neural Network to being an Deep Recurrent Neural Network.
- It can range from being a Unidirectional Recurrent Neural Network to being a Bidirectional Recurrent Neural Network.
- It can range from being a Recurrent Neural Network Instance to being an Abstract Recurrent Neural Network.
- It can range from being a Simple/Unidirectional RNN, to being a Bidirectional RNN, to being a Hierarchical RNN, to being a Second-Order RNN.
- It can range from being a Continuous Time RNN to being a Multiple Timescales RNN.
- It can range from being a Fully Recurrent Neural Network to being a Recursive Neural Network.
- ...
- It can update its internal state (have memory) on previous inputs (not just current inputs).
- It can be stacked into Neural History Compressors.
- It can be at used in Neural Turing Machines, Differentiable Neural Computers and Neural Network Pushdown Automata.
- It can more closely approximate an Animal Brain than a Feed-Forward ANN.
- ...
- Example(s):
- a Bidirectional Associative Memory (BAM) Network;
- a DAG Recurrent Neural Network;
- a Gated Recurrent Unit (GRU) Network (a simpler version with a reset gate and an update gate, but no output cell - which helps to remember most of the context).
- a Hopfield Recurrent Neural Network;
- a Jordan Network;
- a Long Short-Term Memory (LSTM) Network;
- a Recurrent Multilayer Perceptron Network;
- an Encoder-Decoder RNN.
- a seq2seq Network.
 .
. .
.- a Gated Feedback Recurrent Neural Network.
- …
- Counter-Example(s):
- a Feed-Forward Neural Network, such as a: convolutional NNet.
- a Radial Basis Function Network (uses radial basis functions instead of recurrent connections);
- a Perceptron (a simple single-layer neural network without feedback connections);
- a Deep Belief Network (a generative model that is not recurrent);
- a Transformer-based Network (uses self-attention mechanisms instead of recurrent connections).
- See: Recursive Neural Network, Handwriting Recognition, Speech Recognition, Directed Cycle.


References
2018a
- (Weiss et al., 2018) ⇒ Gail Weiss, Yoav Goldberg, and Eran Yahav. (2018). “On the Practical Computational Power of Finite Precision RNNs for Language Recognition.” In: arXiv:1805.04908 Journal.
- QUOTE: While Recurrent Neural Networks (RNNs) are famously known to be Turing complete, this relies on infinite precision in the states and unbounded computation time. We consider the case of RNNs with finite precision whose computation time is linear in the input length. Under these limitations, we show that different RNN variants have different computational power. In particular, we show that the LSTM and the Elman-RNN with ReLU activation are strictly stronger than the RNN with a squashing activation and the GRU. ...
2018b
- (Santos, 2018) ⇒ https://leonardoaraujosantos.gitbooks.io/artificial-inteligence/content/recurrent_neural_networks.html Retrieved: 2018-03-04
- QUOTE: On previous forward neural networks, our output was a function between the current input and a set of weights. On recurrent neural networks(RNN), the previous network state is also influenced by the output, so recurrent neural networks also have a "notion of time". This effect by a loop on the layer output to it's input.

In other words, the RNN will be a function with inputs (input vector) and previous state . The new state will be ... The recurrent function will be fixed after training and used to every time step.
Recurrent Neural Networks are the best model for regression, because it take into account past values.
RNN are computation “Turing Machines" which means, with the correct set of weights it can compute anything, imagine this weights as a program.
Just to not let you too overconfident on RNN, there is no automatic back-propagation algorithms, that will find this "perfect set of weights".
- QUOTE: On previous forward neural networks, our output was a function between the current input and a set of weights. On recurrent neural networks(RNN), the previous network state is also influenced by the output, so recurrent neural networks also have a "notion of time". This effect by a loop on the layer output to it's input.
2017a
- (Wikipedia, 2017) ⇒ https://en.wikipedia.org/wiki/recurrent_neural_network Retrieved:2017-6-26.
- A recurrent neural network (RNN) is a class of artificial neural network where connections between units form a directed cycle. This creates an internal state of the network which allows it to exhibit dynamic temporal behavior. Unlike feedforward neural networks, RNNs can use their internal memory to process arbitrary sequences of inputs. ...
2017b
- Luis Serrano. (2017). “Friendly Introduction to Recurrent Neural Networks." YouTube Vlog post
- QUOTE: A friendly explanation of how computers predict and generate sequences, based on Recurrent Neural Networks.
2017c
- "Deep Learning: Practice and Trends (NIPS 2017 Tutorial, parts I & II)."
- QUOTE: RNN intro section
2017d
- (Gibson & Patterson, 2017) ⇒ Adam Gibson, Josh Patterson (2017). "Chapter 4. Major Architectures of Deep Networks". In: "Deep Learning" ISBN: 9781491924570.
- QUOTE: Recurrent Neural Networks are in the family of feed-forward neural networks. They are different from other feed-forward networks in their ability to send information over time-steps. Here’s an interesting explanation of Recurrent Neural Networks from leading researcher Juergen Schmidhuber:
Recurrent Neural Networks allow for both parallel and sequential computation, and in principle can compute anything a traditional computer can compute. Unlike traditional computers, however, Recurrent Neural Networks are similar to the human brain, which is a large feedback network of connected neurons that somehow can learn to translate a lifelong sensory input stream into a sequence of useful motor outputs. The brain is a remarkable role model as it can solve many problems current machines cannot yet solve.
Historically, these networks have been difficult to train, but more recently, advances in research (optimization, network architectures, parallelism, and graphics processing units (GPUs)) have made them more approachable for the practitioner.
Recurrent Neural Networks take each vector from a sequence of input vectors and model them one at a time. This allows the network to retain state while modeling each input vector across the window of input vectors. Modeling the time dimension is a hallmark of Recurrent Neural Networks (...)
A Recurrent Neural Network includes a feedback loop that it uses to learn from sequences, including sequences of varying lengths. Recurrent Neural Networks contain an extra parameter matrix for the connections between time-steps, which are used/trained to capture the temporal relationships in the data.
Recurrent Neural Networks are trained to generate sequences, in which the output at each time-step is based on both the current input and the input at all previous time steps. Normal Recurrent Neural Networks compute a gradient with an algorithm called backpropagation through time (BPTT).
- QUOTE: Recurrent Neural Networks are in the family of feed-forward neural networks. They are different from other feed-forward networks in their ability to send information over time-steps. Here’s an interesting explanation of Recurrent Neural Networks from leading researcher Juergen Schmidhuber:
2017 e.
- (Schmidhuber, 2017) ⇒ Schmidhuber, J. (2017) "Deep Learning". In: Sammut, C., Webb, G.I. (eds) "Encyclopedia of Machine Learning and Data Mining". Springer, Boston, MA
- QUOTE: Supervised long short-term memory (LSTM) RNNs have been developed since the 1990s (e.g., Hochreiter and Schmidhuber 1997b; Gers and Schmidhuber 2001; Graves et al. 2009). Parts of LSTM RNNs are designed such that backpropagated errors can neither vanish nor explode but flow backward in “civilized” fashion for thousands or even more steps. Thus, LSTM variants could learn previously unlearnable very deep learning tasks (including some unlearnable by the 1992 history compressor above) that require to discover the importance of (and memorize) events that happened thousands of discrete time steps ago, while previous standard RNNs already failed in case of minimal time lags of ten steps. It is possible to evolve good problem-specific LSTM-like topologies (Bayer et al. 2009).
Recursive NNs (Goller and Küchler 1996) generalize RNNs, by operating on hierarchical structures, recursively combining child representations into parent representations. Bidirectional RNNs (BRNNs) (Schuster and Paliwal 1997) are designed for input sequences whose starts and ends are known in advance, such as spoken sentences to be labeled by their phonemes. DAG-RNNs (Baldi and Pollastri 2003) generalize BRNNs to multiple dimensions. Recursive NNs, BRNNs, and DAG-RNNs unfold their full potential when combined with LSTM (Graves et al. 2009).
Particularly successful in competitions were stacks of LSTM RNNs (Fernandez et al. 2007b) trained by connectionist temporal classification (CTC, Graves et al. 2006), a gradient-based method for finding RNN weights that maximize the probability of teacher-given label sequences, given (typically much longer and more high-dimensional) streams of real-valued input vectors. CTC performs simultaneous segmentation (alignment) and recognition. In 2009, CTC-trained LSTM became the first RNN to win controlled international contests, namely, three competitions in connected handwriting recognition. Hannun et al. (2014) used CTC-trained RNNs to break a famous speech recognition benchmark record, without using any traditional speech processing methods such as hidden Markov models (HMMs) or Gaussian mixture models (...)
- QUOTE: Supervised long short-term memory (LSTM) RNNs have been developed since the 1990s (e.g., Hochreiter and Schmidhuber 1997b; Gers and Schmidhuber 2001; Graves et al. 2009). Parts of LSTM RNNs are designed such that backpropagated errors can neither vanish nor explode but flow backward in “civilized” fashion for thousands or even more steps. Thus, LSTM variants could learn previously unlearnable very deep learning tasks (including some unlearnable by the 1992 history compressor above) that require to discover the importance of (and memorize) events that happened thousands of discrete time steps ago, while previous standard RNNs already failed in case of minimal time lags of ten steps. It is possible to evolve good problem-specific LSTM-like topologies (Bayer et al. 2009).
2016
- (Olah & Carter, 2016) ⇒ Chris Olah, and Shan Carter. (2016). “Attention and Augmented Recurrent Neural Networks.” In: Distill. doi:10.23915/distill.00001
- QUOTE: Recurrent neural networks are one of the staples of deep learning, allowing neural networks to work with sequences of data like text, audio and video. They can be used to boil a sequence down into a high-level understanding, to annotate sequences, and even to generate new sequences from scratch!
2016
- (Garcia et al., 2016) ⇒ García Benítez, S. R., López Molina, J. A., & Castellanos Pedroza, V. (2016). "Neural networks for defining spatial variation of rock properties in sparsely instrumented media". Boletín de la Sociedad Geológica Mexicana, 68(3), 553-570.
- QUOTE: The standard feedforward NN, or multilayer perceptron (MLP), is the best-known member of the family of many types of neural networks (Haykin, 1999). Even though MLP has been successfully applied in tasks of prediction and classification (Egmont-Petersen et al., 2002; Theodoridis and Koutroumbas, 2009). In this investigation, a recurrent neural network (RNN, or neural networks for temporal processing) is used for extending the feedforward networks with the capability of dynamic operation.
In a RNN the network behaviour depends not only on the current input (as in normal feedforward networks) but also on previous operations of the network. The RNN gains knowledge by recurrent connections where the neuron outputs are fed back into the network as additional inputs (Graves, 2012). The fundamental feature of a RNN is that the network contains at least one feedback connection, so that activation can flow around in a loop. This enables the networks to perform temporal processing and to learn sequences (e.g. , perform sequence recognition/reproduction or temporal association/prediction). The learning capability of the network can be achieved by similar gradient descent procedures to those used to derive the backpropagation algorithm for feedforward networks (Hinton and Salakhutdinov, 2006) (...)
- QUOTE: The standard feedforward NN, or multilayer perceptron (MLP), is the best-known member of the family of many types of neural networks (Haykin, 1999). Even though MLP has been successfully applied in tasks of prediction and classification (Egmont-Petersen et al., 2002; Theodoridis and Koutroumbas, 2009). In this investigation, a recurrent neural network (RNN, or neural networks for temporal processing) is used for extending the feedforward networks with the capability of dynamic operation.
2015
- (Karpathy, 2015) ⇒ Andrej Karpathy. (2015). “The Unreasonable Effectiveness of Recurrent Neural Networks." May 21, 2015
- QUOTE: ... What makes Recurrent Networks so special? A glaring limitation of Vanilla Neural Networks (and also Convolutional Networks) is that their API is too constrained: they accept a fixed-sized vector as input (e.g. an image) and produce a fixed-sized vector as output (e.g. probabilities of different classes). Not only that: These models perform this mapping using a fixed amount of computational steps (e.g. the number of layers in the model). The core reason that recurrent nets are more exciting is that they allow us to operate over sequences of vectors: Sequences in the input, the output, or in the most general case both. A few examples may make this more concrete:

...RNNs combine the input vector with their state vector with a fixed (but learned) function to produce a new state vector. This can in programming terms be interpreted as running a fixed program with certain inputs and some internal variables. Viewed this way, RNNs essentially describe programs. ...
- QUOTE: ... What makes Recurrent Networks so special? A glaring limitation of Vanilla Neural Networks (and also Convolutional Networks) is that their API is too constrained: they accept a fixed-sized vector as input (e.g. an image) and produce a fixed-sized vector as output (e.g. probabilities of different classes). Not only that: These models perform this mapping using a fixed amount of computational steps (e.g. the number of layers in the model). The core reason that recurrent nets are more exciting is that they allow us to operate over sequences of vectors: Sequences in the input, the output, or in the most general case both. A few examples may make this more concrete:
2015b
- (Olah, 2015) ⇒ Christopher Olah. (2015). “Understanding LSTM Networks.” GITHUB blog 2015-08-27
- QUOTE: A recurrent neural network can be thought of as multiple copies of the same network, each passing a message to a successor. Consider what happens if we unroll the loop:
 This chain-like nature reveals that recurrent neural networks are intimately related to sequences and lists. They’re the natural architecture of neural network to use for such data.
This chain-like nature reveals that recurrent neural networks are intimately related to sequences and lists. They’re the natural architecture of neural network to use for such data.
- QUOTE: A recurrent neural network can be thought of as multiple copies of the same network, each passing a message to a successor. Consider what happens if we unroll the loop:
2014
- Jürgen Schmidhuber. (2014). “Jürgen Schmidhuber's page on Recurrent Neural Networks."
- QUOTE: The human brain is a recurrent neural network (RNN): a network of neurons with feedback connections.
2013a
- (Kaushik, 2013) ⇒ Saroj Kaushik. (2013). “Artificial Neural Network - Lecture Model 22”. Course Material
2013b
- (Mesnil et al., 2013) ⇒ Grégoire Mesnil, Xiaodong He, Li Deng, and Yoshua Bengio. (2013). “Investigation of Recurrent-neural-network Architectures and Learning Methods for Spoken Language Understanding.” In: Interspeech, pp. 3771-3775.
- ABSTRACT: One of the key problems in spoken language understanding (SLU) is the task of slot filling. In light of the recent success of applying deep neural network technologies in domain detection and intent identification, we carried out an in-depth investigation on the use of recurrent neural networks for the more difficult task of slot filling involving sequence discrimination. In this work, we implemented and compared several important recurrent-neural-network architectures, including the Elman-type and Jordan-type recurrent networks and their variants. To make the results easy to reproduce and compare, we implemented these networks on the common Theano neural network toolkit, and evaluated them on the ATIS benchmark. We also compared our results to a conditional random fields (CRF) baseline. Our results show that on this task, both types of recurrent networks outperform the CRF baseline substantially, and a bi-directional Jordan-type network that takes into account both past and future dependencies among slots works best, outperforming a CRF-based baseline by 14% in relative error reduction.
2013c
- (Grossberg,2013) ⇒ Stephen Grossberg (2013), Recurrent neural networks"Scholarpedia, 8(2):1888. doi:10.4249/scholarpedia.1888
- QUOTE: A recurrent neural network (RNN) is any network whose neurons send feedback signals to each other. This concept includes a huge number of possibilities. A number of reviews already exist of some types of RNNs. These include [1], [2], [3], [4].
Typically, these reviews consider RNNs that are artificial neural networks (aRNN) useful in technological applications. To complement these contributions, the present summary focuses on biological recurrent neural networks (bRNN) that are found in the brain. Since feedback is ubiquitous in the brain, this task, in full generality, could include most of the brain's dynamics. The current review divides bRNNS into those in which feedback signals occur in neurons within a single processing layer, which occurs in networks for such diverse functional roles as storing spatial patterns in short-term memory, winner-take-all decision making, contrast enhancement and normalization, hill climbing, oscillations of multiple types (synchronous, traveling waves, chaotic), storing temporal sequences of events in working memory, and serial learning of lists; and those in which feedback signals occur between multiple processing layers, such as occurs when bottom-up adaptive filters activate learned recognition categories and top-down learned expectations focus attention on expected patterns of critical features and thereby modulate both types of learning.
- QUOTE: A recurrent neural network (RNN) is any network whose neurons send feedback signals to each other. This concept includes a huge number of possibilities. A number of reviews already exist of some types of RNNs. These include [1], [2], [3], [4].
2013
- (Graves et al., 2013) ⇒ Alex Graves, Navdeep Jaitly, and Abdel-rahman Mohamed. (2013). “Hybrid Speech Recognition with Deep Bidirectional LSTM.” In: Proceedings of 2013 IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU-2013).
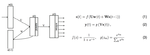
- QUOTE: Given an input sequence [math]\displaystyle{ x = (x_1, ..., x_T) }[/math], a standard recurrent neural network (RNN) computes the hidden vector sequence [math]\displaystyle{ h = (h_1, ..., h_T) }[/math] and output vector sequence [math]\displaystyle{ y = (y_1, ..., y_T) }[/math] by iterating the following equations from t = 1 to T:
[math]\displaystyle{ h_t = \mathcal{H}(W_xh_{xt} + W_{hh}h_{t-1} + b_h) (1) }[/math]
[math]\displaystyle{ y_t = W_hy_{ht} + b_y (2) }[/math]
where the W terms denote weight matrices (e.g. Wxh is the input-hidden weight matrix), the b terms denote bias vectors (e.g. bh is hidden bias vector) and H is the hidden layer function.
- QUOTE: Given an input sequence [math]\displaystyle{ x = (x_1, ..., x_T) }[/math], a standard recurrent neural network (RNN) computes the hidden vector sequence [math]\displaystyle{ h = (h_1, ..., h_T) }[/math] and output vector sequence [math]\displaystyle{ y = (y_1, ..., y_T) }[/math] by iterating the following equations from t = 1 to T:
2011
- (Sammut & Webb, 2011) ⇒ Claude Sammut, and Geoffrey I. Webb. (2011). “Simple Recurrent Network.” In: (Sammut & Webb, 2011) p.906
- QUOTE: The simple recurrent network is a specific version of the backpropagation neural network that makes it possible to process sequential input and output (Elman 1990). It is typically a three-layer network where a copy of the hidden layer activations is saved and used (in addition to the actual input) as input to the hidden layer in the next time step. The previous hidden layer is fully connected to the hidden layer. Because the network has no recurrent connections per se (only a copy of the activation values), the entire network (including the weights from the previous hidden layer to the hidden layer) can be trained with the backpropagation algorithm as usual. It can be trained to read a sequence of inputs into a target output pattern, to generate a sequence of outputs from a given input pattern, or to map an input sequence to an output sequence (as in predicting the next input). Simple recurrent networks have been particularly useful in time series prediction, as well as in modeling cognitive processes, such as language understanding and production.
2005
- (Golda, 2005) ⇒ Adam Golda (2005). "Introduction to neural networks"
- QUOTE: Recurrent neural networks. Such networks have feedback loops (at least one) output signals of a layer are connected to its inputs. It causes dynamic effects during network work. Input signals of layer consist of input and output states (from the previous step) of that layer. The structure of recurrent network depicts the below figure.
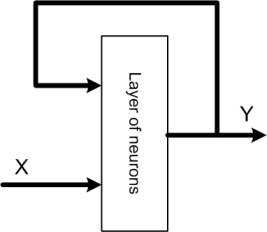
- QUOTE: Recurrent neural networks. Such networks have feedback loops (at least one) output signals of a layer are connected to its inputs. It causes dynamic effects during network work. Input signals of layer consist of input and output states (from the previous step) of that layer. The structure of recurrent network depicts the below figure.