Conditional Random Field Structure
(Redirected from trained CRF model)
A Conditional Random Field Structure is an undirected conditional probability network that is a member of a CRF family.
- AKA: CRF-based Model, CRF Network.
- Context:
- It can (typically) represent a (set of) conditional distribution p(y|x) such that for any fixed x and factor graph [math]\displaystyle{ G }[/math] over [math]\displaystyle{ Y }[/math], p(y|x) factorizes according to G.
- Every conditional distribution p(y|x) is a CRF for some, perhaps trivial, factor graph.
- It can range from (typically) being a Trained CRF (produced by CRF training) to being an Expert-Configured CRF.
- It can be used by a CRF Inference Task (that can be solved by a CRF inference system (that applies a CRF inference algorithm)
- It can be a CRF-based Sequence Tagging Function/CRF-based Tagger (a finite-state sequence tagging model for a Sequence Labeling Task)
- It can range from being a Small CRF to being a Medium CRF, to being a Large CRF.
- It can use:
- It can be applied to:
- Supervised Part-of-Speech Tagging (Lafferty et al., 2001).
- Supervised High-level Activity Extraction (Liao et al., 2007).
- Supervised Image Segmentation (Reynolds & Murphy, 2007); (Verbeek & Triggs, 2007).
- Supervised Object Recognition (Quattoni et al., 2004).
- Supervised Named Entity Recognition, (Sutton & McCallum, 2007); Stanford Named Entity Recognizer System.
- Supervised Concept Mention Identification, (Melli, 2010b).
- Example(s):
- the Linear-CRF Network developed in (Melli, 2010).
- a BI-LSTM-CRF Network.
- a LSTM-CRF Network.
- …
- Counter-Example(s):
- See: Label Bias; Joint Probability; CRF Modeling Task; CRF Inferencing Task.
References
2015
- (Huang, Xu & Yu, 2015) ⇒ Zhiheng Huang, Wei Xu, Kai Yu (2015). "Bidirectional LSTM-CRF models for sequence tagging (PDF)". arXiv preprint arXiv:1508.01991.
- QUOTE: There are two different ways to make use of neighbor tag information in predicting current tags. The first is to predict a distribution of tags for each time step and then use beam-like decoding to find optimal tag sequences. The work of maximum entropy classifier (Ratnaparkhi, 1996) and Maximum entropy Markov models (MEMMs) (McCallum et al., 2000) fall in this category. The second one is to focus on sentence level instead of individual positions, thus leading to Conditional Random Fields (CRF) models (Lafferty et al., 2001) (Fig. 5). Note that the inputs and outputs are directly connected, as opposed to LSTM and bidirectional LSTM networks where memory cells/recurrent components are employed. It has been shown that CRFs can produce higher tagging accuracy in general. .
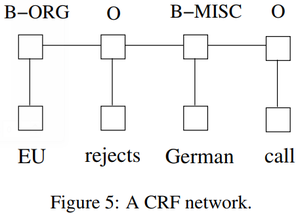
- QUOTE: There are two different ways to make use of neighbor tag information in predicting current tags. The first is to predict a distribution of tags for each time step and then use beam-like decoding to find optimal tag sequences. The work of maximum entropy classifier (Ratnaparkhi, 1996) and Maximum entropy Markov models (MEMMs) (McCallum et al., 2000) fall in this category. The second one is to focus on sentence level instead of individual positions, thus leading to Conditional Random Fields (CRF) models (Lafferty et al., 2001) (Fig. 5). Note that the inputs and outputs are directly connected, as opposed to LSTM and bidirectional LSTM networks where memory cells/recurrent components are employed. It has been shown that CRFs can produce higher tagging accuracy in general.

2007a
- (Sutton & McCallum, 2007) ⇒ Charles Sutton, and Andrew McCallum. (2007). “An Introduction to Conditional Random Fields for Relational Learning.” In: (Getoor & Taskar, 2007).
- QUOTE: Let [math]\displaystyle{ G }[/math] be a factor graph over [math]\displaystyle{ Y }[/math] . Then [math]\displaystyle{ p(y|x) }[/math] is a conditional random field if for any fixed [math]\displaystyle{ x }[/math], the distribution [math]\displaystyle{ \it{p}(\bf{y}|\bf{x}) }[/math] factorizes according to [math]\displaystyle{ \it{G} }[/math]. Thus, every conditional distribution [math]\displaystyle{ \it{p}(\bf{y} \vert \bf{x}) }[/math] is a CRF for some, perhaps trivial, factor graph.
… We will occasionally use the term random field to refer to a particular distribution among those defined by an undirected model. To reiterate, we will consistently use the term model to refer to a family of distributions, and random field (or more commonly, distribution) to refer to a single one.
- QUOTE: Let [math]\displaystyle{ G }[/math] be a factor graph over [math]\displaystyle{ Y }[/math] . Then [math]\displaystyle{ p(y|x) }[/math] is a conditional random field if for any fixed [math]\displaystyle{ x }[/math], the distribution [math]\displaystyle{ \it{p}(\bf{y}|\bf{x}) }[/math] factorizes according to [math]\displaystyle{ \it{G} }[/math]. Thus, every conditional distribution [math]\displaystyle{ \it{p}(\bf{y} \vert \bf{x}) }[/math] is a CRF for some, perhaps trivial, factor graph.
2007b
- (Liao et al., 2007) ⇒ L. Liao, D. Fox, and H. Kautz. (2007). “Extracting Places and Activities from GPS Traces Using Hierarchical Conditional Random Fields.” In: International Journal of Robotics Research.
2007c
- (Verbeek & Triggs, 2007) ⇒ J. Verbeek and B. Triggs. (2007). “Scene Segmentation with Conditional Random Fields Learned from Partially Labeled Examples.” In: Proceedings of Neural Information Processing Systems.
2006
- (McCallum, 2006) ⇒ Andrew McCallum. (2006). “Information Extraction, Data Mining and Joint Inference." Invited Talk at SIGKDD Conference (KDD-2006).
- QUOTE: First explorations with these models centered on finite state models, represented as linear-chain graphical models, with joint probability distribution over state sequence Y calculated as a normalized product over potentials on cliques of the graph. As is often traditional in NLP and other application areas, these potentials are defined to be log-linear combination of weights on features of the clique values. The chief excitement from an application point of view is the ability to use rich and arbitrary features of the input without complicating inference.
- CRFs have achieved state-of-the-art results in
- Noun phrase, Named entity HLT 2003, McCallum & Li @ CoNLL’03.
- Protein structure prediction ICML 2004.
- IE from Bioinformatics text Bioinformatics 2004.
- Asian word segmentation COLING 2004, ACL 2004.
- IE from Research papers HTL 2004.
- Object classification in images CVPR 2004
- QUOTE: First explorations with these models centered on finite state models, represented as linear-chain graphical models, with joint probability distribution over state sequence Y calculated as a normalized product over potentials on cliques of the graph. As is often traditional in NLP and other application areas, these potentials are defined to be log-linear combination of weights on features of the clique values. The chief excitement from an application point of view is the ability to use rich and arbitrary features of the input without complicating inference.
2004
- (Quattoni et al., 2004) ⇒ Ariadna Quattoni, Michael Collins, and Trevor Darrel. (2004). “Conditional Random Fields for Object Recognition.” In: Proceedings of Neural Information Processing Systems (NIPS 2004).
2001
- (Lafferty et al., 2001) ⇒ John D. Lafferty, Andrew McCallum, and Fernando Pereira. (2001). “Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data.” In: Proceedings of ICML Conference (ICML 2001).