Bidirectional Encoder Representations from Transformers (BERT) Language Model Training System
A Bidirectional Encoder Representations from Transformers (BERT) Language Model Training System is an Transformer-based LM training system that implements a BERT algorithm to solve a BERT task (to produce BERT LMs based on a BERT meta-model).
- Context:
- It can (often) be associated with a BERT LM Model Inference System.
- It can range from being a Fine-Tuning Based BERT System to being a Feature-based BERT System.
- …
- Example(s):
- Counter-Example
- See: General Language Understanding Evaluation (GLUE) Benchmark, Natural Language Understanding Task, Natural Language Processing System, Bidirectional Neural Network, Unsupervised Machine Learning System, .
References
2020
- (Rogers et al., 2020) ⇒ Anna Rogers, Olga Kovaleva, and Anna Rumshisky. (2020). “A Primer in Bertology: What We Know About how Bert Works.” In: Transactions of the Association for Computational Linguistics, 8.
- QUOTE: Transformer-based models have pushed state of the art in many areas of NLP, but our understanding of what is behind their success is still limited. This paper is the first survey of over 150 studies of the popular BERT model. We review the current state of knowledge about how BERT works, what kind of information it learns and how it is represented, common modifications to its training objectives and architecture, the overparameterization issue and approaches to compression.
2019a
- (Devlin et al., 2019) ⇒ Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. (2019). “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.” In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT 2019), Volume 1 (Long and Short Papers). DOI:10.18653/v1/N19-1423. arXiv:1810.04805
- QUOTE: We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation models, BERT is designed to pre-train deep bidirectional representations by jointly conditioning on both left and right context in all layers (...)
A distinctive feature of BERT is its unified architecture across different tasks. There is minimal difference between the pre-trained architecture and the final downstream architecture.
Model Architecture: BERT’s model architecture is a multi-layer bidirectional Transformer encoder (...)
Input/Output Representations: To make BERT handle a variety of down-stream tasks, our input representation is able to unambiguously represent both a single sentence and a pair of sentences (e.g., [math]\displaystyle{ \langle \text{Question, Answer}\rangle }[/math]) in one token sequence(...)
...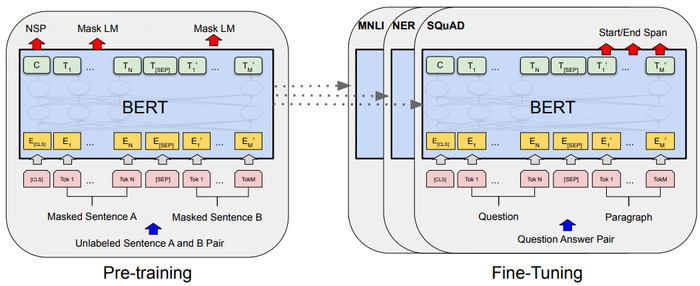
Figure 1: Differences in pre-training model architectures. BERT uses a bidirectional Transformer. OpenAI GPT uses a left-to-right Transformer. ELMo uses the concatenation of independently trained left-to-right and right-to-left LSTM to generate features for downstream tasks. Among three, only BERT representations are jointly conditioned on both left and right context in all layers. ...
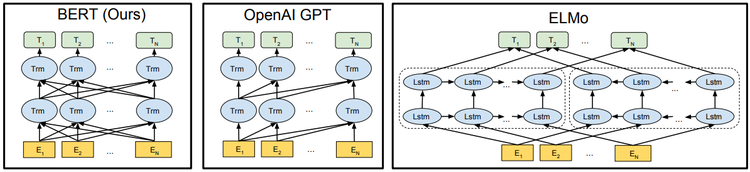
Figure 3: Differences in pre-training model architectures. BERT uses a bidirectional Transformer. OpenAI GPT uses a left-to-right Transformer. ELMo uses the concatenation of independently trained left-to-right and rightto-left LSTM to generate features for downstream tasks. Among three, only BERT representations are jointly conditioned on both left and right context in all layers. In addition to the architecture differences, BERT and OpenAI GPT are fine-tuning approaches, while ELMo is a feature-based approach.
- QUOTE: We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation models, BERT is designed to pre-train deep bidirectional representations by jointly conditioning on both left and right context in all layers (...)


2019b
- (Github, 2019) ⇒ https://github.com/google-research/bert
- QUOTE: BERT, or Bidirectional Encoder Representations from Transformers, is a new method of pre-training language representations which obtains state-of-the-art results on a wide array of Natural Language Processing (NLP) tasks(...)
BERT is a method of pre-training language representations, meaning that we train a general-purpose "language understanding" model on a large text corpus (like Wikipedia), and then use that model for downstream NLP tasks that we care about (like question answering). BERT outperforms previous methods because it is the first unsupervised, deeply bidirectional system for pre-training NLP. Unsupervised means that BERT was trained using only a plain text corpus, which is important because an enormous amount of plain text data is publicly available on the web in many languages.
Pre-trained representations can also either be context-free or contextual, and contextual representations can further be unidirectional or bidirectional. Context-free models such as word2vec or GloVe generate a single "word embedding" representation for each word in the vocabulary, so bank would have the same representation in bank deposit and river bank. Contextual models instead generate a representation of each word that is based on the other words in the sentence.
BERT was built upon recent work in pre-training contextual representations — including Semi-supervised Sequence Learning, Generative Pre-Training, ELMo, and ULMFit -- but crucially these models are all unidirectional or shallowly bidirectional. This means that each word is only contextualized using the words to its left (or right).
- QUOTE: BERT, or Bidirectional Encoder Representations from Transformers, is a new method of pre-training language representations which obtains state-of-the-art results on a wide array of Natural Language Processing (NLP) tasks(...)
2019b
- (Liu et al., 2019) ⇒ Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. (2019). “RoBERTa: A Robustly Optimized BERT Pretraining Approach.” In: CoRR, abs/1907.11692.
- QUOTE: ... We find that BERT was significantly undertrained, and can match or exceed the performance of every model published after it. Our best model achieves state-of-the-art results on GLUE, RACE and SQuAD. These results highlight the importance of previously overlooked design choices, and raise questions about the source of recently reported improvements.
2018a
- https://ai.googleblog.com/search/label/Natural%20Language%20Understanding
- QUOTE: This week, we open sourced a new technique for NLP pre-training called Bidirectional Encoder Representations from Transformers, or BERT. With this release, anyone in the world can train their own state-of-the-art question answering system (for a variety of other models) in about 30 minutes on a single Cloud TPU, or in a few hours using a single GPU.
2018b
- https://github.com/google-research/bert/blob/master/README.md
- QUOTE: ... BERT is a method of pre-training language representations, meaning that we train a general-purpose "language understanding" model on a large text corpus (like Wikipedia), and then use that model for downstream NLP tasks that we care about (like question answering). BERT outperforms previous methods because it is the first unsupervised, deeply bidirectional system for pre-training NLP.
Unsupervised means that BERT was trained using only a plain text corpus, which is important because an enormous amount of plain text data is publicly available on the web in many languages. …
- QUOTE: ... BERT is a method of pre-training language representations, meaning that we train a general-purpose "language understanding" model on a large text corpus (like Wikipedia), and then use that model for downstream NLP tasks that we care about (like question answering). BERT outperforms previous methods because it is the first unsupervised, deeply bidirectional system for pre-training NLP.