Coreference Resolution System
A Coreference Resolution System is a clustering system that can solve a coreference resolution task by means of a coreference resolution algorithm.
- Context:
- It can range from being a Rule-based Coreference Resolution System to being a Classification-based Coreference Resolution System.
- It can range from being a Supervised Coreference Resolution System to being a Unsupervised Coreference Resolution System.
- It can range from being a Statistical Coreference Resolution System to being a Graphical Coreference Resolution System.
- It can range from being a Cluster-based Coreference Resolution System, to being a Pairwise Coreference Resolution System, to being a Rank-based Coreference Resolution System.
- It can be tested against a Coreference Resolution Benchmark Task.
- …
- Example(s):
- An Entity-Centric Coreference Resolution System, such as: Author Disambiguation System, Citation Matching System, a Person Mention Coreference Resolution.
- An AllSingleton Coreference Resolution System,
- A Better Baseline Coreference Resolution System,
- A Centroid-based Joint Canonicalization-Coreference Resolution System,
- An Easy-First Coreference Resolution System,
- An Entity Mention Coreference Resolution System,
- An Incremental Entity-Mention Coreference Resolution System,
- A Mention-Pair Coreference Resolution System,
- A Multi-Pass Sieve Coreference Resolution System,
- An OneCluster Coreference Resolution System,
- A Beautiful Anaphora Resolution Toolkit (BART),
- GUITAR, JAVARAP, LingPipe Coreference Resolution System.
- …
- Counter-Example(s):
- See: Anaphora Resolution System, Entity Mention Normalization System, Information Extraction System.
References
2019
- (Wikipedia, 2019) ⇒ https://en.wikipedia.org/wiki/Coreference#Coreference_resolution Retrieved:2019-3-15.
- In computational linguistics, coreference resolution is a well-studied problem in discourse. To derive the correct interpretation of a text, or even to estimate the relative importance of various mentioned subjects, pronouns and other referring expressions must be connected to the right individuals. Algorithms intended to resolve coreferences commonly look first for the nearest preceding individual that is compatible with the referring expression. For example, she might attach to a preceding expression such as the woman or Anne, but not to Bill. Pronouns such as himself have much stricter constraints. Algorithms for resolving coreference tend to have accuracy in the 75% range. As with many linguistic tasks, there is a tradeoff between precision and recall.
A classic problem for coreference resolution in English is the pronoun it, which has many uses. It can refer much like he and she, except that it generally refers to inanimate objects (the rules are actually more complex: animals may be any of it, he, or she; ships are traditionally she; hurricanes are usually it despite having gendered names). It can also refer to abstractions rather than beings: "He was paid minimum wage, but didn't seem to mind it." Finally, it also has pleonastic uses, which do not refer to anything specific:
- In computational linguistics, coreference resolution is a well-studied problem in discourse. To derive the correct interpretation of a text, or even to estimate the relative importance of various mentioned subjects, pronouns and other referring expressions must be connected to the right individuals. Algorithms intended to resolve coreferences commonly look first for the nearest preceding individual that is compatible with the referring expression. For example, she might attach to a preceding expression such as the woman or Anne, but not to Bill. Pronouns such as himself have much stricter constraints. Algorithms for resolving coreference tend to have accuracy in the 75% range. As with many linguistic tasks, there is a tradeoff between precision and recall.
- a. It's raining.
- b. It's really a shame.
- c. It takes a lot of work to succeed.
- d. Sometimes it's the loudest who have the most influence.
- Pleonastic uses are not considered referential, and so are not part of coreference. [1]
2015a
- (Clark & Manning, 2015) ⇒ Kevin Clark, and Christopher D. Manning. (2015). “Entity-centric Coreference Resolution with Model Stacking.” In: Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing.
- QUOTE: Coreference resolution, the task of identifying mentions in a text that refer to the same real world entity, is an important aspect of text understanding and has numerous applications (...)
The entity-centric system builds up coreference chains with agglomerative clustering: each mention starts in its own cluster and then pairs of clusters are merged each step. We train an agent to determine whether it is desirable to merge a particular pair of clusters using an imitation learning algorithm based on DAgger (...)
It begins in a start state where each mention is in a separate single-element cluster. At each step, it observes the current state s, which consists of all partially formed coreference clusters produced so far, and selects some action a which merges two existing clusters. The action will result in a new state with new candidate actions and the process is repeated. The model is entity-centric in that it builds 1407 up clusters of mentions representing entities and merges clusters if it predicts they are representing the same one.
- QUOTE: Coreference resolution, the task of identifying mentions in a text that refer to the same real world entity, is an important aspect of text understanding and has numerous applications (...)
2015b
- (Sawhney & Wang, 2015) ⇒ Kartik Sawhney, and Rebecca Wang. (2015). “Coreference Resolution.”
- QUOTE: Coreference resolution refers to the task of clustering different mentions referring to the same entity. This is particularly useful in other NLP tasks, including retrieving information about specific named entities, machine translation, among others.
2013
- (Lee et al., 2013) ⇒ Heeyoung Lee, Angel Chang, Yves Peirsman, Nathanael Chambers, Mihai Surdeanu, and Dan Jurafsky. (2013). “Deterministic Coreference Resolution based on Entity-centric, Precision-ranked Rules.” In: Computational Linguistics Journal, 39(4). doi:10.1162/COLI_a_00152
- QUOTE: Coreference resolution, the task of finding all expressions that refer to the same entity in a discourse, is important for natural language understanding tasks like summarization, question answering, and information extraction.
2012a
- (Stoyanov & Eisner, 2012) ⇒ Veselin Stoyanov, and Jason Eisner. (2012). “Easy-first Coreference Resolution.” In: Proceedings of COLING 2012.
- QUOTE: Noun phrase coreference resolution is the task of determining whether two noun phrases (NPs) refer to the same real-world entity or concept (...)
We propose a coreference resolution approach that like Raghunathan et al. (2010) aims to consider global consistency while performing fast and deterministic greedy search. Similar to Raghunathan et al. (2010), our algorithm operates by making the easy (most confident) decisions first. It builds up coreference clusters as it goes and uses the information from these clusters in the form of features to make later decisions. However, while Raghunathan et al. (2010) use hand-written rules for their system, we learn feature weights from training data.
- QUOTE: Noun phrase coreference resolution is the task of determining whether two noun phrases (NPs) refer to the same real-world entity or concept (...)
2012b
- (Björkelund & Farkas, 2012) ⇒ Anders Björkelund, and Richárd Farkas. (2012). “Data-driven Multilingual Coreference Resolution Using Resolver Stacking.” In: Joint Conference on EMNLP and CoNLL - Shared Task.
- QUOTE: We have presented a novel cluster-based coreference resolution algorithm. This algorithm was combined with conventional pair-wise resolution algorithms in a stacking approach. We applied our system to all three languages in the Shared Task, and obtained an official overall final score of 58.25 which was the second highest in the Shared Task.
2011a
- (Klenner et al., 2011) ⇒ Manfred Klenner, and Don Tuggener. (2011). “An Incremental Model for Coreference Resolution with Restrictive Antecedent Accessibility.” In: Proceedings of the Fifteenth Conference on Computational Natural Language Learning: Shared Task.
- QUOTE: As recently discussed in (Ng, 2010), the so called mention-pair model suffers from several design flaws which originate from the locally confined perspective of the model:
- Generation of (transitively) redundant pairs, as the formation of coreference sets (coreference clustering) is done after pairwise classification;
- Thereby generation of skewed training sets which lead to classifiers biased towards negative classification;
- No means to enforce global constraints such as transitivity;
- Underspecification of antecedent candidates;
- QUOTE: As recently discussed in (Ng, 2010), the so called mention-pair model suffers from several design flaws which originate from the locally confined perspective of the model:
- These problems can be remedied by an incremental entity-mention model, where candidate pairs are evaluated on the basis of the emerging coreference sets. A clustering phase on top of the pairwise classifier no longer is needed and the number of candidate pairs is reduced, since from each coreference set (be it large or small) only one mention (the most representative one) needs to be compared to a new anaphor candidate. We form a ’virtual prototype’ that collects information from all the members of each coreference set in order to maximize ’representativeness’. Constraints such as transitivity and morphological agreement can be assured by just a single comparison. If an anaphor candidate is compatible with the virtual prototype, then it is by definition compatible with all members of the coreference set.
2011b
- (Zheng et al., 2011) ⇒ Jiaping Zheng, Wendy W. Chapman, Rebecca S. Crowley, and Guergana K. Savova. (2011). “Coreference Resolution: A Review of General Methodologies and Applications in the Clinical Domain.” In: Journal of Biomedical Informatics, 44(6). doi:10.1016/j.jbi.2011.08.006
- QUOTE: Coreference resolution is the task of determining linguistic expressions that refer to the same real-world entity in natural language. For example, in the sentences “Have reviewed the electrocardiogram. It shows a wide QRS with a normal rhythm but no delta waves.” the phrases “the electrocardiogram” and “It” refer to the same entity, i.e. the electrocardiogram(...). Formally, coreference consists of two linguistic expressions- antecedent and anaphor. The anaphor is the expression whose interpretation (i.e., associating it with an either concrete or abstract real-world entity) depends on that of the other expression. The antecedent is the linguistic expression on which an anaphor depends. In the first example in Section 1, “the electrocardiogram” is the antecedent, and “It” is the anaphor. Similarly in Example 1, “significant pain in the shoulder” is the antecedent, and “his discomfort” is the anaphor. The relationship between the antecedent and the anaphor is usually “identity” - they both refer to the same entity. A broader concept of anaphora includes a pair of linguistic expressions whose relationship does not have to be identity.
These linguistic expressions, the antecedents and the anaphors, are collectively called markables in the MUC corpus. Two coreferring markables form a pair, while one or more pairs that refer to the same entity form a chain. In the ACE corpus, the linguistic expressions are called mentions, and the entities these mentions refer to are, naturally, entities. (...)
- QUOTE: Coreference resolution is the task of determining linguistic expressions that refer to the same real-world entity in natural language. For example, in the sentences “Have reviewed the electrocardiogram. It shows a wide QRS with a normal rhythm but no delta waves.” the phrases “the electrocardiogram” and “It” refer to the same entity, i.e. the electrocardiogram(...). Formally, coreference consists of two linguistic expressions- antecedent and anaphor. The anaphor is the expression whose interpretation (i.e., associating it with an either concrete or abstract real-world entity) depends on that of the other expression. The antecedent is the linguistic expression on which an anaphor depends. In the first example in Section 1, “the electrocardiogram” is the antecedent, and “It” is the anaphor. Similarly in Example 1, “significant pain in the shoulder” is the antecedent, and “his discomfort” is the anaphor. The relationship between the antecedent and the anaphor is usually “identity” - they both refer to the same entity. A broader concept of anaphora includes a pair of linguistic expressions whose relationship does not have to be identity.
2010a
- (Ng, 2010) ⇒ Vincent Ng. (2010). “Supervised Noun Phrase Coreference Research: The First Fifteen Years.” In: Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics (ACL 2010).
- QUOTE: Noun phrase (NP) coreference resolution, the task of determining which NPs in a text or dialogue refer to the same real-world entity, has been at the core of natural language processing (NLP) since the 1960s. NP coreference is related to the task of anaphora resolution, whose goal is to identify an antecedent for an anaphoric NP (...)
(...) we examine three important classes of coreference models that were developed in the past fifteen years, namely, the mention-pair model, the entity-mention model, and ranking models.
- QUOTE: Noun phrase (NP) coreference resolution, the task of determining which NPs in a text or dialogue refer to the same real-world entity, has been at the core of natural language processing (NLP) since the 1960s. NP coreference is related to the task of anaphora resolution, whose goal is to identify an antecedent for an anaphoric NP (...)
2010b
- (Cai & Strube, 2010) ⇒ Jie Cai, and Michael Strube. (2010). “End-to-end Coreference Resolution via Hypergraph Partitioning.” In: Proceedings of the 23rd International Conference on Computational Linguistics.
- QUOTE: Coreference resolution is the task of grouping mentions of entities into sets so that all mentions in one set refer to the same entity. Most recent approaches to coreference resolution divide this task into two steps: (1) a classification step which determines whether a pair of mentions is coreferent or which outputs a confidence value, and (2) a clustering step which groups mentions into entities based on the output of step 1.(...)
(...) In this paper we describe a novel approach to coreference resolution which avoids the division into two steps and instead performs a global decision in one step. We represent a document as a hypergraph, where the vertices denote mentions and the edges denote relational features between mentions. Coreference resolution is performed globally in one step by partitioning the hypergraph into subhypergraphs so that all mentions in one subhypergraph refer to the same entity.
- QUOTE: Coreference resolution is the task of grouping mentions of entities into sets so that all mentions in one set refer to the same entity. Most recent approaches to coreference resolution divide this task into two steps: (1) a classification step which determines whether a pair of mentions is coreferent or which outputs a confidence value, and (2) a clustering step which groups mentions into entities based on the output of step 1.(...)
2010c
- (Raghunathan et al., 2010) ⇒ Karthik Raghunathan, Heeyoung Lee, Sudarshan Rangarajan, Nathanael Chambers, Mihai Surdeanu, Dan Jurafsky, and Christopher Manning. (2010). “A Multi-pass Sieve for Coreference Resolution.” In: Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing.
- QUOTE: We propose an unsupervised sieve-like approach to coreference resolution that addresses these issues. The approach applies tiers of coreference models one at a time from highest to lowest precision. Each tier builds on the entity clusters constructed by previous models in the sieve, guaranteeing that stronger features are given precedence over weaker ones. Furthermore, each model’s decisions are richly informed by sharing attributes across the mentions clustered in earlier tiers. This ensures that each decision uses all of the information available at the time. We implemented all components in our approach using only deterministic models. All our components are unsupervised, in the sense that they do not require training on gold coreference links.
2009a
- (Wick et al., 2009) ⇒ Michael Wick, Aron Culotta, Khashayar Rohanimanesh, Andrew McCallum. (2009). “An Entity Based Model for Coreference Resolution.” In: Proceedings of the SIAM International Conference on Data Mining (SDM 2009).
- QUOTE: One important data-cleaning problem is coreference, which is the tasks of clustering mentions/records into real-world entities. Their are many variations of the coreference task, including web-people disambiguation 17, anaphora resolution 18, author disambiguation 19, and citation matching. In this paper we focus primarily on the anaphora resolution and citation matching tasks. However, we discuss relevant work from other areas of coreference because the techniques employed are relevant to our task
Statistical approaches to coreference resolution can be broadly placed into two categories: generative models, which model the joint probability, and discriminative models that model that conditional probability. These models can be either supervised (uses labeled coreference data for learning) or unsupervised (no labeled data is used). Our model falls into the category of discriminative and supervised.
- QUOTE: One important data-cleaning problem is coreference, which is the tasks of clustering mentions/records into real-world entities. Their are many variations of the coreference task, including web-people disambiguation 17, anaphora resolution 18, author disambiguation 19, and citation matching. In this paper we focus primarily on the anaphora resolution and citation matching tasks. However, we discuss relevant work from other areas of coreference because the techniques employed are relevant to our task
2009b
- (Stoyanov et al., 2009) ⇒ Veselin Stoyanov, Nathan Gilbert, Claire Cardie, and Ellen Riloff. (2009). “Conundrums in Noun Phrase Coreference Resolution: Making Sense of the State-of-the-art.” In: Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP: Volume 2 - Volume 2. ISBN:978-1-932432-46-6
- QUOTE: Noun phrase coreference resolution is the process of determining whether two noun phrases (NPs) refer to the same real-world entity or concept. It is related to anaphora resolution: a NP is said to be anaphoric if it depends on another NP for interpretation. Consider the following: John Hall is the new CEO. He starts on Monday.
Here, he is anaphoric because it depends on its antecedent, John Hall, for interpretation. The two NPs also corefer because each refers to the same person, JOHN HALL.
- QUOTE: Noun phrase coreference resolution is the process of determining whether two noun phrases (NPs) refer to the same real-world entity or concept. It is related to anaphora resolution: a NP is said to be anaphoric if it depends on another NP for interpretation. Consider the following:
2008a
- (Versley et al., 2008) ⇒ Yannick Versley, Simone Paolo Ponzetto, Massimo Poesio, Vladimir Eidelman, Alan Jern, Jason Smith, Xiaofeng Yang, and Alessandro Moschitti. (2008). “BART: A Modular Toolkit for Coreference Resolution.” In: Proceedings of the 46th Annual Meeting of the Association for Computational Linguistics on Human Language Technologies: Demo Session.
- QUOTE: Coreference resolution refers to the task of identifying noun phrases that refer to the same extralinguistic entity in a text. Using coreference information has been shown to be beneficial in a number of other tasks, including information extraction (McCarthy and Lehnert, 1995), question answering (Morton, 2000) and summarization (Steinberger et al., 2007)...
A number of systems that perform coreference resolution are publicly available, such as GUITAR (Steinberger et al., 2007), which handles the full coreference task, and JAVARAP (Qiu et al., 2004), which only resolves pronouns. However, literature on coreference resolution, if providing a baseline, usually uses the algorithm and feature set of Soon et al. (2001) for this purpose.
Using the built-in maximum entropy learner with feature combination, BART reaches 65.8% F-measure on MUC6 and 62.9% F-measure on MUC7 using Soon et al.’s features, outperforming JAVARAP on pronoun resolution, as well as the Soon et al. reimplementation of Uryupina (2006) ...
The BART toolkit has been developed as a tool to explore the integration of knowledge-rich features into a coreference system at the Johns Hopkins Summer Workshop 2007.
- QUOTE: Coreference resolution refers to the task of identifying noun phrases that refer to the same extralinguistic entity in a text. Using coreference information has been shown to be beneficial in a number of other tasks, including information extraction (McCarthy and Lehnert, 1995), question answering (Morton, 2000) and summarization (Steinberger et al., 2007)...
2008b
- (Yang et al., 2008) ⇒ Xiaofeng Yang, Jian Su, Jun Lang, Chew Lim Tan, Ting Liu, and Sheng Li. (2008). “An Entity-Mention Model for Coreference Resolution with Inductive Logic Programming.” In: Proceedings of ACL Conference (ACL 2008).
2008c
- (Clark and González-Brenes, 2008) ⇒ Jonathan H. Clark, José P. González-Brenes. (2008). “Coreference: Current Trends and Future Directions." CMU course on Language and Statistics II Literature Review.
- QUOTE: ... it is possible to categorize coreference models into two categories: (i) pairwise models, which are myopic in that they can only examine pairs of mentions at once, and (ii) cluster-based models, which have access to entire clusters of mentions at once, but present a difficult inference problem.
2008d
- (Nguy, 2008) ⇒ Giang Linh Nguy. (2008). “Machine Learning Approaches to Coreference Resolution.” In: Proceedings of WDS 2008, Contributed Papers, Part I. . ISBN:978-80-7378-065-4
2007a
- (Ng, 2007) ⇒ Vincent Ng. (2007). “Semantic Class Induction And Coreference Resolution.” In: Proceedings of the 45th Annual Meeting of the Association for Computational Linguistics (ACL 2007).
2007b
- (Culotta et al., 2007) ⇒ Aron Culotta, Michael Wick, Robert Hall, and Andrew McCallum. (2007). “First-Order Probabilistic Models for Coreference Resolution.” In: Proceedings of the Human Language Technology Conference of the North American Chapter of the Association of Computational Linguistics (NAACL 2007).
2007c
- (Luo, 2007) ⇒ Xiaoqiang Luo. (2007). “Coreference Or Not: A Twin Model for Coreference Resolution.” In: Proceedings of the North American Chapter of the Association for Computational Linguistics. NAACL HLT 2007.
2006
- (Nicolae & Nicolae, 2006) ⇒ Cristina Nicolae, and Gabriel Nicolae. (2006). “BestCut: A Graph Algorithm for Coreference Resolution.” In: Proceedings of the 2006 Conference on Empirical Methods in Natural Language Processing. ISBN:1-932432-73-6
2004
- (Luo et al., 2004) ⇒ Xiaoqiang Luo, Abe Ittycheriah, Hongyan Jing, Nanda Kambhatla, and Salim Roukos. (2004). “A Mention-synchronous Coreference Resolution Algorithm based on the Bell Tree.” In: Proceedings of the 42nd Annual Meeting on Association for Computational Linguistics. doi:10.3115/1218955.1218973
2003
- (McCallum & Wellner, 2003) ⇒ Andrew McCallum, and Ben Wellner. (2003). “Toward Conditional Models of Identity Uncertainty with Application to Proper Noun Coreference.” In: Proceedings of the 2003 International Conference on Information Integration on the Web.
2002
- (Ng & Cardie, 2002) ⇒ Vincent Ng, and Claire Cardie. (2002). “Improving Machine Learning Approaches to Coreference Resolution.” In: Proceedings of the 40th Annual Meeting on Association for Computational Linguistics. doi:10.3115/1073083.1073102
2001
- (Soon et al., 2001) ⇒ Wee Meng Soon, Hwee Tou Ng, and Daniel Chung Yong Lim. (2001). “A Machine Learning Approach to Coreference Resolution of Noun Phrases.” In: Computational Linguistics, Vol. 27, No. 4.
- QUOTE: A prerequisite for coreference resolution is to obtain most, if not all, of the possible markables in a raw input text. To determine the markables, a pipeline of natural language processing (NLP) modules is used, as shown in Figure 1. They consist of tokenization, sentence segmentation, morphological processing, part-of-speech tagging, noun phrase identification, named entity recognition, nested noun phrase extraction, and semantic class determination. As far as coreference resolution is concerned, the goal of these NLP modules is to determine the boundary of the markables, and to provide the necessary information about each markable for subsequent generation of features in the training examples.
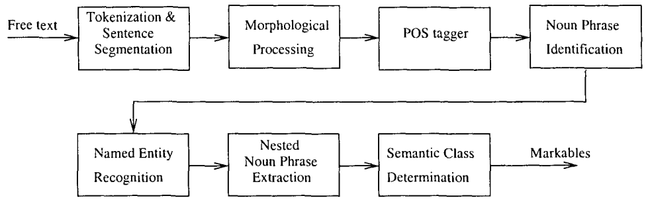
Figure 1 System architecture of natural language processing pipeline.
- QUOTE: A prerequisite for coreference resolution is to obtain most, if not all, of the possible markables in a raw input text. To determine the markables, a pipeline of natural language processing (NLP) modules is used, as shown in Figure 1. They consist of tokenization, sentence segmentation, morphological processing, part-of-speech tagging, noun phrase identification, named entity recognition, nested noun phrase extraction, and semantic class determination. As far as coreference resolution is concerned, the goal of these NLP modules is to determine the boundary of the markables, and to provide the necessary information about each markable for subsequent generation of features in the training examples.

1999a
- (Wagstaff & Cardie, 1999) ⇒ Kiri Wagstaff, Claire Cardie. (1999). “Noun Phrase Coreference as Clustering.” In: Proceedings of the Joint Conference on Empirical Methods in Natural Language Processing and Very Large Corpora (EMNLP 1999).
1999b
- (Soon et al., 1999) ⇒ Wee Meng Soon, Hwee Tou Ng, and Chung Yong Lim. (1999). “Corpus-based Learning for Noun Phrase Coreference Resolution.” In: Proceedings of Empirical Methods in Natural Language Processing and Very Large Corpora. 1999 Joint SIGDAT.