Deep Bidirectional LSTM Network
Jump to navigation
Jump to search
A Deep Bidirectional LSTM Network is a biLSTM network that is a deep neural network.
- Context:
- It can be trained by a Deep Bidirectional LSTM Network Training System (that implements a Deep Bidirectional LSTM Network Training Algorithm).
- Example(s):
- Counter-Example(s)
- See: LSTM, Artificial Neural Network, Bidirectional Recurrent Neural Network, Stacked Bidirectional and Unidirectional LSTM (SBU-LSTM) Neural Network.
References
2018a
- (Cui, Ke & Wang, 2018) ⇒ Zhiyong Cui, Ruimin Ke, and Yinhai Wang (2018). "Deep Bidirectional and Unidirectional LSTM Recurrent Neural Network for Network-wide Traffic Speed Prediction" (PDF). arXiv preprint [arXiv:1801.02143].
- QUOTE: The deep LSTM architectures are networks with several stacked LSTM hidden layers, in which the output of a LSTM hidden layer will be fed as the input into the subsequent LSTM hidden layer. This stacked layers mechanism, which can enhance the power of neural networks, is adopted in this study. As mentioned in previous sections, BDLSTMs can make use of both forward and backward dependencies. When feeding the spatial-temporal information of the traffic network to the BDLSTMs, both the spatial correlation of the speeds in different locations of the traffic network and the temporal dependencies of the speed values can be captured during the feature learning process. In this regard, the BDLSTMs are very suitable for being the first layer of a model to learn more useful information from spatial time series data. When predicting future speed values, the top layer of the architecture only needs to utilize learned features, namely the outputs from lower layers, to calculate iteratively along the forward direction and generate the predicted values. Thus, an LSTM layer, which is fit for capturing forward dependency, is a better choice to be the last (top) layer of the model.
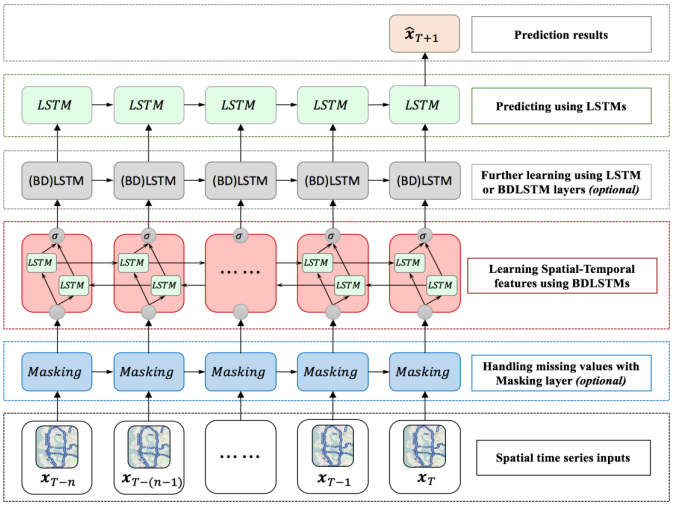
Fig. 5: SBU-LSTMs architecture necessarily consists of a BDLSTM layer and a LSTM layer. Masking layer for handling missing values and multiple LSTM or BDLSTM layers as middle layers are optional.
- QUOTE: The deep LSTM architectures are networks with several stacked LSTM hidden layers, in which the output of a LSTM hidden layer will be fed as the input into the subsequent LSTM hidden layer. This stacked layers mechanism, which can enhance the power of neural networks, is adopted in this study. As mentioned in previous sections, BDLSTMs can make use of both forward and backward dependencies. When feeding the spatial-temporal information of the traffic network to the BDLSTMs, both the spatial correlation of the speeds in different locations of the traffic network and the temporal dependencies of the speed values can be captured during the feature learning process. In this regard, the BDLSTMs are very suitable for being the first layer of a model to learn more useful information from spatial time series data. When predicting future speed values, the top layer of the architecture only needs to utilize learned features, namely the outputs from lower layers, to calculate iteratively along the forward direction and generate the predicted values. Thus, an LSTM layer, which is fit for capturing forward dependency, is a better choice to be the last (top) layer of the model.

2018b
- (Peters et al., 2018) ⇒ Matthew E. Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer (2018). "Deep contextualized word representations". arXiv preprint arXiv:1802.05365.
- QUOTE: ELMo representations are deep, in the sense that they are a function of all of the internal layers of the biLM. More specifically, we learn a linear combination of the vectors stacked above each input word for each end task, which markedly improves performance over just using the top LSTM layer. Combining the internal states in this manner allows for very rich word representations. Using intrinsic evaluations, we show that the higher-level LSTM states capture context-dependent aspects of word meaning (e.g., they can be used without modification to perform well on supervised word sense disambiguation tasks) while lower level states model aspects of syntax (e.g., they can be used to do part-of-speech tagging).
2018c
- (Kim, 2018) ⇒ Kyungna Kim (2018). "Arrhythmia Classification in Multi-Channel ECG Signals Using Deep Neural Networks".
- QUOTE:To utilize both the pattern recognition afforded by deep CNNs and the temporal learning ability of LSTMs, we also train an additional architecture that combines them into a single model. We begin with a stacked LSTM to extract temporal structures from the data, and instead of feeding the unrolled hidden state into another LSTM layer, we feed it as input into a (deep) CNN to extract localized features. In the combined model, we begin by feeding the data into a 2-layer LSTM. The output of the final LSTM layer is treated as a one-dimensional image of size (100 × 600), and fed into a CNN to extract localized features. We also train a similar architecture with a bidirectional 2-layer LSTM, where the image is of size (200×600). Full high-level architecture of our combined network is shown in figure 3.4.
- QUOTE:To utilize both the pattern recognition afforded by deep CNNs and the temporal learning ability of LSTMs, we also train an additional architecture that combines them into a single model. We begin with a stacked LSTM to extract temporal structures from the data, and instead of feeding the unrolled hidden state into another LSTM layer, we feed it as input into a (deep) CNN to extract localized features. In the combined model, we begin by feeding the data into a 2-layer LSTM. The output of the final LSTM layer is treated as a one-dimensional image of size (100 × 600), and fed into a CNN to extract localized features. We also train a similar architecture with a bidirectional 2-layer LSTM, where the image is of size (200×600). Full high-level architecture of our combined network is shown in figure 3.4.
