Inductive Reasoning Task
An Inductive Reasoning Task is a reasoning task that requires an inductive argument (based on inductive operations on facts/evidence).
- AKA: Inductive Logic.
- Context:
- Input: a Fact Set.
- output: an Inductive Argument.
- … Reasoning Process ...
- It can be solved by an Inductive Reasoning System that applies an Inductive Reasoning Algorithm.
- It can produce a Predictive Function.
- Its conclusions can change based on new information. (See: Non-Monotonic Reasoning)
- It can involve the creation of a Test Set (to stress-test the argument).
- It can make use of a Generalization operation.
- Example:
- Counter-Example(s):
- See: Learning Task; Statistical Inference; Abduction; Bayesian Statistics; Classification; Learning from Analogy; No-Free Lunch Theorems; Nonmonotonic Logic, Connections Between Inductive Inference and Machine Learning.
References
2018a
- (Wikipedia, 2018) ⇒ https://en.wikipedia.org/wiki/Inductive_reasoning Retrieved:2018-6-24.
- Inductive reasoning (as opposed to deductive reasoning or abductive reasoning) is a method of reasoning in which the premises are viewed as supplying some evidence for the truth of the conclusion. While the conclusion of a deductive argument is certain, the truth of the conclusion of an inductive argument may be probable, based upon the evidence given. Many dictionaries define inductive reasoning as the derivation of general principles from specific observations, though some sources disagree with this usage.
The philosophical definition of inductive reasoning is more nuanced than simple progression from particular/individual instances to broader generalizations. Rather, the premises of an inductive logical argument indicate some degree of support (inductive probability) for the conclusion but do not entail it; that is, they suggest
truth but do not ensure it. In this manner, there is the possibility of moving from general statements to individual instances (for example, statistical syllogisms, discussed below).
- Inductive reasoning (as opposed to deductive reasoning or abductive reasoning) is a method of reasoning in which the premises are viewed as supplying some evidence for the truth of the conclusion. While the conclusion of a deductive argument is certain, the truth of the conclusion of an inductive argument may be probable, based upon the evidence given. Many dictionaries define inductive reasoning as the derivation of general principles from specific observations, though some sources disagree with this usage.
2018b
- (Muhamma, 2018) ⇒ http://www.personal.kent.edu/~rmuhamma/Algorithms/MyAlgorithms/DeductInduct.htm Retrieved:2018-6-24.
- QUOTE: ... In a conclusion, when we use deduction we reason from general principles to specific cases, as in applying a mathematical theorem to a particular problem or in citing a law of physics to predict the outcome of an experiment.
An Inductive reasoning works the other way around, it works from observation (or observations) works toward generalizations and theories. This is also called a “bottom-up” approach. Inductive reason starts from specific observations (or measurement if you are mathematician or more precisely statistician), look for patterns (or no patterns), regularities (or irregularities), formulate hypothesis that we could work with and finally ended up developing general theories or drawing conclusion. Note that is how Newton reached to “Law of Gravitation” from "apple and his head” observation"). In a conclusion, when we use Induction we observe a number of specific instances and from them infer a general principle or law.

These two methods are “sense” very different in nature when use in conducting researches other than being top-down and bottom-up. Inductive reasoning is open-ended and exploratory especially at the beginning. On the other hand, deductive reasoning is narrow in nature and is concerned with testing or confirming hypothesis.
- QUOTE: ... In a conclusion, when we use deduction we reason from general principles to specific cases, as in applying a mathematical theorem to a particular problem or in citing a law of physics to predict the outcome of an experiment.

2017a
- (Jain & Stephan, 2017) ⇒ Sanjay Jain & Frank Stephan. (2017). "Inductive Inference". In: Sammut & Webb, 2017.
- QUOTE: Inductive inference is a theoretical framework to model learning in the limit. The typical scenario is that the learner reads successively datum [math]\displaystyle{ d_0, d_1, d_2,\cdots }[/math] about a concept and outputs in parallel hypotheses [math]\displaystyle{ e_0, e_1, e_2, \cdots }[/math] such that each hypothesis [math]\displaystyle{ e_n }[/math] is based on the preceding data [math]\displaystyle{ d_0, d_1, \cdots, d_{n−1} }[/math]. The hypotheses are expected to converge to a description for the data observed; here the constraints on how the convergence has to happen depend on the learning paradigm considered. In the most basic case, almost all [math]\displaystyle{ e_n }[/math] have to be the same correct index e, which correctly explains the target concept. The learner might have some preknowledge of what the concept might be, that is, there is some class [math]\displaystyle{ \mathcal{C} }[/math] of possible target concepts – the learner has only to find out which of the concepts in [math]\displaystyle{ \mathcal{C} }[/math] is the target concept; on the other hand, the learner has to be able to learn every concept which is in the class [math]\displaystyle{ \mathcal{C} }[/math].
2017b
- (Case & Jain, 2017) ⇒ John Case & Sanjay Jain (2017) "Connections Between Inductive Inference and Machine Learning". In: Sammut & Webb, 2017.
- QUOTE: ... It is typical in applied machine learning to present to a learner whatever data one has and to obtain one corresponding program hopefully for predicting these data and future data. In inductive inference the case where only one program is output is called one-shot learning. More typically, in inductive inference, one allows for mind changes, i.e., for a succession of output programs, as one receives successively more input data, with the later programs hopefully eventually being useful for predictions. Typically, one does not get success on one’s first conjecture output program, but, rather, one may achieve success eventually or, as it is said, in the limit after some sequence of trial and error. It is helpful at this juncture to present a problem for which this latter approach makes more sense than the one-shot approach.
2009a
- WordNet.
- generalization: reasoning from detailed facts to general principles
2009b
- http://en.wiktionary.org/wiki/inductive_reasoning
- The process of making inferences based upon observed patterns, or simple repetition. Often used in reference to predictions about will happen or …
2009c
- http://www.chass.ncsu.edu/langure/documents/modules/module_9/Glossary.doc
- The process of reasoning in which the premises of an argument support the conclusion but do not ensure it. …
2009d
- http://www.utexas.edu/academic/diia/assessment/iar/glossary.php
- a logic model in which general principles are developed from the information gathered.
2009e
- http://www.numbernut.com/glossary/i.shtml
- Making a generalization from specific cases; used to formulate a general rule after examining a pattern.
2009f
- http://clopinet.com/isabelle/Projects/ETH/Exam_Questions.html
- Inference refers to the ability of a learning system, namely going from the "particular" (the examples) to the "general" (the predictive model). In the best of all worlds, we would not need to worry about model selection. Inference would be performed in a single step: we input training examples into a big black box containing all models, hyper-parameters, and parameters; outcomes the best possible trained model. In practice, we often use 2 levels of inference: we split the training data into a training set and a validation set. The training set serves the trains at the lower level (adjust the parameters of each model); the validation set serves to train at the higher level (select the model.) Nothing prevents us for using more than 2 levels. However, the price to pay will be to get smaller data sets to train with at each level.
2008
- Vladimir N. Vapnik. (2000). “COLT interview. http://www.learningtheory.org/index.php?view=article&id=9
- My current research interest is to develop advanced models of empirical inference. I think that the problem of machine learning is not just a technical problem. It is a general problem of philosophy of empirical inference. One of the ways for inference is induction. The main philosophy of inference developed in the past strongly connected the empirical inference to the inductive learning process. I believe that induction is a rather restrictive model of learning and I am trying to develop more advanced models. First, I am trying to develop non-inductive methods of inference, such as transductive inference, selective inference, and many other options. Second, I am trying to introduce non-classical ways of inference.
2000a
- (Mooney, 2000) ⇒ Raymond J. Mooney. (2000). "Integrating abduction and induction in machine learning". In: Abduction and Induction (pp. 181-191). Springer, Dordrecht.
- QUOTE: Abduction is the process of inferring cause from effect or constructing explanations for observed events and is central to tasks such as diagnosis and plan recognition. Induction is the process of inferring general rules from specific data and is the primary task of machine learning. An important issue is how these two reasoning processes can be integrated, or how abduction can aid machine learning and how machine learning can acquire abductive theories.
(...)
Precise definitions for abduction and induction are still somewhat controversial. In order to be concrete, I will generally assume that abduction and induction are both defined in the following general logical manner.
- Given: Background knowledge, B, and observations (data), O, both represented as sets of formulae in first-order predicate calculus where O is restricted to ground formulae.
- Find: An hypothesis H (also a set of logical formulae) such that [math]\displaystyle{ B\cup H \nvdash \perp }[/math] and [math]\displaystyle{ B \cup H \vdash O }[/math].
- QUOTE: Abduction is the process of inferring cause from effect or constructing explanations for observed events and is central to tasks such as diagnosis and plan recognition. Induction is the process of inferring general rules from specific data and is the primary task of machine learning. An important issue is how these two reasoning processes can be integrated, or how abduction can aid machine learning and how machine learning can acquire abductive theories.
- In abduction, H is generally restricted to a set of atomic ground or existentially quantified formulae (called assumptions) and B is generally quite large relative to H. On the other hand, in induction, H generally consists of universally quantified Horn clauses (called a theory or knowledge base), and B is relatively small and may even be empty. In both cases, following Occam's Razor, it is preferred that H be kept as small and simple as possible.
2000b
- (Haverty et al., 2000) ⇒ Haverty, L. A., Koedinger, K. R., Klahr, D., & Alibali, M. W. (2000). "Solving inductive reasoning problems in mathematics: Not-so-trivial pursuit". Cognitive Science, 24(2), 249-298.
- QUOTE: Inductive reasoning is defined as the process of inferring a general rule by observation and analysis of specific instances (Polya, 1945) (...)
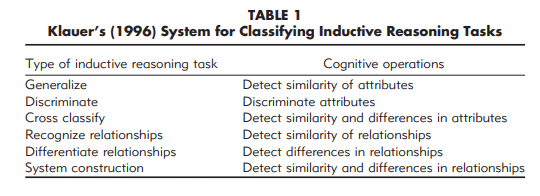 .
.
- QUOTE: Inductive reasoning is defined as the process of inferring a general rule by observation and analysis of specific instances (Polya, 1945) (...)
